I'm Julien, freelance data engineer based in Geneva 🇨🇭.
(Almost 🙃) every week, I research and share ideas about the data engineering craft.
Not subscribed yet?
👨🏽💻 echo {YOUR_INBOX} >>
In this week’s newsletter, I want to share a small experiment I’ve been running over the past few days.
Fifteen days ago, after the release of the new BlueSky API, developers like Jake began building apps on top of it.
Both gathered BlueSky data into a bucket and exposed it directly to users.
I was immediately intrigued by their approach to data distribution: they shared a single URL pointing to a publicly hosted DuckDB file, and that was it.
So, I decided to create my version with a slight twist—it’s built on top of Iceberg.
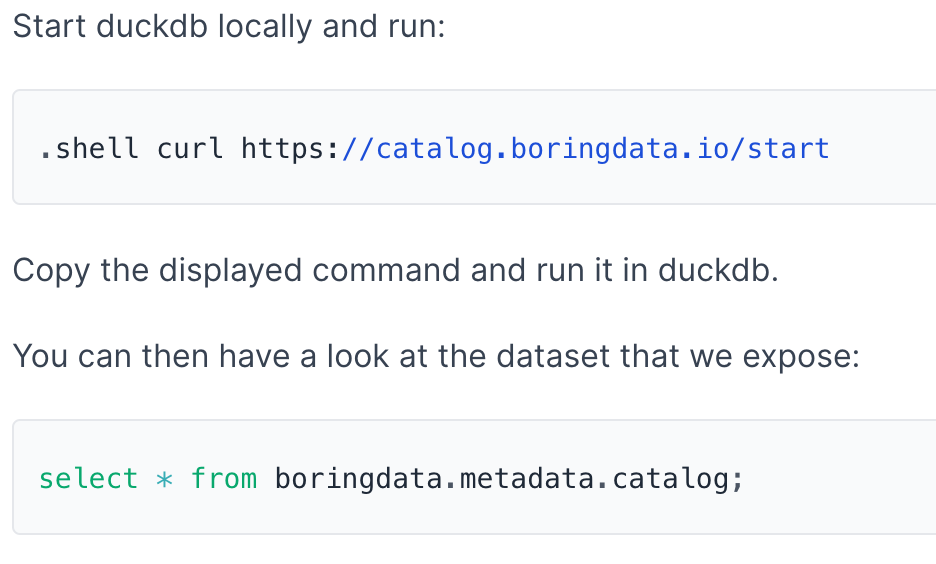
You can check the current status of this experiment here:
The idea behind this project is to distribute data—for free!
How is that even possible?
Simple: Cloudflare’s R2 buckets don’t charge for egress:
Exposing data stored on R2 only costs the storage price: $0.015 per GB/month.
Okay, so the data will be stored in Parquet files on R2, but how do we make them easily queryable for users?
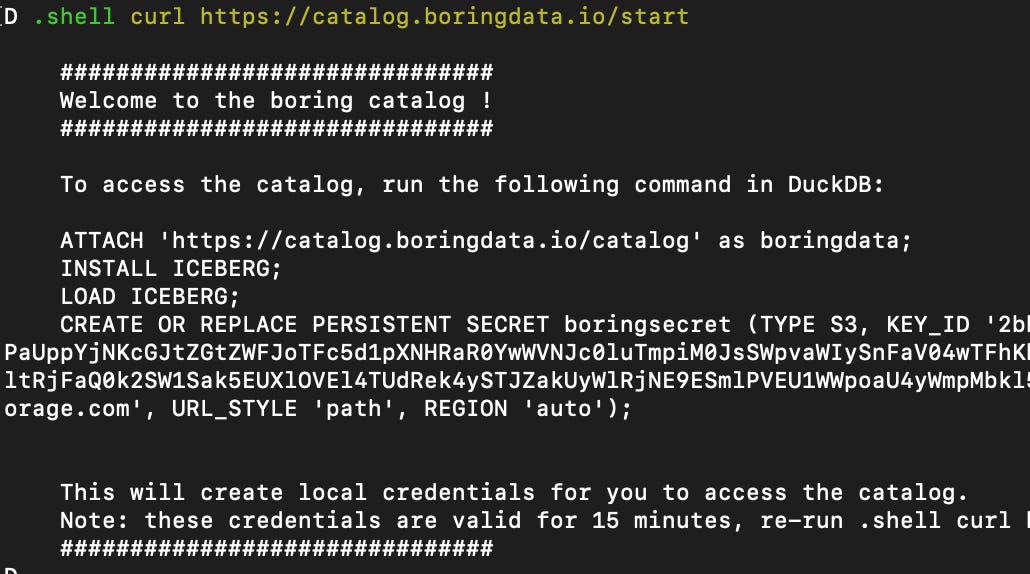
The idea is to use DuckDB’s ATTACH command:
This allows a remotely stored DuckDB database to be accessed directly within the user’s DuckDB session.
I created a DuckDB database in my R2 bucket, which contains:
A catalog: Listing all the available datasets.
Views + Table pointing to Iceberg tables
A simple trick to hide the very long path/to/metadata.json to the user
When the user queries the view, an iceberg_scan() operation is performed under the hood.
I currently have only one table containing the famous taxi dataset partitioned by month.
I’ve ingested several months of data, and the table now has approximately 1.5 billion rows.
When querying the taxi table, DuckDB can be quite slow, even though the table is partitioned by month.
This is likely because the DuckDB connector for Iceberg has not yet been fully optimized.
To overcome this, you can use PyIceberg directly, which provides much better performance (see below).
