


(R)evolution Of The Data Ingestion Layer
Ju Data Engineering Weekly - Ep 30

While the technology around data warehousing (DWH), with actors like Snowflake, BigQuery, and Redshift, is converging (they all copy new features from the others), the area upstream at the data ingestion layer remains fragmented.
Traditionally, the data world was familiar with the ETL (Extract, Transform, Load) process.
However, with modern cloud-based data warehouses with unlimited computational power, there's a noticeable shift towards ELT (Extract, Load, Transform) where most of the transformations are done in the warehouse.
Having said that, in reality, we often end up with a mixed approach where minor transformations are needed before data enters the warehouse:
complex JSON serializations that are challenging to code within the warehouse
aggregations of records to reduce warehouse ingestion costs
ect..
In this context, your chosen tool should be capable of:
Fetch and transform data of various sizes (batch, streaming) and formats (JSON, CSV, XLS, etc.) at different throughputs and from different sources (API, FTP)
Schedule and orchestrate these loads
Let's explore the available options in the current data vendor market.
3 Possible approaches
Classical ETL/ELT tools
For the past 20 years, the primary approach has been to use ELT tools such as Informatica, Talend, Fivetran, and more recently, their open-source counterpart: Airbyte.
They are particularly valued for their extensive connector libraries: If your data platform ingests data from traditional providers with pre-implemented connectors in these tools, they're likely a suitable choice.
However, if this isn't the case, these tools can be somewhat heavy in an ELT context.
A recurring issue is the inevitable discovery of missing connectors, leading to the need to write custom scripts within the tool — something that could be done without incurring licensing fees.
Scheduling tools ++
Over the past year, there has been a notable rise in powerful orchestration tools making their mark in the ETL space, offering advanced transformation capabilities.
Leading the pack are tools like Prefect, Dagster, and the more recent Mage.
At their core, these tools share a conceptual similarity: they allow for seamless orchestration and chaining of diverse tasks. Both Dagster and Mage offer functionalities particularly useful for data engineering tasks.
The dev experience is particularly good with these tools (+1 for Mage), allowing seamless local testing, deployment and monitoring.
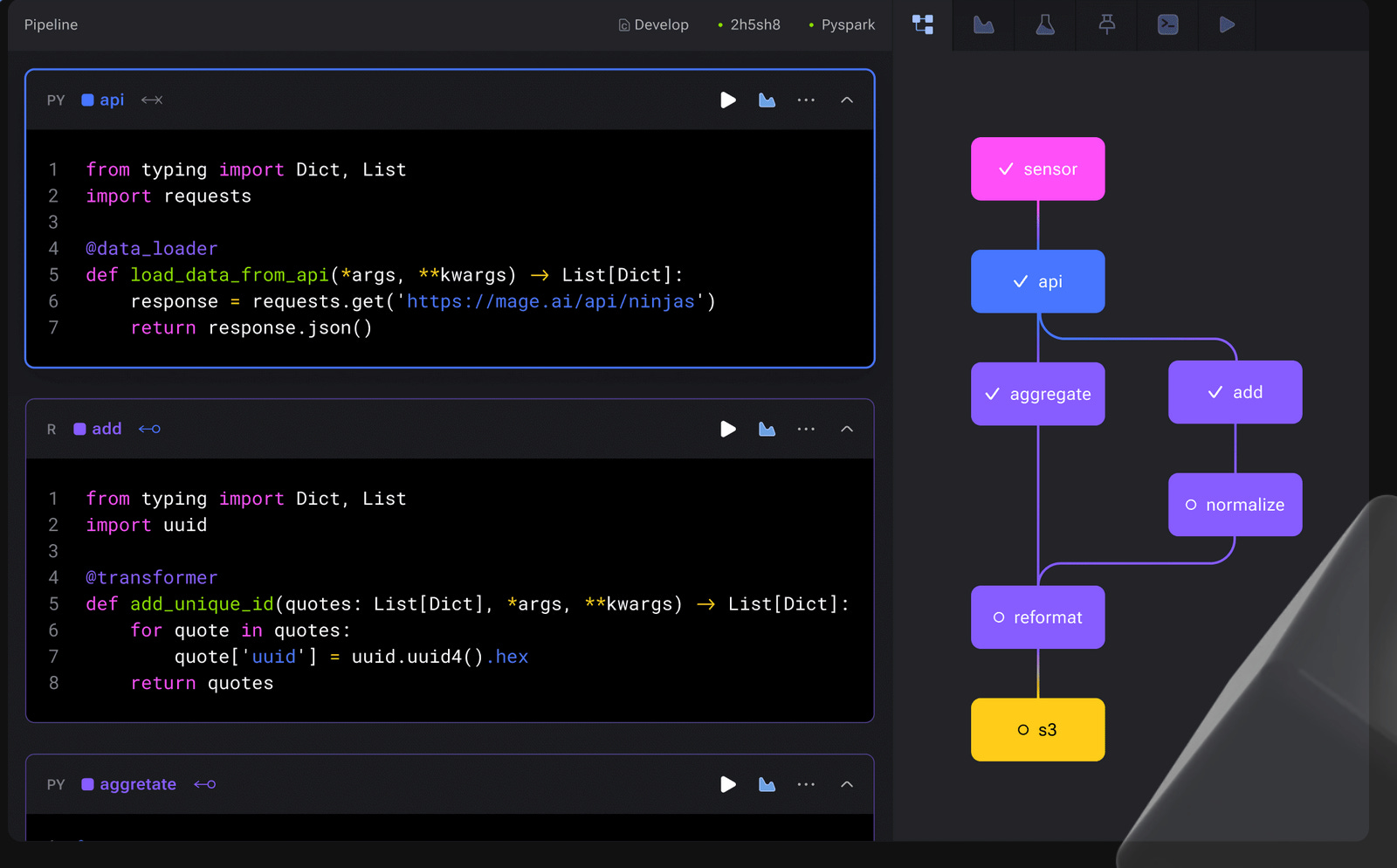
They are open-source, keeping their primary features free of charge. However, users face a choice: self-host or opt for the paid cloud version.
For numerous companies, the cloud version is off the table, mainly due to security considerations. This leads to the necessity of self-hosting.
The primary challenge with this approach is the requirement to manage a Kubernetes cluster to host the tools. This demands significant DevOps efforts, especially as your platform scales. As data ingestion and transformation needs grow, ensuring efficient scalability of computing resources can become a nightmare.
However, if you're able to use their cloud version, these tools are a solid choice, especially for quickly setting up your platform in its initial stages.
Managed Cloud Services
Another option is to capitalize on the managed services offered by your cloud provider.
I'm more familiar with AWS, so I'll base my explanation on their services. However, similar strategies can be applied with GCP and Azure.
AWS natively provides everything you might need:
Orchestration: Step Function
Compute resources: Lambda and ECS

