
Dagster + DBT = 🚀
Ju Data Engineering Weekly - Ep 33

DBT is present in almost every data stack today.
However, it needs to be orchestrated: you need to trigger a dbt run command to materialize one or several models in your DBT DAG.

For this reason, DBT is often used in conjunction with an orchestration tool that organizes the execution of these DBT commands:
Compute these models every day at 8 a.m.
Compute these other models every week.
Once the
dbt runcommand is finished, execute thedbt testcommand.etc…
Let’s look at the different types of orchestrators available on the market.
The limitation of task-oriented schedulers
A lot of scheduling tools available (Airflow, Astronomer, Prefect) are based on “tasks”: the user defines a series of tasks that should be executed one after another.
In order to orchestrate DBT runs, you usually end up with one orchestration DAG composed of one task to run all your models.

This setup is adequate when dealing with smaller DBT projects. However, as the number of models increases, the occurrence of errors tends to escalate.

The orchestrator’s inadequate understanding of the DBT dag structure can lead to two problems:
Diagnosing the Issue
When a task fails, all logs are dumped into one place: it can be difficult to get an overview on failing models and to know what exactly happened.
Rectifying the Error
Ok, you have found the failing model, great!
You have corrected the breaking SQL ( select * 💣 💥 …), nice!
Ok now: re-execute the models where data are not up to date …. heuuuu 🤔
This illustrates the limitations of most task-oriented orchestrators: they lack an understanding of the DBT dag, and this limits the added value they can provide.
On top of that, task-oriented DAGs make it quite difficult to schedule advanced materialization jobs like:
Backfilling a subset of a model
Auto-materialization based on data freshness
Dagster: declarative data Pipelines
Another orchestrator called Dagster approaches orchestration differently.
Instead of viewing the orchestration job as a graph of tasks to execute, Dagster considers it as a graph of “software assets.”
An asset is an object in persistent storage, such as a table, file, or persisted machine learning model.
A software-defined asset is a description, in code, of an asset that should exist and how to produce and update that asset.
This concept of software-defined assets aligns closely with how DBT defines a model
Each model lives in a single file and contains logic that either transforms raw data into a dataset that is ready for analytics or, more often, is an intermediate step in such a transformation.

This analogy between Dagster assets and DBT models makes their combination quite natural: 50% of dagster cloud users use DBT.
Dagster provides an a library making the process of integrating DBT in a Dagster project quite easy.
As you can see in this screenshot, all DBT models are imported as individual “assets” in the Dagster DAG.
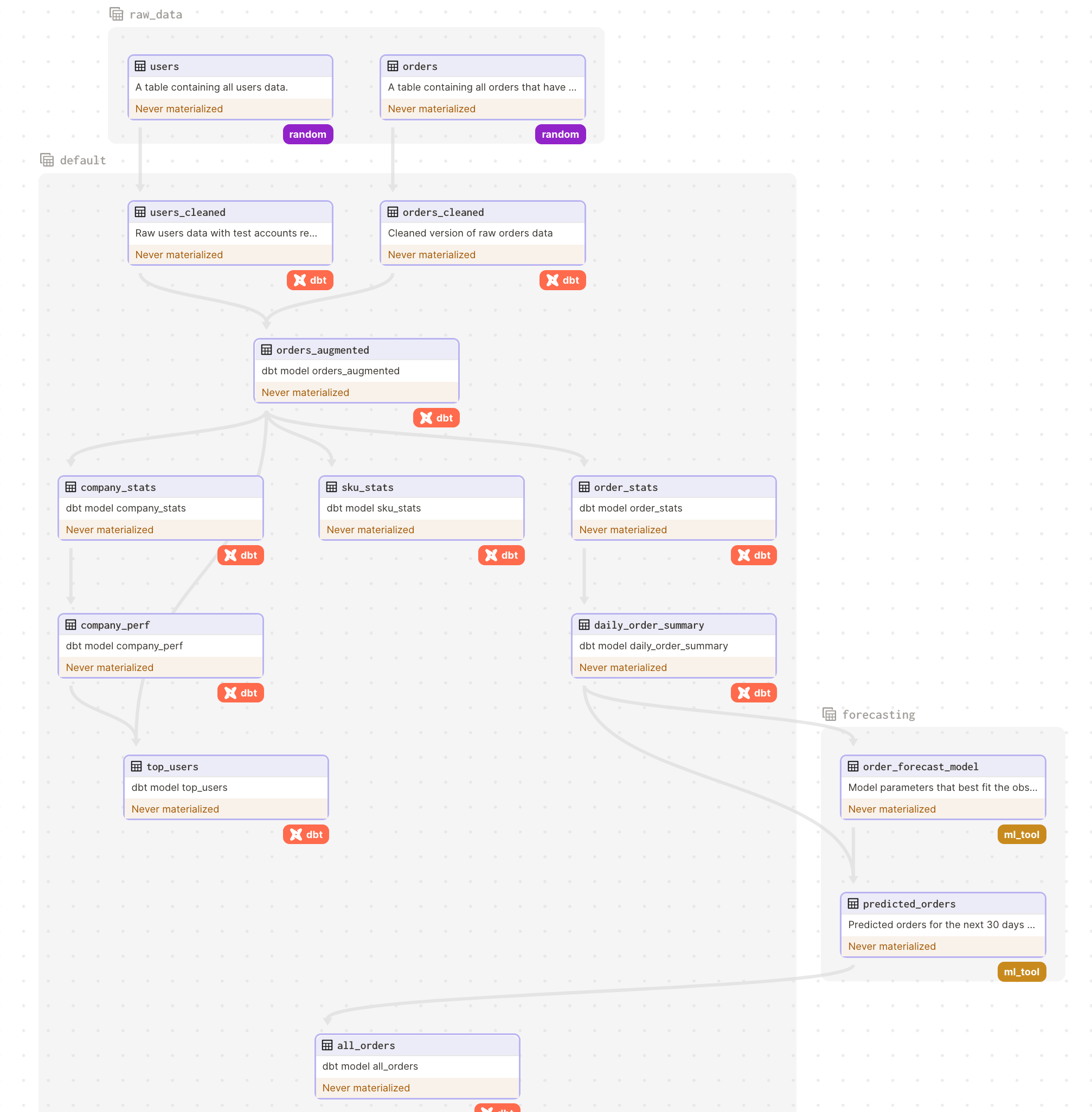
As you can notice in this project, the dbt models are living next to other types of assets:
Tables from an other DB

