

Bonjour!
I'm Julien, freelance data engineer based in Geneva 🇨🇭.
Every week, I research and share ideas about the data engineering craft.
Not subscribed yet?
I’ve been using AWS Step Functions extensively in my recent projects.
A few years ago, I tried it but was quite disappointed.
Since then, the service has significantly improved, and I must say it’s now one of my top AWS services.
In this week’s article, I’ll share what I’ve learned and what I appreciate—and find challenging—about it

Step function
Step Functions is an orchestrator service.
Users can drag and drop blocks to build orchestration flows.
Blocks (called “States”) are of 2 types:
Actions = Call to an AWS service. You can trigger almost any AWS action: run a Lambda, start an ECS task, query DynamoDB, access S3 etc. Each block can be dragged to the interface and configured right there.
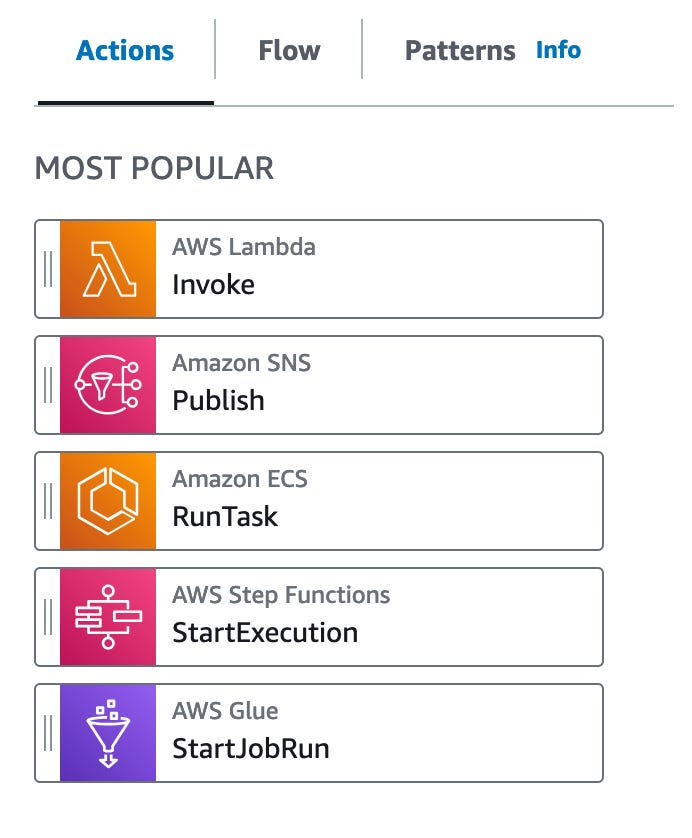
Actions States Flow = Blocks to orchestrate flow: if conditions / pass / wait / map

Flow States

Additionally, all executions are tracked, making it easy to understand, debug, and correct failing runs.
In the execution history window, you can access each state's input and output of a past execution and the timeline of events.

Nice features
Apart from being able to build workflows within the interface quickly, I appreciated the following features:
Timeout and retries
They made it easy to catch errors and task timeouts and handle retries.
When configuring a state, you pick an error

And simply select the retry mechanism:

This works particularly well when interacting with an external API or catching Lambda timeouts.
Debugging
That was the main pain point of Step Functions when I tried it initially: it took a lot of time to build because it was impossible to debug.
They have changed that, and now users can test each block individually with custom input.

This helps a lot and speeds up the development of workflows.
Wait for callback
This is a feature I love: blocks have a “wait for callback” option.

