
Stop the Chaos in Your Data Warehouse with DBT
Data Eng Weekly - Ep 8

Welcome to the exciting world of data engineering!
Every week, you'll get a chance to learn from real-world engineering as you delve into the fascinating world of building and maintaining data platforms.
From the technical challenges of design and implementation to the business considerations of working with clients, you'll get a behind-the-scenes look at what it takes to be a successful data engineer. So sit back, relax, and get ready to be inspired as we explore the world of data together!
Stop the Chaos in Your Data Warehouse with DBT

When I first encountered DBT, I have to admit that I was initially skeptical about its value.
It took me some time to fully understand the power of this tool.
However, once I started using it more regularly, it quickly became clear to me that DBT is an essential component of any modern data stack.
So, what exactly is DBT?
Simply put, DBT is a transformation tool that allows you to write SQL code to transform raw data into organized, structured data that is ready for analysis.
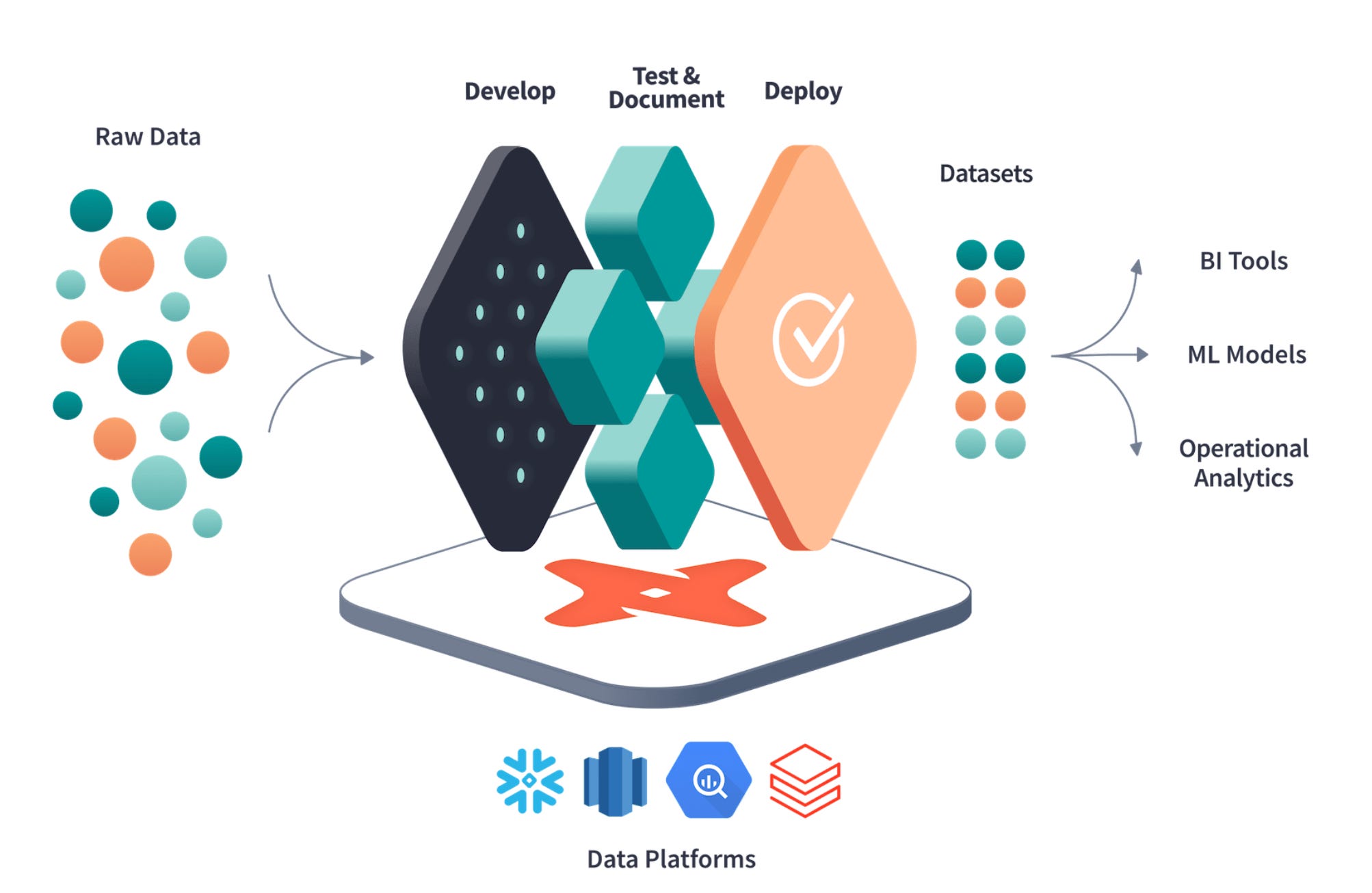
It is used on top of a cloud data warehouse to manage all the objects you create, such as tables, views, functions, etc.