Architecture
This diagram displays the architecture I used:
Let’s explore each component.
Glue Catalog
I use Glue as the catalog for this project.
The tables are created via Terraform and point to the R2 bucket (R2 has an S3 API):
Data is then ingested via PyIceberg in append mode:
Using Glue with a non-S3 bucket means losing many built-in maintenance features.
While it’s not the ideal choice, it was the quickest solution to set up for this project.
R2 Auth Refresh
We have a public R2 bucket exposing a DuckDB file via a URL, along with Parquet files and Iceberg metadata.
Although the bucket is public, users must authenticate when querying the Parquet files via Iceberg (globing).
To address this, I generate temporary credentials that users can configure locally as a DuckDB SECRET or in their PyIceberg catalog setup.
The .shell command simply displays the temporary credentials needed to log the user in.
These credentials are refreshed by a Lambda running every 15 minutes.
This is, however, cumbersome.
Ideally, I would like the user to run a single ATTACH {url} statement, but SECRETs cannot be persisted in a DuckDB database.
Metadata Refresh
As you may have noticed, the DuckDB tables explicitly point to the latest tables’ metadata.json file.
CREATE TABLE iceberg_tablase AS SELECT * FROM iceberg_scan("s3://bucket_name/path/to/metadata_file.json")
This is because there is currently no DuckDB Iceberg → Glue integration, which means DuckDB cannot automatically reference the latest metadata.json file.
To overcome this, a Lambda function runs every 15 minutes to fetch the latest metadata.json file and update the DuckDB tables.
Updating the metadata manually is far from ideal, but it’s the best way to proceed, given the current state of the DuckDB Iceberg integration.
Dashboard
What’s cool with Iceberg is that metadata are available “for free” without having to query the table.
I created a small evidence dashboard exposing these metadata.
It displays:
• The first 100 lines of the dataset
• A history of all the commits made to the tables, along with a line chart showing table size (rows and GB)
This dashboard is refreshed by the same Lambda function that updates the metadata.
Evidence automatically generates a static website: by simply placing the built in the same public bucket, I can expose the front end here for free as well!
Beyond DuckDB
Yes, DuckDB is one way to access the data, but the beauty of Iceberg lies in its interoperability.
Let’s explore alternative ways to access the data:
PyIceberg
I’ve provided some files in the bucket to make the setup of PyIceberg static tables super easy:
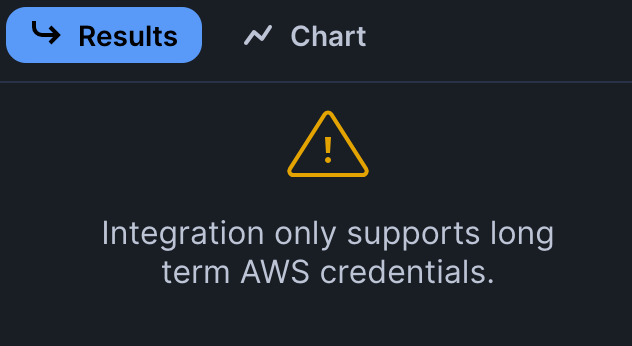
I tried to integrate with Snowflake, but the EXTERNAL VOLUME integration only supports long-term credentials, which isn’t ideal for this project.
However, using my long-term credentials, I was able to create an external Iceberg table in Snowflake that pointed directly to the metadata.json file.
Final words
This method of distributing data really clicked with me.
I love the integration model, similar to what the Snowflake Marketplace offers:
• The provider pays for storage.
• The consumer pays for compute.
Doing this with Iceberg unlocks many use cases where the data provider directly offers access to its metadata.
Imagine querying data from services like Stripe, LinkedIn, Notion, or any other SaaS platform this way.
It opens up a world of possibilities by eliminating the hassle of integrating APIs:
SELECT *
FROM stripe
LEFT JOIN hubspot
We’re still in the early stages of Iceberg integrations, and the whole ecosystem is being built.
And the recent release of S3 Tables will only accelerate this movement.
Building a data stack is hard—too many moving pieces, too little time.
That’s where Boring Data comes in.
I’ve created a data stack onboarding package that combines ready-to-use templates with hand-on workshops, empowering your team to quickly and confidently build your stack.
Interested?
Check out boringdata.io or reply to this email—I’d be happy to walk you through our templates and workshops.
Great project! It introduces me to a couple technologies I don't get to try out in my day job.
Because of the lack of predicate pushdown, would you consider connecting to the iceberg table with spark docker container? I think you can specify a directory as your 'catalog'. I feel like the overhead of spinning up a spark session is worth it because of how much less data needs to be read with each subsequent query.
On the other hand, if data transfer is free, you're not paying extra to scan more rows. It still requires more compute though.
Very cool - love the example. In my mind the complexity is still with the catalog and managing that across the different compute engines. It seems we're ending up in a world where maybe there's a single "write" catalog and then a variety of "read" catalogs that are copies of the write.

















Great project! It introduces me to a couple technologies I don't get to try out in my day job.
Because of the lack of predicate pushdown, would you consider connecting to the iceberg table with spark docker container? I think you can specify a directory as your 'catalog'. I feel like the overhead of spinning up a spark session is worth it because of how much less data needs to be read with each subsequent query.
On the other hand, if data transfer is free, you're not paying extra to scan more rows. It still requires more compute though.
Very cool - love the example. In my mind the complexity is still with the catalog and managing that across the different compute engines. It seems we're ending up in a world where maybe there's a single "write" catalog and then a variety of "read" catalogs that are copies of the write.