When “wait for callback” is selected, Step Functions adds a token to the payload and waits for a response.
The state can wait for up to one year, and since you’re charged per state transition (for standard workflows), waiting essentially incurs no cost.
I have used this feature for the following use cases:
Waiting for a user response: Send an email containing a URL that asks the user for validation. When the user clicks the link, the Step Function task continues.
Asynchronous jobs: Send a message to an SQS queue containing the token. A Lambda function consumes the SQS event, performs its tasks (async), and, when finished, sends the response back to the Step Function, allowing it to continue execution.
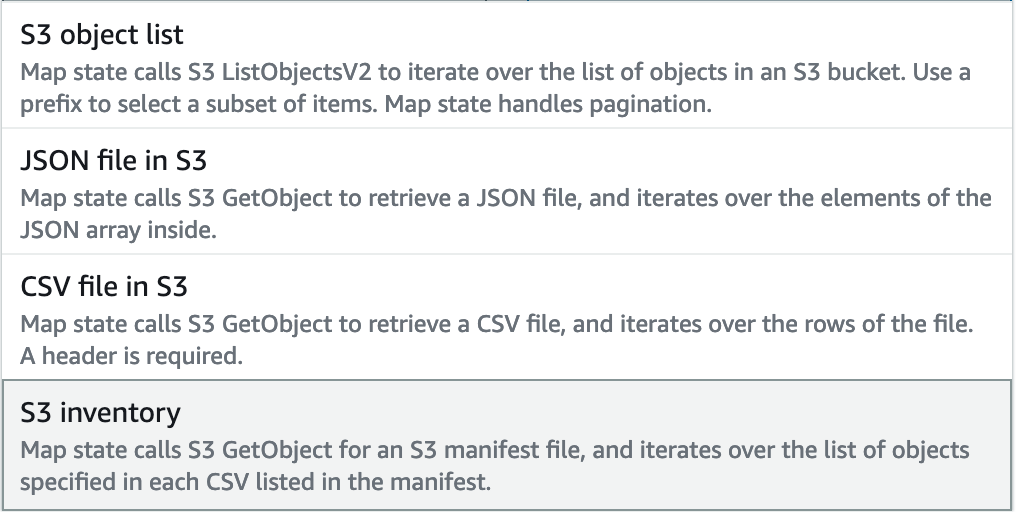
Map
The Map state is beneficial when parallelism is needed.
It can automatically process a batch of files in an S3 prefix, iterate over a CSV or JSON file, or handle a list of S3 keys stored inside a file.
Cons
For me, the biggest con of the Step Function is the learning curve required at the beginning to understand how data is passed from one task to another.

