I'm Julien, freelance data engineer based in Geneva 🇨🇭.
Every week, I research and share ideas about the data engineering craft.
Not subscribed yet?
👨🏽💻 echo {YOUR_INBOX} >>
Improving the user interface is essential for broader Iceberg adoption, particularly for smaller teams.
Currently, Iceberg is largely JVM-oriented: apache/iceberg repo is a Java reference implementation that includes modules for Spark, Flink, Hive, and Pig.
Other implementations extend Iceberg’s compatibility beyond the JVM:
With many teams relying on Python for their data pipelines, PyIceberg has strong potential to make Iceberg accessible to a broader audience.
In this post, co-written with Kevin, a main contributor to the library, we provide an overview of PyIceberg’s current capabilities.
We compare its features with Spark+Iceberg across key aspects: catalog compatibility, file system compatibility, read/write operations, and table management.
Library Overview
PyIceberg is currently at version 0.7.1, and the library is evolving rapidly.
As with any Python package, getting started with PyIceberg is straightforward: run pip install pyiceberg, configure your catalog, and you’re ready to go.
Now, let’s examine PyIceberg’s current capabilities and compare them to using Iceberg with Spark.
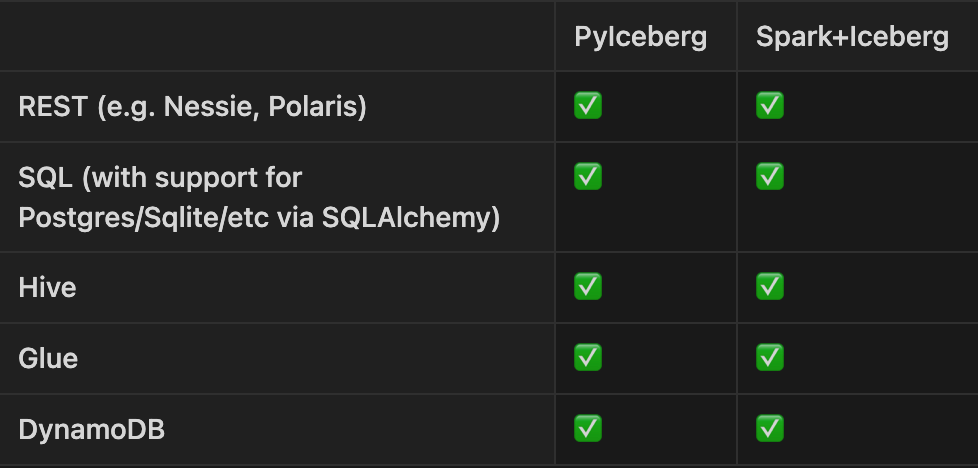
Catalogs
PyIceberg already supports a full range of catalogs.
Catalogs can be configured via env vars or a ~/.pyiceberg.yaml configuration file:
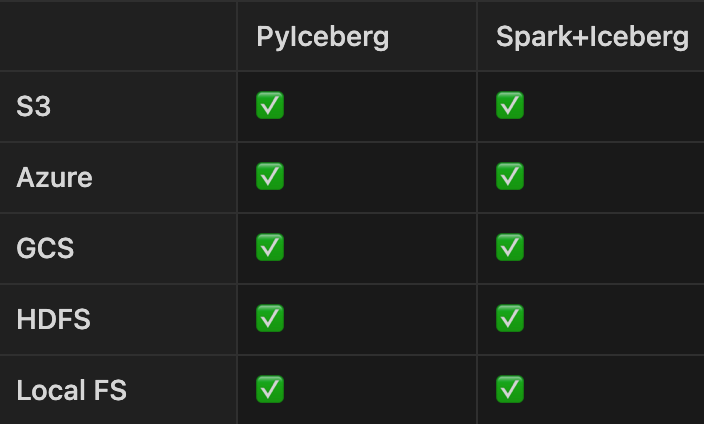
Interacting with Iceberg primarily involves reading and writing to a file system.
