
Data pipelines and SCDs
Ju Data Engineering Weekly - Ep 67

In my last newsletter release, I wrote about how to design data pipelines that are easily backfillable.
Debugging Data Pipelines

Building data pipelines is easy. Maintaining them is not. In my first article of 2024, I wrote a small manifesto detailing how I believe the development experience for data engineers could be improved. Many of these points addressed the challenges that come with maintaining pipelines.
The recommended approach for backfilling is not to write ad-hoc SQL but to re-run the pipeline over a specified interval.
This is done by designing a pipeline with idempotent transformation code.
But what about SCDs?
How should we approach them in this context?
SCDs?
Slowly Changing Dimensions (SCD) are used to handle changes in a dimension over time.
The most common types are SCD Type 1, 2, and 3.
Here’s a quick recap of how they work when a new version of a record needs to be written:
• SCD Type 1: Overwrites a row with the new value.
• SCD Type 2: Adds a new row with the new value.
• SCD Type 3: Adds a new column with the new value.
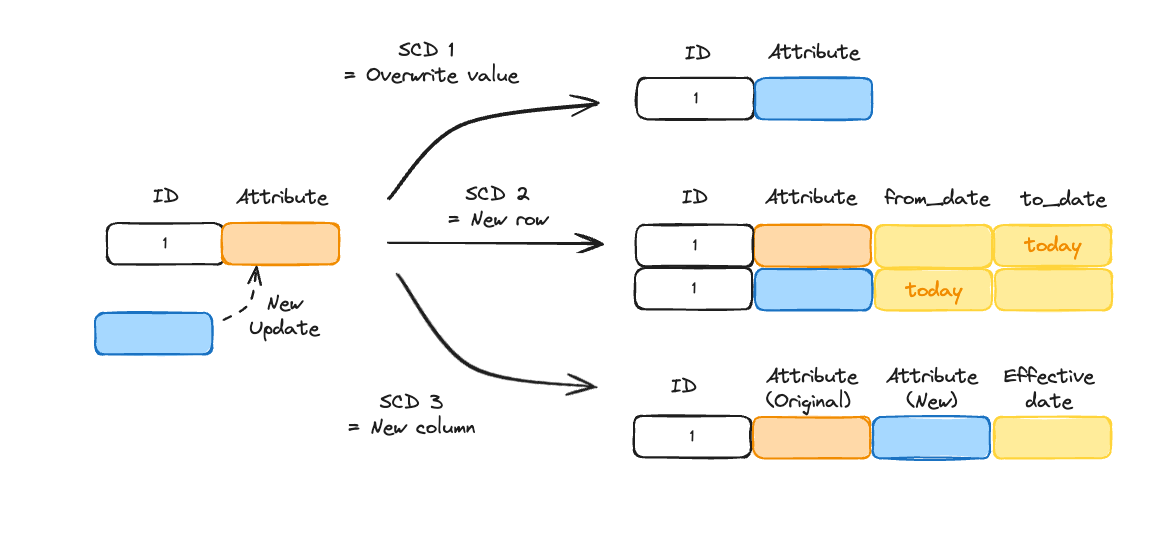
🫸 SCD 1 & 3
SCD 1 and 3 overwrite the data by assuming the records are mutable.
And that’s a problem.
Indeed, data engineers usually prefer to consider the data as immutable.
This makes our pipeline replayable and, therefore, easily maintainable.
Imagine we perform an SCD1 update three times at t0, t1, and t2.
Unfortunately, we discovered that the 🟦 value was incorrect, yet it was used to compute a downstream metric.

