
AWS DynamoDB: Single Table Design
Data Eng Weekly - Ep 22

In this week's technical deep dive, we focus on a specific AWS aspect: NoSQL database schema design in AWS DynamoDB.
DynamoDB has been a frequent topic in my previous posts.
This NoSQL database service, provided by AWS, offers significant benefits:
flexible pricing model
consistent response time even as your database scales
Let’s have a deeper look at this service
NoSQL Database
DynamoDB is a NoSQL database, which means that, unlike structured databases, objects aren't stored in tables, but as JSON objects.
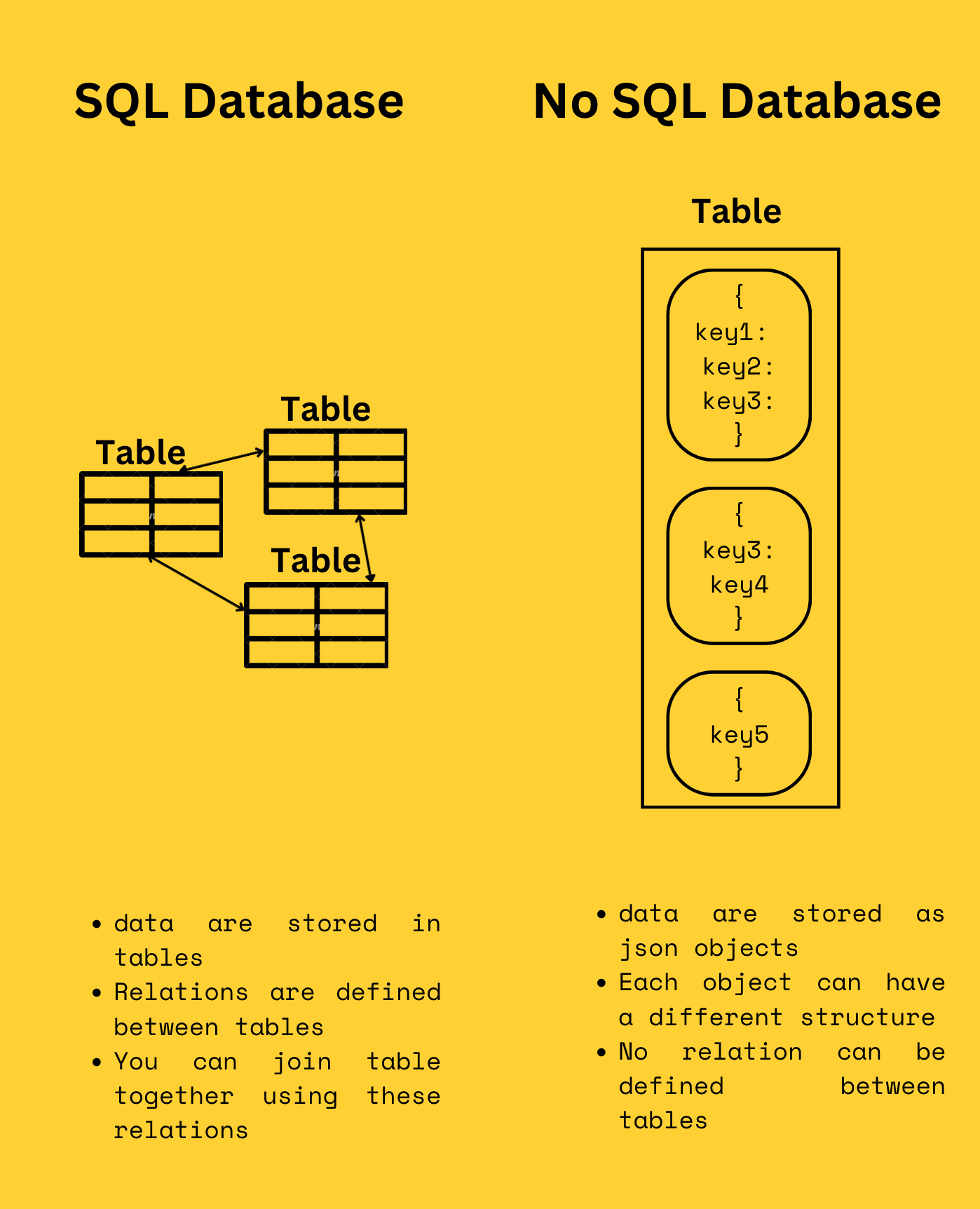
One of the significant advantages of a relational database is the ability to establish relationships between entities.
When you need a variety of information, you can combine or "join" tables to pull together data stored in different areas of your database.
However, in DynamoDB, join relations don't exist. This necessitates a complete paradigm shift in how to construct a model for this type of database.
Over the past few months, I've been wondering about the best practices for modeling in DynamoDB.
I came across an insightful article this week, so I thought it would be the opportunity to discuss this issue in this week's newsletter.
NoSQL Modelisation: a paradigm shift
Typically, when you begin modeling in DynamoDB, you may find yourself replicating patterns seen in traditional databases: you divide entities across different tables.
However, because join relations don't exist in DynamoDB, you end up retrieving the entities in your backend server and joining them manually.
Instead of executing a single SQL query, you essentially make two separate calls to DynamoDB and combine the entities in your backend.

