
AI SQL functions + Iceberg
Ju Data Engineering Weekly - Ep 68

There is no better place than a warehouse to provide an LLM interface.
Data is there.
Compute is there.
Access control is there.
There's only one catch: you need an additional ETL to move your data into the warehouse.
Fortunately, we now have Iceberg.
Let's explore how Iceberg is changing how we consume and use warehouses:
Not as a data pipeline sink anymore…
But as an LLM-powered cloud function.
Snowflake LLM interface
This post went crazy on Linkedin:

Since then, I've discovered SQL AI functions, and I think SQL should probably replace (or at least complete) “requests” in 2023+.
Chatbots are great for one-shot interactions.
APIs work well for workflow automation.
But SQL makes everything easier for data-intensive applications.
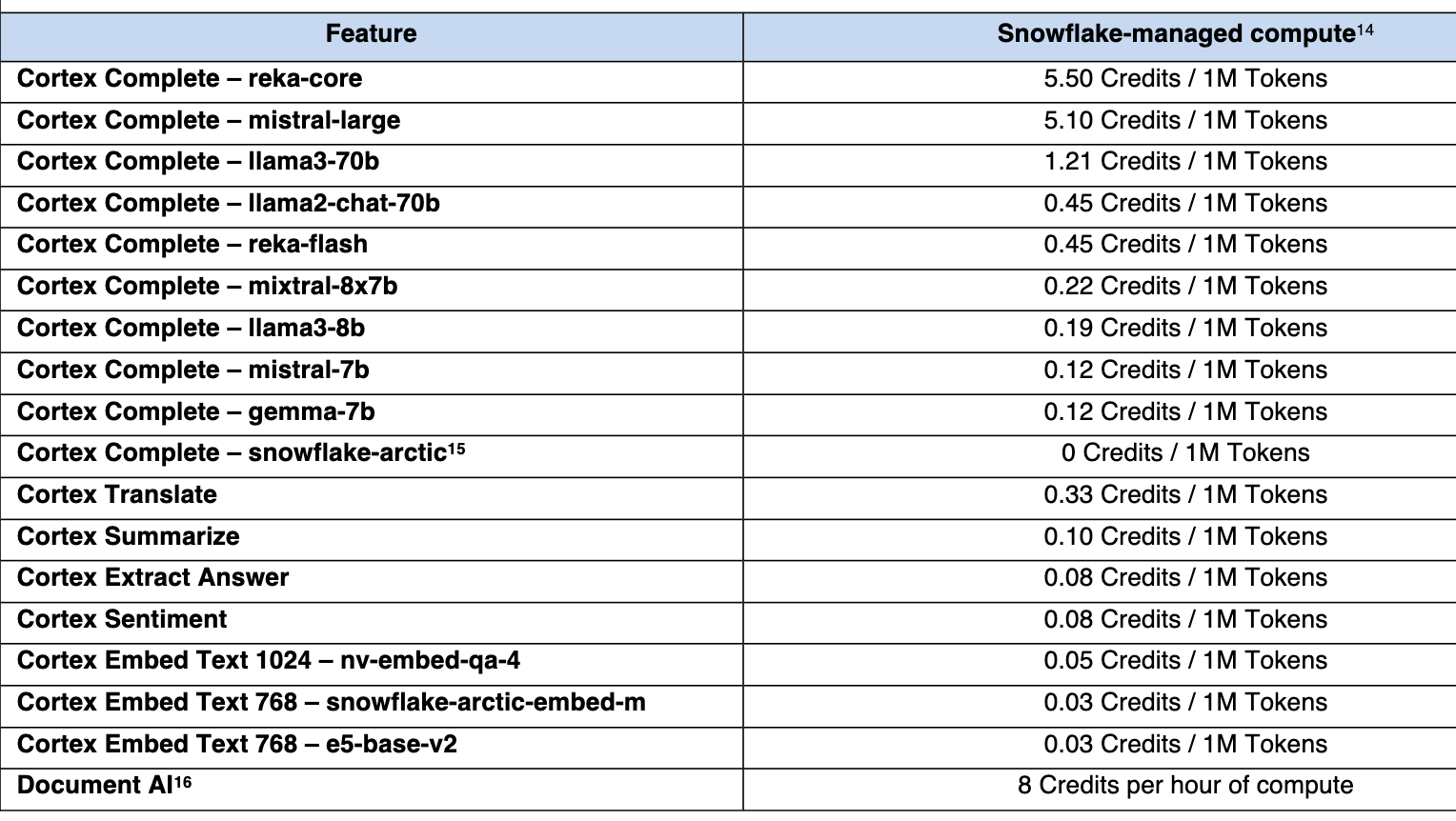
Snowflake provides access to LLM out of the box via their SQL function:

