


ELTs: Buy vs Build
Ju Data Engineering Weekly - Ep 52

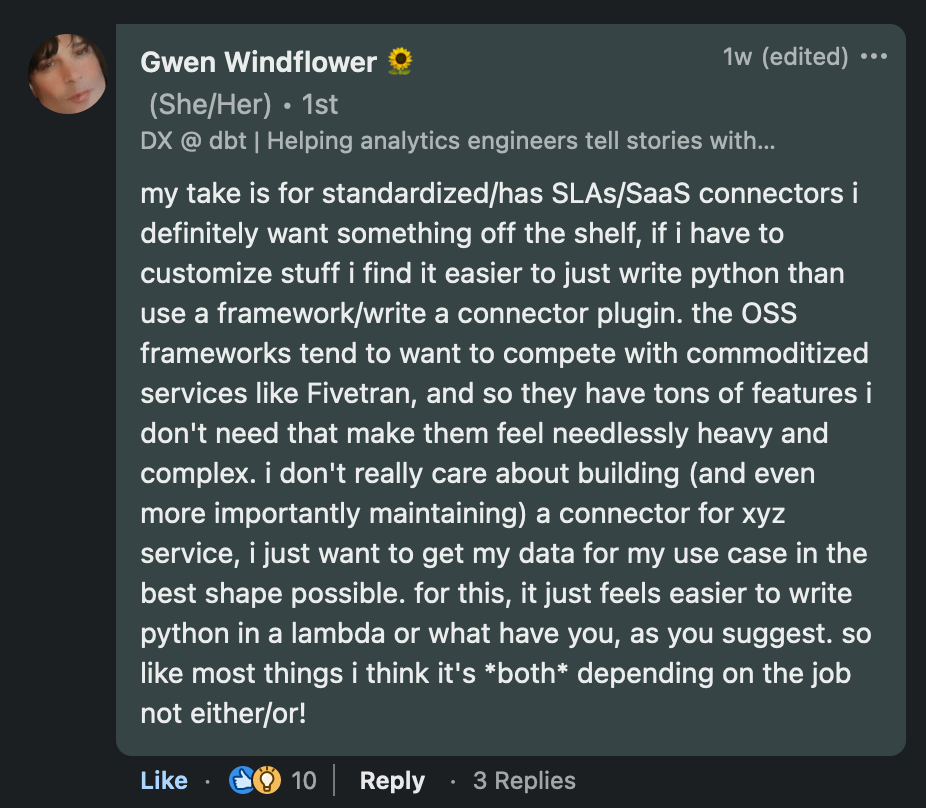
I hit a nerve last week on Linkedin with a post about ELT tool choice: should you build your connectors, or buy from a SaaS provider?
The discussions and remarks in the comments of this post were really insightful, so I decided to summarize all the opinions in this post.
This build vs buy dilemma appears to be tied to the context of each company.
I attempted therefore to identify some personas or patterns representing different company contexts for each approach.
Team Buy
Persona:
Many standard sources
Easy SaaS onboarding
Few tech profiles - many business requests
Many people disagreed with this post because they prefer using a SaaS solution to solve their integration problem.
The most named solutions in the open-source space were Airbyte and Meltano. In the commercial space Fivetran, Stitch, and Azure Data Factory were mentioned.
The perceived added value of SaaS tools is mostly through these two features:
Maintained library of connectors
Managed workflow: automatically handles retries, recovery of failed jobs, backfill, and observability.
These features were often linked to a perception of scalability in terms of the number of sources to manage: "I set it up one time and it simply runs, no maintenance needed."
Indeed, it's a no-brainer to go for SaaS solutions if you can outsource the complete data integration of your platform to a SaaS provider.
Two features were mentioned that I hadn't thought about before:
It enables non-technical users to ingest their own datasets.

1 tool = 1 reference = centralized documentation.
While I did not expect this feature, I understand the motivation behind it, even if it's probably a broader topic than just the ELT tool picking.


For all of these reasons, SaaS tools are suitable for teams dealing with standard data sources with well-maintained connectors (Stripe, Zendesk. etc).
This scenario is common in certain verticals, such as B2B SaaS or e-commerce companies.
However, relying entirely on SaaS providers comes with certain risks:
Credit spending explosion: Fivetran is known for being affordable at the beginning, but not scaling well price-wise.
Self-hosting engineering costs: Running Airbyte at a certain scale in a self-hosted environment requires setting up and maintaining a Kubernetes cluster. While feasible, this needs to be considered in the balance.
Custom connector costs: Many projects require custom connectors either because they don't exist or because the open-source connectors are not maintained properly.
As shared in the comments, I've seen many examples where connectors were not updated regularly and/or failed to deliver as expected.


For these edge cases, ELT tools usually provide custom connector builders.
While it's a possible path to follow, it's important to understand the limitations associated with these frameworks.


Or simply falling back to Python scripts for these last x% of non-standard data sources.
Which leads then to the second persona.
Team Build
Persona:
Limited standard sources
Difficult SaaS onboarding (security, procurement bureaucracy)
Tech-focused
I chatted with various engineers in DM who opted for the contrary approach, choosing to build their own ingestion.
This approach is motivated for contexts with a lot of nonstandard sources.
This is especially the case for companies where you need to ingest data from legacy systems with old database versions, or niche/internally-built APIs.
In these cases, leveraging the connector builder of SaaS tools is counterproductive.
DIY was often misunderstood as building everything from scratch.
However, in today's cloud, many building blocks are available for developers to manage the ingestion workflow easily.
Let’s take the AWS context:
Retry Management: Lambda partial batch failure + SQS dead-letter queue
Pagination: Step Function iterators
Backfill Missing Data: trigger lambda directly from your warehouse (e.g SF external function)
Observability: AWS Cloudwatch
Building a custom ingestion system becomes therefore easier by leveraging managed services.
And this becomes even easier with this new wave of lightweight ELTs.
pip install ELTs
A new wave of tools has been mentioned a lot in the comments: ELTs packaged as libraries.
They position themselves in the middle between no-code ELTs and code-heavy approaches.
This lightweight approach allows them to be easily embedded anywhere Python can run (Lambda, ECS Tasks, GitHub Functions, Snowflake Container services) and therefore leverage capabilities of managed services.
To name a few:


Even Airbyte has launched its initiative with Pyaribyte, where you can use some Airbyte connectors loaded from a Python library.


The library allows data duplication between databases with almost no configuration.

Event collector deployable on a Lambda

These tools offer an interesting compromise between no-code SaaS solutions, which might limit custom development, and building things from the ground up.
I appreciate the fact that you can deploy them in a Lambda and leverage all its features out of the box, such as observability, scalability, and retry handling.
Additionally, they are easily interoperable, allowing you to choose the best tool for your specific use case.
With today's tooling, a good balance between development / maintenance / credit costs seems to be achieved by mixing:
Standard connectors purchased from ELT SaaS providers.
Custom connectors built with lightweight lib’ ELT
The company's sourcing balance between standard and custom connectors will then determine whether the solution leans entirely towards one side or remains a mix of both.
Thanks for reading,
-Ju

I would be grateful if you could help me to improve this newsletter. Don’t hesitate to share with me what you liked/disliked and the topic you would like to be tackled.
P.S. you can reply to this email; it will get to me.
Hi! I enjoyed your article. I've done some exploration with this tool (Steampipe - and I'm not affiliated), and it might be of interest to you. Kind of fits with the "Agile integration" trend.
"Dynamically query APIs, code and more with SQL.Zero-ETL from 140 data sources."
https://steampipe.io/