Before the advent of DBT, engineers often had to rely on custom scripts to create tables and views in their data warehouse, which made it difficult to maintain proper version control and collaboration features such as branches and merge requests.
You often ended up with huge SQL files containing hundreds of lines of code with no real modularization or organization.
Establishing a clear lineage between SQL objects in your data pipeline could be very challenging as well. Since there was no automated tracking of dependencies between objects, it was difficult to understand the relationships between different parts of the pipeline.
DBT solves all these problems.
1- Version control
Imagine you're a data engineer working on a complex data pipeline with several other team members. Without version control, it's difficult to keep track of changes made by different team members, leading to confusion and potential errors in the pipeline.
With DBT all your objects (tables, views, functions ect) are managed “as code”.

Just like in traditional software development, DBT allows multiple engineers to collaborate on the same source code and manage the deployment process through a standard software deployment process (CICD). This approach leads to greater efficiency, quality, and scalability in managing the data pipeline.

The changes in your models are applied to the warehouse using the DBT CLI:
dbt run 2- Code compiling with Jinja
DBT allows you to define models using SQL code that can be enhanced with a powerful templating framework called Jinja.
This feature confused me a lot, but once understood, it becomes clear that it is one of the most powerful and versatile aspects of DBT.
But what is exactly jinja?
Jinja is a popular templating language that DBT has integrated into its platform. It allows you to create dynamic SQL queries and define reusable SQL code blocks.
With Jinja, you can use placeholders in your SQL code that are enclosed within double curly braces, like {{ variable_name }}.
These placeholders can be used to inject dynamic values or expressions into your SQL code at runtime.
Examples of templated SQL in DBT:
2.1 Object referencing:
In DBT other objects are referenced dynamically.
{{
config(
materialized="view", schema="staging"
)
}}
SELECT
column_1,
column_2
from {{ ref('model_1') }}This DBT Code will be automatically compiled by DBT and the following SQL will be executed in the database:
CREATE VIEW staging.model_2
SELECT
column_1,
column_2
from staging.model_12.2 Materialisation strategies
In the previous example, we specified materialized="view", which determines the type of object created. Other options for materialization are available in DBT, including:
table. Create a table object. The table will be created each time
dbt runis executedincremental: incremental models in DBT allow you to insert or update records into a table since the last time DBT was run. The options available for incremental models depend on the underlying database. In Snowflake, for example, you can choose between using a
mergestatement to update existing records and insert new ones, using adeletestatement to remove existing records and then inserting new ones, or simply appending new records to the table.ephemeral: ephemeral models in DBT are used to create temporary tables or views that are only used in the context of the current DBT run. These objects are not persisted in the database and are not visible to other tools or applications outside of DBT.
Example of an incremental model:
{{
config(
materialized='incremental',
unique_key='date_day',
incremental_strategy='delete+insert',
...
)
}}
select ...2.4 Use macros
Use macro to re-use business logic:
Let's imagine you have a CASE WHEN SQL logic applied to different views, you can then simply create a macro
{% macro compute_columne_blabla(column_name) %}
CASE WHEN {{ column_name }} =1 THEN 'lala' else 'lili'
{% endmacro %}and use this macro directly in your models!
{{
config(
materialized="view",
)
}}
SELECT
column_1,
blabla,
{{ compute_columne_blabla('blabla') }} as blibli
from {{ model_1 }}The generated SQL will be then:
CREATE VIEW model_2
SELECT
column_1,
blabla,
CASE WHEN blabla =1 THEN 'lala' else 'lili' as blibli
from model_1Instead of copy-pasting SQL code across multiple models, macros provide a way to abstract and modularize common SQL patterns or functions. This reduces code duplication and can make it easier to change the behavior of the underlying logic by simply updating the macro. Amazing :)
DBT provides as well a range of pre-existing macros that can be leveraged to simplify your SQL.
My favorite: “star” macro.
With this macro, you no longer need to manually list all the column names of the upstream objects (which can be really painful ^^). Instead, you can use the macro to dynamically retrieve the column names and include them in your SQL code.
select
{{ dbt_utils.star(ref('my_model')) }}
from {{ ref('my_model') }}Will generate:
CREATE VIEW model_2
SELECT
colomn_1,
column_2,
column_3
from model_13 - Testing
DBT provides a built-in testing framework that enables data engineers to test the integrity and accuracy of their data pipeline.
The testing framework allows you to define and run tests on your data models and macros, ensuring that they are working correctly and producing the expected results.