Machine learning models

The broad definition of an asset by Dagster enables a full lineage throughout the complete stack.
This is quite powerful as it allows for data refresh to trigger or be triggered by external events.
You can initiate for example the training of a machine learning model when new data arrives in the underlying DBT model.
Freshness based Materialization
In a task-based scheduler, you usually define an imperative workflow where a materialization is designed at a certain rate.
In the Dagster paradism, the user don’t ask DBT to run a model at a certain schedule, but instead define when data should be updated.
[Dagster provides a] way of managing change that models each data asset as a function of its predecessors and schedules work based on how up-to-date data needs to be
This allows you to define rules such as:
“The events table should always have data from at most 1 hour ago.”
“By 9 AM, the signups table should contain all of yesterday’s data.”

I really like this midnset as it allows the incorporation of business rules directly into the orchetrator, without having to think about complex cron combinations.
On top of it, it helps you save credits, as tables are recomputed only when needed.
Note: You can define directly the freshness policy in your DBT model YAML file:

Backfilling
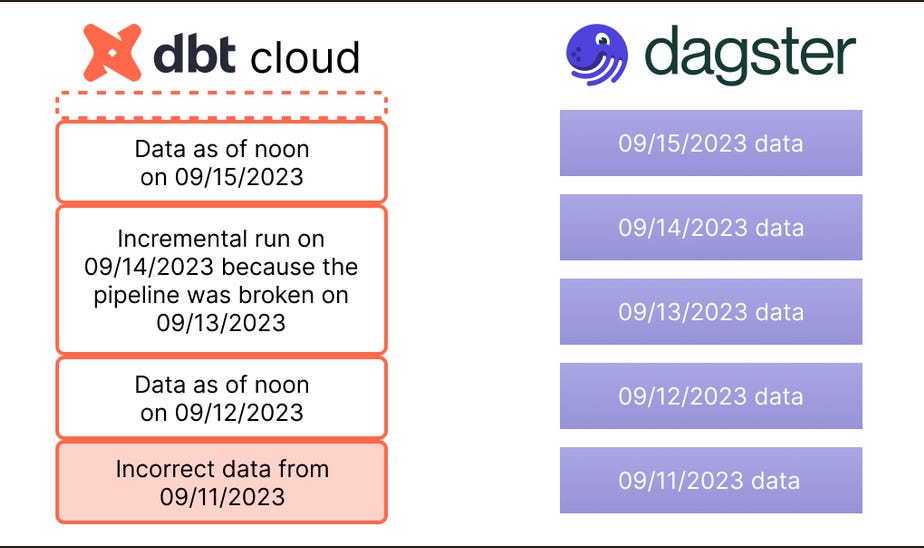
Dagster, instead of defining when a task should run, specifies when data has been updated.
This makes a huge difference for backfilling jobs. Indeed, when consulting previous model executions, you can track when a model has been updated.
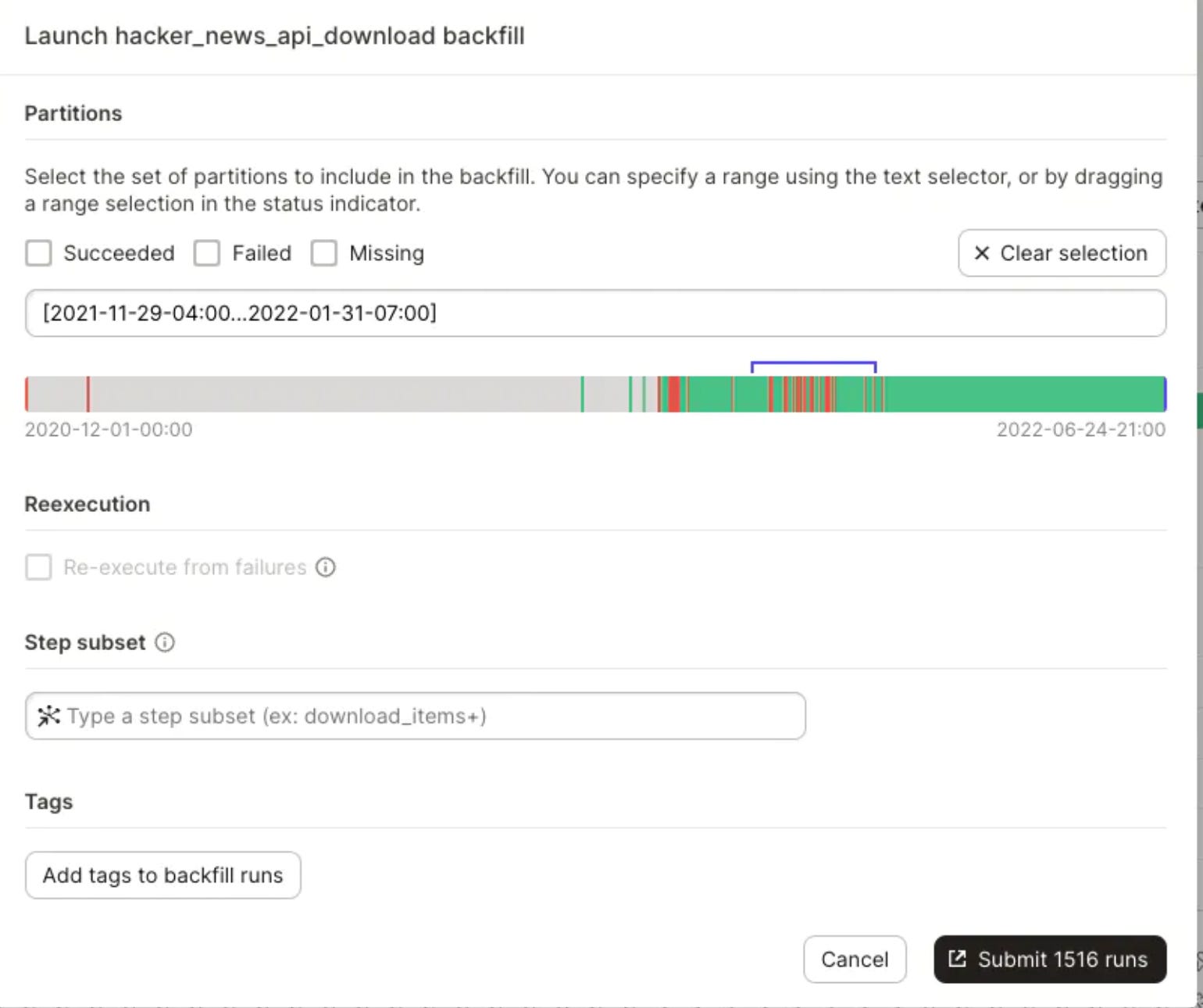
Dagster goes a bit further with the concept of partitions, which allows you to define an asset as a subset of your data.
You can split your data by a partition key: time window, region, customer group, marketing campaign, and track when each partition has been updated.
This is extremely powerful if you need to correct the SQL code of a failing DBT model: you can easily select corrupted partitions and launch a parallel backfill job.