Imagine you have a table of customer reviews you want to classify.
Instead of sending them batch by batch to OpenAI API, you do it via a single SQL query:
SELECT quote,
SNOWFLAKE.CORTEX.COMPLETE(<model_name>, <your_prompt>)
FROM quote_tableThis is super powerful as you get all the advantages of having LLM living with the data:
Quickly A/B test various prompts and models:
SELECT quote,
SNOWFLAKE.CORTEX.COMPLETE(<model_1>, <prompt_A>) as output_p_A_m_1
SNOWFLAKE.CORTEX.COMPLETE(<model_2>, <prompt_A>) as output_p_A_m_2,
SNOWFLAKE.CORTEX.COMPLETE(<model_1>, <prompt_B>) as output_p_B_m_1,
SNOWFLAKE.CORTEX.COMPLETE(<model_2>, <prompt_B>) as output_p_B_m_2
FROM quote_tableSnowflake has a bunch of models available:

Add more contextual information
SELECT q.quote,
SNOWFLAKE.CORTEX.COMPLETE(<model_name>, concat(<prompt_A>, c.context))
FROM quote_table as q
LEFT JOIN context_table as c
on q.date = c.dateBuild complex transformation workflows as we are used to doing with dbt.

Monitor/update/backfill easily
I conducted a test with a table containing quotes, where I prompted Llama3 to identify the author and original book and return the results in JSON format.
SELECT quote,
SNOWFLAKE.CORTEX.COMPLETE(
'llama3-8b',
concat(
'Extract author, book and character of the following <quote>',
quote,
'</quote>. Return only a json with the following format {author: <author>, book: <book>, character: <character>}. Return only JSON, no verbose text.'
)
) as author
FROM QUOTES;I processed 26k records within 10 minutes (!) using an X-small warehouse.
43 seconds per quote is quite lengthy.
I’ll need to investigate further to understand the reasons why.