These services are fully serverless, allowing you to significantly reduce your DevOps overhead.
With prior solutions, you're billed to keep your Kube cluster operational. In contrast, with serverless, if you're not ingesting data, there's no cost.
You can also easily adjust the computing power based on your task's requirements. For a more detailed explanation, refer to my post on Lambda vs ECS:
To lambda or not to lambda

The tech community is currently on fire with a debate following the announcement from Prime Video, which managed to significantly reduce its AWS costs by transitioning from a serverless architecture (Lambda and Step Functions) to a monolithic application.
While this method offers greater control, it lacks pre-defined connectors and building blocks and you will probably need to write and maintain more code.
In conclusion, when selecting your ingestion technology, here are my recommendations:
ETL Tools:
If you can leverage an ETL connector library, it’s worth investing in such a tool.
Cloud-Hosted Scheduler:
If an external SaaS solution is suitable for processing your data, begin with a cloud-hosted scheduler you will be faster.
Cloud-Managed Services:
For all other cases and more complex/custom computational needs (which is often the case for corporates), consider your cloud-managed services.
Thanks for reading,
-Ju
I would be grateful if you could help me to improve this newsletter. Don’t hesitate to share with me what you liked/disliked and the topic you would like to be tackled.
P.S. you can reply to this email; it will get to me.