Note: Dagster Partitions can also be used to build incremental models in DBT.

Prepare the way to a multi-compute engine stack
In my last article, I explained how tomorrow's data stack could combine multiple compute engines.
In this paradigm, Dagster seems to be a perfect fit.
The following snippets describe how to define the dbt command run when materializing a set of dbt models.

Leveraging the select parameter, it seems possible to set different —-profile to different models in the same DBT project.
This would allows to have several models coexisting in the same project but with different underlying engines (e.g DuckDB and Snowflake).
I will further explore this possibility in the next few weeks and keep you posted.
Thanks for reading,
-Ju
I would be grateful if you could help me to improve this newsletter. Don’t hesitate to share with me what you liked/disliked and the topic you would like to be tackled.
P.S. you can reply to this email; it will get to me.
Upon closer examination, it becomes evident that orchestrating dbt models can be done similarly in Airflow and Dagster. In Dagster, models are orchestrated as software assets, while in Airflow, they are orchestrated as tasks.
(1 dbt DAG=1 Airflow task or 1 dbt model=1 Airflow task).
Simply recreate your dbt DAG in your Airflow and you are done! This approach is similar to Dagster.
Essentially, both tools follow comparable approaches. The core concept remains fundamentally the same. It's akin to what Shakespeare famously said: "A rose by any other name would smell as sweet."
Regarding errors, in Airflow, you typically debug at the task level .You can view task logs, inspect task dependencies, and rerun individual tasks if needed. This approach is conceptually similar but uses different terminology. An entire dbt DAG run can be triggered by a single Airflow task. This approach is akin to representing the entire dbt DAG as a 'black box'. Alternatively, you can map each dbt model to an individual Airflow task. While this introduces complexity, especially in larger projects, it provides finer-grained control over tasks, including handling failures and reruns.