Tests are launched in DBT using the following command:
dbt testIn DBT, I love the way that tests are managed.
You simply need to list the tests you want to execute in a YAML file, and they will be executed automatically.
You can define your own SQL testing queries for your tests, and DBT will raise an error if they return any records.
But DBT also comes with a set of pre-built tests that you can reference in your model definitions.
For example, if you want to test that a column contains less than 5% nulls, you can simply add a reference to this pre-built test, and DBT will handle the rest!
models:
- name: my_model
columns:
- name: id
tests:
- dbt_utils.not_null_proportion:
at_least: 0.95Examples of other pre-built tests:
at_least_one: Asserts that a column has at least one value.
recency: Asserts that a timestamp column in the reference model contains data that is at least as recent as the defined date interval.
equal_rowcount: Asserts that two relations have the same number of rows.
not_accepted_values: Asserts that there are no rows that match the given values.
…. and much more
I cannot overstate the importance of building a data platform that is reliable and trustworthy. And with DBT's testing features, it's easier than ever to achieve that level of trust!
By reducing the effort required to write tests, engineers are empowered to build more of them - and that means you can have more confidence in the accuracy and consistency of your data. This is a critical success factor for any data platform, and DBT makes it possible with its intuitive and powerful testing framework.
4- Lineage
As previously mentioned, one of the key features of DBT is the ability to reference other models using the {{ ref('file_name') }} macro. By using this macro, DBT can automatically identify the dependencies between your data models and create a directed acyclic graph (DAG) of your data pipeline.
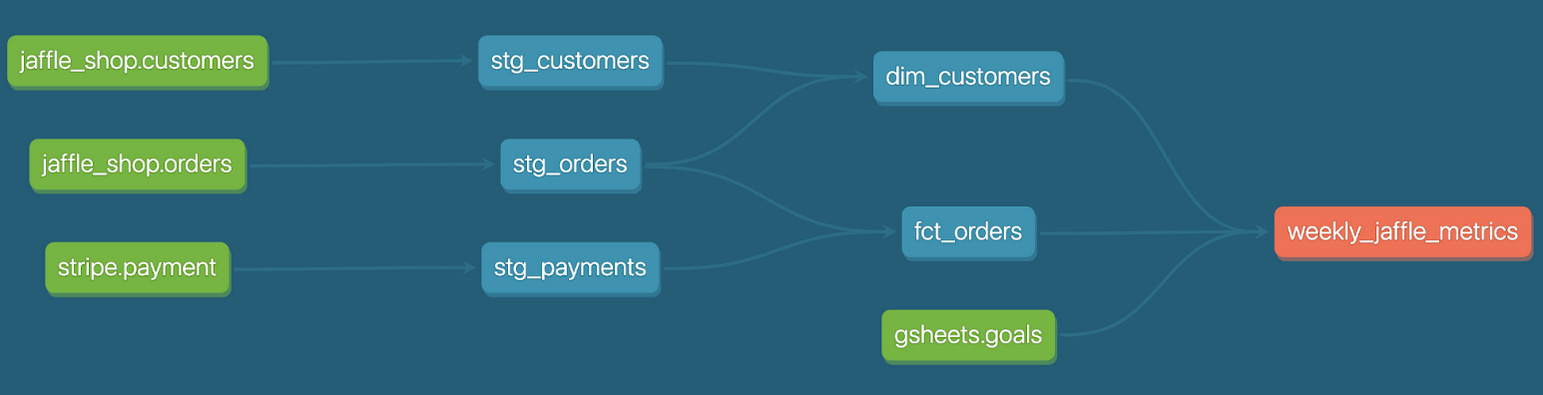
The DAG provides a visual representation of the flow of data in your pipeline, highlighting the relationships between your models.
This can be incredibly helpful for documenting your data pipeline and understanding how data is transformed and aggregated as it moves through your organization.
Cons ?
Despite the many benefits of using DBT, I've found that one of the biggest challenges is governance around its usage. DBT hides a lot of complexity behind pre-built functionalities like incremental loading.
If users don't fully grasp these complexities, it can result in inefficient pipelines and high consumption of credits in your underlying cloud warehouse.
That's why it's critical to have strong governance processes in place when using DBT - to ensure that your data platform is running as smoothly and cost-effectively as possible.
More about it here:
I hope this post has given you a comprehensive overview of DBT and all its possibilities. I'm excited to hear from those of you who have already deployed and used DBT in your own work.
So please, don't hesitate to reach out with any questions, comments, or experiences you'd like to share.
thank you for reading.
-Ju
I would be grateful if you could help me to improve this newsletter. Don’t hesitate to share with me what you liked/disliked and the topic you would like to be tackled.
P.S. you can reply to this email; it will get to me.