Therefore, compatibility with file systems is essential for PyIceberg:
Reading with PyIceberg
PyIceberg reads data using the scan() function, which retrieves information in Arrow format.
This enables you to use any Arrow-compatible engine to process the data:
iceberg_table.scan(
row_filter=EqualTo("partition_column", partition_id)
).to_arrow()
duckdb.sql(f"""
SELECT *
FROM iceberg_table
"""
# note row_filter = f"partition_column == {partition_id}" would work as # well
PyIceberg offers a variety of operators to help you construct your own filters, such as And/Or, EqualTo, GreaterThan, and more.
For more advanced filtering, the data should first be loaded into the engine, where filters can be implemented.
Read Limitations
Filter pushdown
Spark can fully use Iceberg’s metadata to push down predicates to the metadata, file, or data (row group) level.
PyIceberg has limited support for filter pushdowns.
It can use Iceberg’s metadata to filter data files based on the table’s layout and also supports file-level and data-level pushdowns.
However, the entire file is read into memory in some cases before applying a filter.
Iceberg supports two write modes: Copy-On-Write and Merge-On-Read.
In Merge-On-Read mode, deleted rows are stored in separate “delete files,” requiring the reader to merge data and delete files before returning results.
Delete files can be encoded in two ways: positional delete or equality delete.
Currently, PyIceberg only supports reading position delete files.
Reading a table containing equality delete files will result in an error.
PyIceberg currently supports only Copy-On-Write deletes, which means that data files are rewritten without the filtered rows, and no delete files are created.
This approach can slow down writes when multiple files need to be rewritten, making frequent, small, concurrent updates at the row level less efficient.
In Iceberg’s Merge-On-Read mode, deleted rows are stored in separate ‘delete files,’ leaving the reader to merge data and delete files before returning results.
This approach speeds up writes but can slow down reads.
Currently, PyIceberg does not handle retries natively.
Writing to sorted table
While Iceberg supports table sorting defined at the table level, PyIceberg currently doesn't support writing to such tables.
Partitioned writes
Currently, PyIceberg supports partitioned writes for IdentityTransform and TimeTransform (Year, Month, Day, Hour) partitions. However, it lacks support for more advanced partitioning methods:
Bucket partitioning
This method uses a hash function to divide data into a specified number of buckets.
The hash takes one or several columns as input and partitions data by hashing values into a predetermined number of buckets.
Truncate partitioning
This partition transform truncates the values of a specific column to a set width.
Bloom filtering
Bloom filters are probabilistic data structures that test if an element is part of a set. They may return false positives (indicating an element is in the set when it’s not) but never false negatives (ensuring certainty when an element is not in the set).
These filters help readers and writers reduce the amount of data scanned, but Pyiceberg does not yet support them.
Table Management
Table management refers to a set of maintenance operations that should be performed to improve a table's query performance.
None of them is directly supported in PyIceberg for now:
Each new snapshot generates a new metadata file. With frequent writes, the number of files can grow excessively. This operation deletes all metadata files prior to a specified snapshot.
Kevin is an Apache Iceberg Committer and previously built an Iceberg-centric lakehouse at Stripe. He contributes to open-source projects across the data ecosystem and specializes in Python-centric Iceberg data lakes. He has been partnering with companies to adopt and migrate to Iceberg-powered data lakes that work seamlessly with multiple engines and vendors.
If you’d like to chat or explore how he can support your data journey, feel free to reach out!
Building a data stack is hard—too many moving pieces, too little time.
That’s where Boring Data comes in.
I’ve created a data stack onboarding package that combines ready-to-use templates with hand-on workshops, empowering your team to quickly and confidently build your stack.
Interested?
Check out boringdata.io or reply to this email—I’d be happy to walk you through our templates and workshops.
I recently started working with iceberg, unfortunately compared to Delta Lake the documention was lacking, just trying to go about setting up and installing a Catalog was super unclear.











I recently started working with iceberg, unfortunately compared to Delta Lake the documention was lacking, just trying to go about setting up and installing a Catalog was super unclear.
Thanks for sharing this! Your work is essential to community