These 25K records are the equivalent of 600K tokens, so it cost me only 0.11 credits (~0.3$).
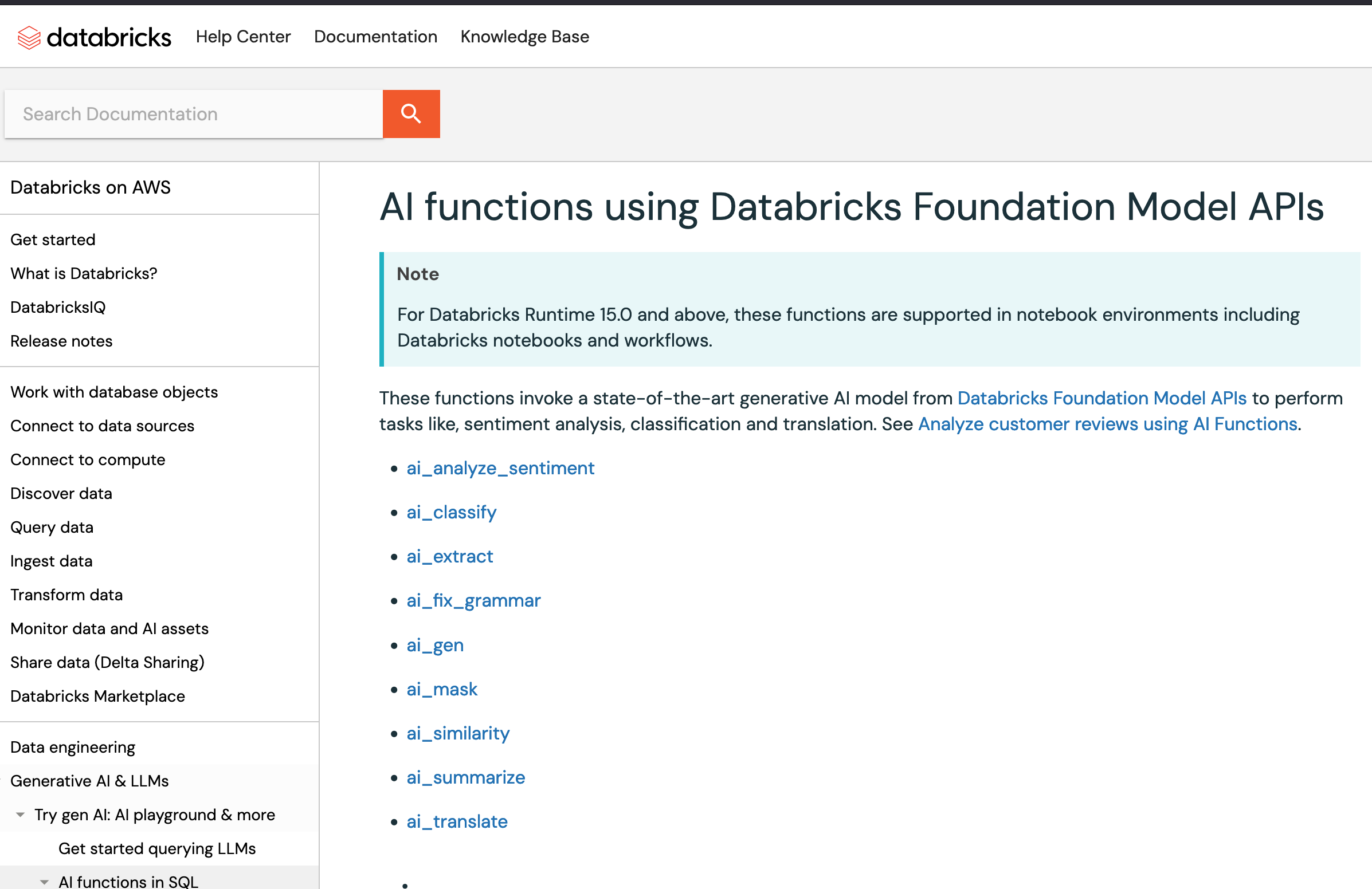
Note that these LLM SQL functions also exist in Databricks and will probably be available everywhere soon.
SQL AI + Iceberg
As mentioned above, WH has everything necessary to welcome AI: data, compute, and governance.
There is only one catch: you need to get the data there.
Traditionally, this is cumbersome as you need first to build and maintain an additional ETL.
But that's changing now with Iceberg.
If you need a recap’ on Iceberg →

Iceberg allows you to instantly expose data stored in a data lake to Snowflake, Databricks, or any other engine without copying it.
In my test case, I built an Iceberg table containing my quotes in S3 (with a Glue Catalog).

After building the catalog integration with Snowflake, I was able to apply LLM functions directly to my raw data living in S3:

Once Snowflake computes data, you want to return them to Iceberg for further downstream processing by other engines.
The only limitation is that Snowflake cannot write to an external catalog for now.

One solution is to write back to Iceberg with Snowflake's catalog (and therefore manage two catalogs: Glue + Snowflake).
In this case, the SQL looks like the following:

The data are read and written from S3 to S3; nothing stays in Snowflake.
I find this solution super elegant because:
You can easily switch if another provider is better (better model and/or lower price).
Pre-processing can be done with any cheaper engine: you choose an engine for its strength.
With Iceberg, the gravity of the stack shifts from the warehouse to the lake.
This offers a new way to think about our warehouse.
From a place to centralize the data to an ephemeral cloud function.
The next question is: how can workflows be orchestrated in this paradigm?
Be on the lookout for more on this in my next post.
-Ju

I would be grateful if you could help me to improve this newsletter. Don’t hesitate to share with me what you liked/disliked and the topic you would like to be tackled.
P.S. You can reply to this email; it will get to me.
Very well put!