


DEnGPT : Autonomous Data Engineer Agent
Data Eng Weekly - Ep 19

As I mentioned in my previous posts, I've begun to explore how recent developments in Language Learning Models (LLMs) could be beneficial in the context of data engineering.
My latest experiment was based on GPT-3.5, and it was not successful due to the numerous errors the model generated in the code.
I received an API key from OpenAI 10 days ago, allowing me to access GPT-4 programmatically.
Since then, I've had some fun and created the first version of my data engineering agent. This agent was able to set up a first simple data pipeline entirely autonomously!
The long-term goal is to have a collection of integration patterns and agents that can be combined to automatically generate, manage, and maintain data pipelines at scale.
I release the code of this first agent in this repo. I was mostly inspired by this project and adapted it to the data engineering context.
Let’s have a deeper look at how it’s done.
The v0 Pipeline
As an initial step, the first integration pattern I wanted to have built is quite simple:
Data are queried from an external API via an AWS Lambda function.
Data are saved in S3.
The pipeline is deployed to AWS using the Serverless framework
The data source is economic data from this provider.
I am fully aware that the task is really simple and not really representative of a real-world data engineering problem.
This first experiment, even if simple, lays the groundwork for understanding how GPT-powered agents work and can be used for code generation.
With this initial validation, I can then gradually move towards handling more complex and real-world data engineering problems.
Development workflow with an Agent
The current workflow of this version 0 is as follows.

The pipeline is defined in a primary prompt that details the developer's requirements. This prompt is sent to the code generation tool, which produces and creates all the code and corresponding files locally. The generated code is then run by the developer who adjusts the prompt based on potential errors.
It took me about 4-5 iterations to correct minor mistakes made by the model and get eventually to this prompt:
1- Lambda Function:
Develop a Python file named 'lambda_handler'. This function should act as a Lambda function handler and accept two arguments: event and context.
Invoke the endpoint url saved in env variable {provider}_{dataset_name}_ENDPOINT.
Generate the file name by creating an MD5 hash of the data.
Save the file in the bucket {bucket_name}, using the path data_profile=raw/provider_name={provider}/dataset_name={dataset_name}/request_time=request_day/, where request_day is the day of the request in UTC.
Append metadata to the file with the following information:
Request time in UTC
Provider: {provider}
Dataset name: {dataset_name}
The function should return a dictionary with statusCode set to 200.
Ensure all import statements are at the top of the file.
Create a requirements.txt file containing the necessary dependencies (excluding hashlib, which is already imported).
2- Deployment on AWS using the Serverless Framework:
Generate a serverless.yml file in the base directory. This file should define:
A Lambda function named {lambda_name} triggered at a certain {frequency}.
An S3 bucket named {bucket_name} lowercase with read and write access for the Lambda function.
Set useDotenv: true at the top of the file
A shell script file to install the required Serverless plugins globally
The AWS region set to 'eu-west-1'.
use plugin serverless-python-requirements:
custom:
pythonRequirements:
dockerizePip: true
3- .env File:
Construct a .env.template file in the base directory, housing the necessary environment variables for the serverless.yml file. As you can observe, the prompt is quite long for such a simple app.
When crafting it, I felt like I was writing a best practices document, something I have done with all engineering teams I have worked with.
The good point is that these best-practices prompts, even if they are a bit tedious to write, can be reused for all the code-generation processes.
The novel approach to coding appears to involve outlining best practices manually, similar to what we do in our internal team documentation, and then delegating the entire code generation process to Chat-GPT.
Therefore, I envision the following workflow for the next version of the agent:

I imagine the agent being capable of executing the code it generates and rectifying any minor errors on its own.
If it encounters a problem it can't solve, it could seek assistance from the developer.
Ideally, the agent would also be capable of creating directly a Merge Request for the developer to review.
How does the agent generate code?
The process of automatic code generation by the agent can be summarized as follows:

The complete process is executed by the following Python file.
step 1- File list generation
An initial request is made to Chat-GPT that combines two prompts:
The app description made by the developer
A prompt asking to list the necessary files for the app
You are an AI developer who is trying to write a program that will generate code for the user based on their intent.
When given their intent, create a complete, exhaustive list of filepaths that the user would write to make the program.
only list the filepaths you would write, and return them as a python list of strings.
do not add any other explanation, only return a python list of strings.The model then returns a list of files that will need to be generated:

step 2- shared context
To maintain context between the files, a 'shared_dependency' file is created and reused across the code generation of each individual file. This file stores information necessary to ensure consistency across files. This file is generated using the following prompt:
You are an AI developer who is trying to write a program that will generate code for the user based on their intent.
In response to the user's prompt:
---
the app is: {prompt}
---
the files we have decided to generate are: {filepaths_string}
Now that we have a list of files, we need to understand what dependencies they share.
Please name and briefly describe what is shared between the files we are generating, including exported variables, data schemas, id names of every DOM elements that javascript functions will use, message names, and function names.
Exclusively focus on the names of the shared dependencies, and do not add any other explanation.In our example, the shared context generated by the agent is the following:
Based on the user's prompt, the shared dependencies between the files are:
1. Lambda Function (lambda_handler.py):
- OEC_ECI_trade_ENDPOINT (Environment Variable)
- data_profile=raw/dataset_name=ECI_trade/ (Directory Path)
- sumeo-provider-oec-data (Bucket Name)
- data_profile=raw/provider_name=OEC/dataset_name=ECI_trade/request_time=request_day/ (Directory Path)
- MD5 hash (File Name Generation)
- Metadata:
- Request time in UTC
- Provider: OEC
- Dataset name: ECI_trade
- statusCode (Return Value)
2. Deployment on AWS using the Serverless Framework (serverless.yml):
- lambda_data_to_s3 (Lambda Function Name)
- sumeo-provider-oec-data (S3 Bucket Name)
- useDotenv: true (Configuration)
- serverless-python-requirements (Plugin)
- eu-west-1 (AWS Region)
3. .env File (.env.template):
- OEC_ECI_trade_ENDPOINT (Environment Variable)step 3- Generate the code for each file
The agent generates then the files one by one.
In order to get the code for a specific file, I use the following prompt:
You are an AI developer who is trying to write a program that will generate code for the user based on their intent.
the app is: {prompt}
the files we have decided to generate are: {filepaths_string}
the shared dependencies (like filenames and variable names) we have decided on are: {shared_dependencies}
only write valid code for the given filepath and file type, and return only the code.
do not add any other explanation, only return valid code for that file type.
""",
f"""
We have broken up the program into per-file generation.
Now your job is to generate only the code for the file {filename}.