Users can manipulate the data sent and received using intrinsic functions.
I found myself occasionally blocked by the functions provided, which prevented me from performing some array manipulations I wanted to do.
So, be careful with the learning curve at the beginning.
Event-Driven vs. Orchestrated Workflows
Therefore, the question is when to use the entire lambda workflow vs. step function workflows.
Let’s have a deeper look.
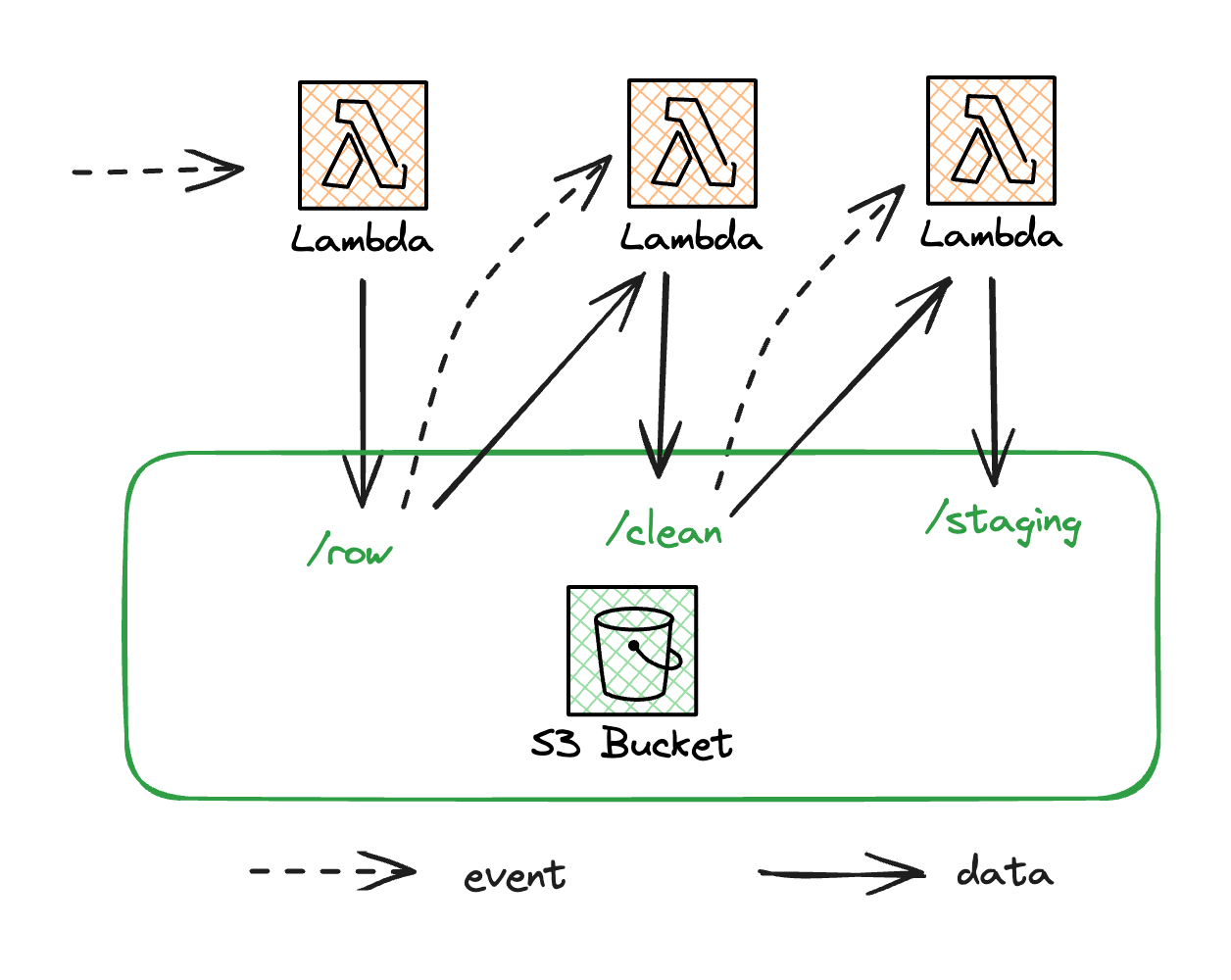
Event-driven workflow
The workflow is built as a sequence of Lambda functions triggered by events passed along the chain.
In the example below, we process data from S3 using a chain of Lambda functions triggered by S3 events.
Pros:
Loose Coupling: Each Lambda function can be updated independently.
Scaling: Each Lambda function can be scaled independently.
Cons:
End-to-End Monitoring: It is difficult to monitor the entire workflow from end to end.
Overview of Business Logic: Having a clear overview of the overall business logic is challenging.
Step function workflow
The alternative would be to use Step Functions to orchestrate the three functions.

Pros:
Provides a clear view of the entire workflow.
Simplifies the implementation of timeouts and retries.
Cons:
Scaling is not granular; you cannot scale individual parts of the workflow separately.
Incurs additional costs for using another service (25$ per million state transitions)
Mixing both
An interesting pattern I’ve used combines these two approaches by sending messages to SQS queues instead of directly triggering Lambda functions.

You get then the best of both words:
An overview and a log of all the past execution of the workflow with Step Functions
The flexibility to scale Lambda functions independently
Step Functions is a valuable tool to keep in your toolbox.
While it may be less powerful than orchestrators explicitly designed for building data pipelines (like Airflow or Dagster), its integration within the AWS ecosystem is a killer advantage.
When building pipelines, you can use Step Functions to:
• Initiate information ingestion via a Lambda function or ECS task running an ETL package (DLT or CloudQuery)
• Trigger ECS tasks running data transformations in DuckDB
• Trigger ECS tasks running dbt
etc
All without the need to host an additional orchestrator or deal with the complexities of MWAA.
Thanks for reading,
-Ju

I would be grateful if you could help me to improve this newsletter. Don’t hesitate to share with me what you liked/disliked and the topic you would like to be tackled.
P.S. You can reply to this email; it will get to me.
Great write up! Like Junaid mentioned, it is definitely underrated. Maybe because of the steep learning curve at the start and the other cloud agnostic options - although it has definitely improved over the years!
Great one, I have used Step Function quite alot. I like it and I think its underrated.
One of the e2e design I shared had it as well which shares a bit about step function as well: https://www.junaideffendi.com/cp/146962001
Step function triggering is a bit tricky, sqs and sns cannot trigger which is a bummer though.