


Lambda - Partial batch failure
Data Eng Weekly - Ep. 1

Welcome to the exciting world of data engineering!
Every week, you'll get a chance to learn from real-word engineering as you delve into the fascinating world of building and maintaining data platforms.
From the technical challenges of design and implementation, to the business considerations of working with clients, you'll get a behind-the-scenes look at what it takes to be a successful data engineer. So sit back, relax, and get ready to be inspired as we explore the world of data together!
Lambda - Partial batch failure
Context
A typical design pattern in data engineering on AWS is to couple an SQS queue in conjunction with a Lambda function on AWS because it allows you to decouple the event load from the concurrency of the Lambda function. This can be especially useful in cases where there may be a large amount of events that need to be processed, as it gives you more control over how those events are handled.
With this pattern, events are added to the SQS queue, and then the Lambda function is triggered to process them. This can be done either by setting up the SQS queue as an event source for the Lambda function, or by using a separate service (such as CloudWatch Events) to trigger the Lambda function when new messages are added to the queue.
Using this pattern can help you to scale your data processing pipeline more easily, as you can increase or decrease the concurrency of the Lambda function to match the rate at which events are being added to the queue. It can also provide some degree of fault tolerance, as any events that fail to be processed by the Lambda function will remain in the queue until they can be successfully processed
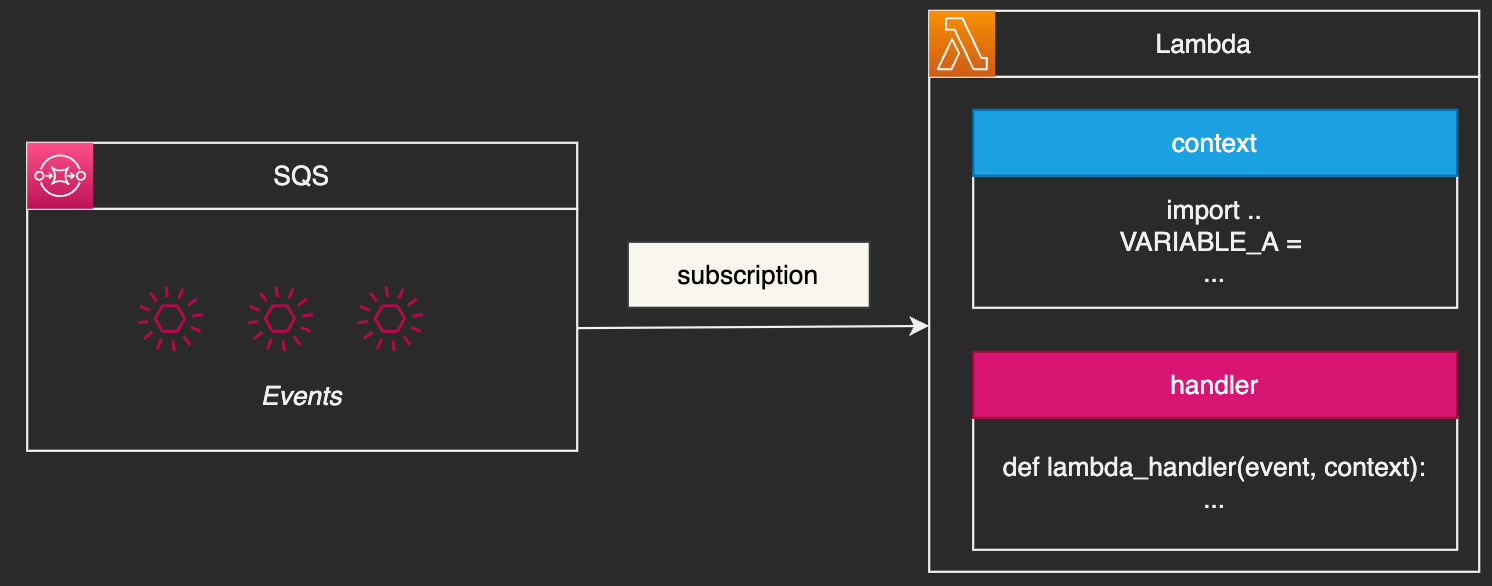
If you choose to consume events from an SQS queue in batch mode (as opposed to processing each message individually), there is a risk of inefficiency if the Lambda function fails while processing the batch. In this case, all of the events in the batch would be marked as failed, and would need to be processed again in order to be successfully processed.

f an event is processed multiple times by a failing batch of events, it is possible that it will be marked as failed and placed in the dead-letter queue, even if it did not actually generate any errors. This can happen if the Lambda function fails while processing the batch, and the event is retried along with the rest of the batch.
Batch Item Failures
In order to avoid it, you can activate the ReportBatchItemFailures in the SQS subscription options and return the failed event in the following format:
{
"batchItemFailures": [
{
"itemIdentifier": "id2"
},
{
"itemIdentifier": "id4"
}
]
}Your lambda should be able to gracefully handle the errors that should not make the lambda fail.
import requests
def lambda_handler(event, context):
failed_events = []
for record in event["Records"]:
try:
response = requests.post(url="www.test.com", payload={})
except requests.exceptions.Timeout:
failed_events.append({
"itemIdentifier": record["messageId"]
})
return {
"statusCode" : 200,
"batchItemFailures": failed_events
}
When a timeout occurs in the request, the event is marked as failed and sent back to the SQS queue.
The other records are processed normally and not affected by this timeout.
Batch Item Failures with lambda powertools
Instead of having to handle the failed event manually, lambda power tools provides some utilities to simplify the manipulation of events.
import json
from aws_lambda_powertools.utilities.batch import BatchProcessor, EventType, batch_processor
from aws_lambda_powertools.utilities.data_classes.sqs_event import SQSRecord
from aws_lambda_powertools.utilities.typing import LambdaContext
processor = BatchProcessor(event_type=EventType.SQS)
def record_handler(record: SQSRecord):
payload: str = record.body
if payload:
item: dict = json.loads(payload)
@batch_processor(record_handler=record_handler, processor=processor)
def lambda_handler(event, context: LambdaContext):
return processor.response()All records of the batch are processed by the record_handler. Here's the behaviour after completing the batch:
All records successfully processed. An empty list of item failures
{'batchItemFailures': []}is returnedPartial success with some exceptions. A list of all item IDs/sequence numbers that failed processing is returnd
All records failed to be processed.
BatchProcessingErrorexception is raised with a list of all exceptions raised when processing
To conclude, implementing a failure handling strategy for your Lambda functions is an important consideration when designing a data processing pipeline on AWS. By implementing this strategy early on in the design process, you can help to ensure that your pipeline is able to gracefully handle failures and maintain high levels of reliability and efficiency, even when processing a large amount of data.
thank you for reading.
-Ju
P.S. you can reply to this email; it will get to me.
Thanks for reading my Newsletter!
Subscribe for free to receive new posts and support my work.