Make sure to have consistent filenames if you reference other files we are also generating.
Remember that you must obey 3 things:
- you are generating code for the file {filename}
- do not stray from the names of the files and the shared dependencies we have decided on
- MOST IMPORTANT OF ALL - the purpose of our app is {prompt} - every line of code you generate must be valid code. Do not include code fences in your response, for example
Bad response:
```javascript
console.log("hello world")
```
Good response:
console.log("hello world")
Begin generating the code now.The file is then created by a Python function I have written manually.
You can find the complete generated code in this folder.
I was able to deploy the code to AWS with the following command:
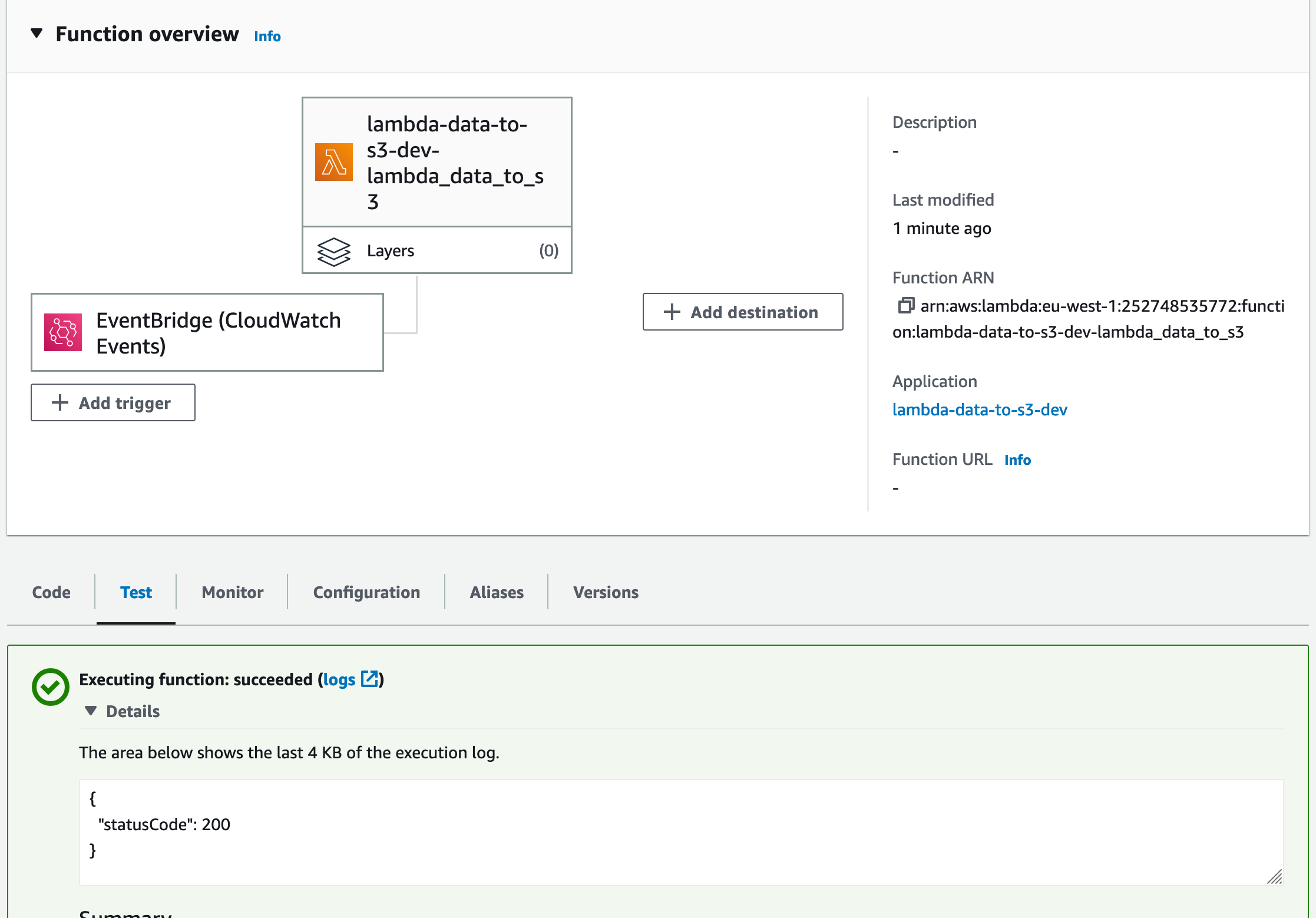
sls deploy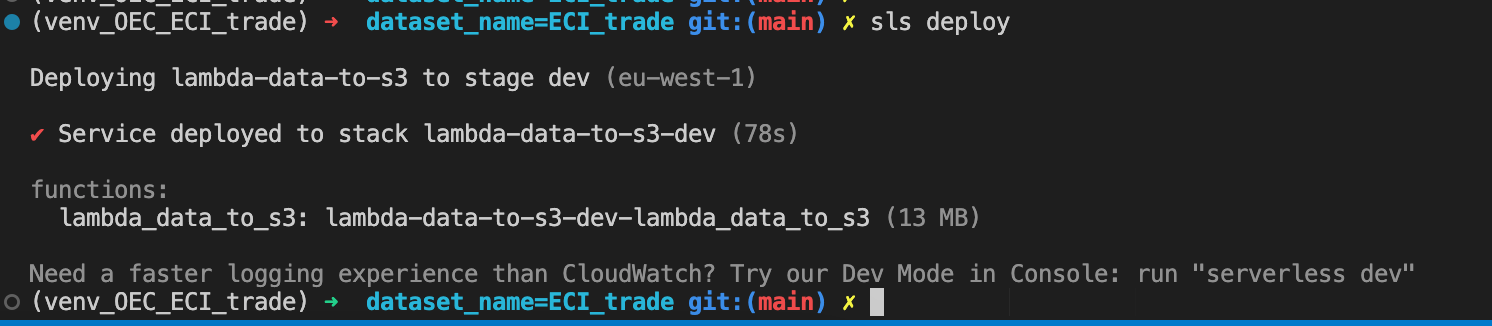
… and I have now a lambda being triggered every day at 9 pm and pushing data automatically to s3.


Outlook
I must say that I had a really positive experience overall, and I'm genuinely excited about the potential of this Agent.
Here are my next steps:
Workflow: I want to adapt the workflow so the agent can execute the pipeline and correct the original prompt by itself. This means the agent will trigger a bash file to deploy the lambda to AWS, execute it, and pass the output logs to the code generator if any error occurs.
Pipeline: I want to add the next step in the workflow.
Data Profiling: I plan to have the agent run the lambda a first time to get the data and create a YAML file listing all the fields of the json with their respective types (auto data catalog).
Snowflake Ingestion: I want the agent to create the Snowflake “copy into” statement to load the json data into a landing table automatically from s3.
Normalization: I intend to have the agent create the DBT models to normalize the json across different tables automatically.
Make the pipeline self-healing.
I want to feed the lambda and DBT logs to the agent, in order to adapt the pipeline code automatically if the provider decides to change a data type, add a column ect.
The source code for the project is completely open. If you're interested in contributing to the development of the agent, or if you're considering integrating it into your company's workflow, please let me know!
Thanks for reading,
-Ju
I would be grateful if you could help me to improve this newsletter. Don’t hesitate to share with me what you liked/disliked and the topic you would like to be tackled.
P.S. you can reply to this email; it will get to me.