Now, we have received its corrected version 🟩.
How can we correct the downstream metric?
This is super complex when not impossible and, therefore, a no-go for making our pipeline replayable.
🧠 SCD 2
SCD 2 seems to check all the boxes: it does not lose information, is idempotent, and compresses the data.
But there is a catch.
They are hard to manipulate.
First, reading fact data is more complex because of a so-called “surrogate key lookup.”
Let’s take an example of SCD2:
A dimension table contains the user country.
Addresses change over time and have a
from_dateandto_datevalidity period. The combination of user, address, and validity is not associated with a natural key but with a generated key called a surrogate key.A fact table contains the historical purchases of each user.
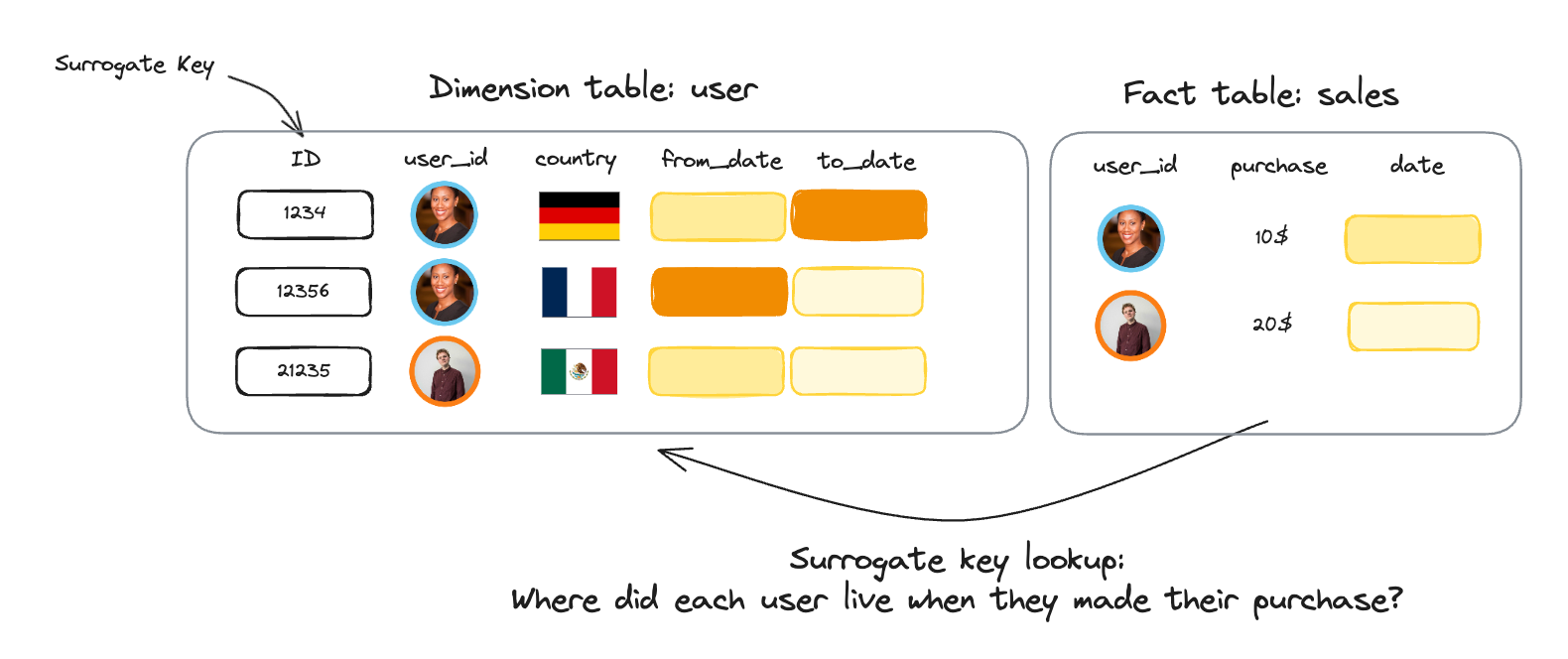
We want now to compute the number of sales per country for our marketing department.
The query would look like the following:
With user_sales as (
SELECT *
FROM sales s
JOIN user u ON
s.user_id = u.user_id
AND s.date > u.from_date
AND s.date <= u.to_date
)
select country, sum(purchase)
from user_sales
group by country The issue with such a lookup is that join performance might be problematic when the output is used in a BI tool.
Moreover, tables could become disconnected due to unsynchronized ETL processes between the source and analytics systems.
In such cases, you must ensure that a surrogate key exists in the dimension table and establish a resolution process if it does not.
This makes loading such fact tables prone to errors and difficult to manage.
Additionally, testing the correctness of SCD2 can be cumbersome.
For instance, you may need to verify that the [from_date, to_date[ intervals do not overlap.
Writing a query for this is not trivial (nice SQL interview question, btw).
🎯 Snapshot table
An alternative approach is to use snapshot tables.
The concept of a snapshot table is to fully replicate the dimension table at each scheduled run of the ETL.
If the ETL runs every day, then the snapshot table will appear as follows:

Yes, it’s a lot of data replication.
But the mental model is much simpler.
First, the number of sales per country query becomes:
With user_sales as (
SELECT *
FROM sales s
JOIN user u ON
s.user_id = u.user_id
and u.date = s.date
)
select country, sum(purchase)
from user_sales
group by country Which is much simpler to understand.
The model is also highly reproducible.
Correcting a historical version of a record is super easy: replay the ETL pipeline for a specific partition (a day in that case).
No headaches.
And in a world where engineering time is much more valuable than storage costs, trading fewer headaches for more storage makes sense.
However, there are few cases where the snapshot approach reaches its limit.
Consider our user example mentioned earlier.
If we want to calculate the average time users stay in a country, SCD2 is quite compelling:
SELECT sum(to_date - from_date)/count(*)
FROM usersDoing this with a snapshot table would be more complicated (another SQL interview question ^^).
As always, one approach won’t cover all the use cases.
However, snapshots generally offer a simpler way to model changing dimensions.
With cloud warehouses having split storage and computing, we are no longer as limited by storage as we were with previous warehouse generations.
And that’s a trade-off we should remember when designing pipelines:
Overspending on resources for a simpler solution will often quickly be offset by spending less time on maintaining it.
Resources on the topic:
-Ju

I would be grateful if you could help me to improve this newsletter. Don’t hesitate to share with me what you liked/disliked and the topic you would like to be tackled.
P.S. You can reply to this email; it will get to me.
What do you think about SCD2 for the bronze layer and then SCD1 for silver and gold. This way can still get the historical data if you want to but it's easier to query.
Could also use SCD2 as intended by its inventor, Dr. Kimball to store the surrogate key in the Fact table. Then no complex SQL required to match correct version of Dimension to the Fact. https://www.kimballgroup.com/2008/09/slowly-changing-dimensions-part-2/