I found this process quite frustrating until I discovered Single Table Design.
Single Table Design
In DynamoDB, the Partition Key (also known as a hash key) and the Sort Key (also known as a range key) are two fundamental concepts:
Partition Key: This is the primary means of accessing data in DynamoDB. All the data with the same partition key are stored together. When you make a request to DynamoDB, it uses the partition key value to hash the data into a specific partition for data storage.
Sort Key: This is used in conjunction with the partition key to provide additional sorting and filtering options for the data within each partition. When data is stored in a partition, it's sorted by the sort key value.
In DynamoDB modeling, the primary key and the sort key should be the only keys used, leading to their common use as composite keys (combine multiple columns to form a single key e. g. ‘#key1#key2’).
With a single table design, data are pre-joined and stored within a single table.
For every primary key, all possible dimensions are pre-computed, and each is listed under a unique sort key.
This results in a table structure that looks something like this:

For this particular use case, we want to access data specific to individual users.
Therefore, the Partition Key (PK) is set as the username.
The Sort Key, on the other hand, corresponds to the various dimensions of the user we want to examine.
We have the first dimension with Sort Key prefixed by 'PROFILE#' and a second one prefixed by ‘#ORDER' which lists all the orders.
When we want to pull up a user profile, we filter by PK and Sort Key beginning with 'PROFILE#'.

Due to the flexible nature of NoSQL, attributes can vary completely for different sort keys.
However, it's crucial to understand that retrieving information about a specific order won't be efficient in this setup: we would need to scan the entire table.
The design of this table is specialized to serve one specific need: retrieving all the orders associated with a particular user.
This approach may appear counterintuitive to those accustomed to traditional databases, but it presents the following advantages:
Performance consistency. Even when dealing with millions of users and billions of orders, the performance will be the same.
Single query to DynamoDB instead of multiple queries in a multi-table design.
If you opt for a single-table approach, you must be aware that:
Your access pattern is inflexible. It will be challenging to modify it.
It will limit you for analytics use cases (although analytics is not the primary purpose of DynamoDB).
To wrap it up, DynamoDB, a NoSQL database provided by AWS, offers a radically different approach to data modeling compared to traditional relational databases.
The single table design, which can initially be counter-intuitive to those familiar with SQL databases, emphasizes the use of composite keys (Primary Key and Sort Key) and pre-joins dimensions under these keys.
The scalability of this pattern comes with a certain cost (inflexible access pattern) that should be considered before opting for Dynamo DB.
Sources and interesting articles:
https://aws.amazon.com/blogs/database/choosing-the-right-dynamodb-partition-key/
https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/bp-modeling-nosql-B.html
https://www.alexdebrie.com/posts/dynamodb-single-table/
Re:Invent 2019:
Thanks for reading,
-Ju
I would be grateful if you could help me to improve this newsletter. Don’t hesitate to share with me what you liked/disliked and the topic you would like to be tackled.
P.S. you can reply to this email; it will get to me.