Over the years, the industry has constructed layers upon layers to develop increasingly complex software.
The same trend is happening in the data world.
An increasing number of tools are emerging to standardize the construction of data pipelines, pushing towards a declarative paradigm.
Engineers spend less and less time coding and more and more parametrizing and coordinating functional building blocks.
In this cross-post with Benoît Pimpaud, we wanted to examine this trend from various angles within the stack:
Cloud processing: config-only event enrichment pattern with AWS Pipes
Data Warehouse: config-only table sync with Snowflake Dynamic Tables
Orchestrator: data pipeline templates (“Blueprints”) with Kestra
Thanks for reading Ju Data Engineering Newsletter! Subscribe for free to receive new posts and support my work.
Cloud Processing & Declarative Pipelines
The evolution of cloud infrastructure towards managed services has facilitated a shift toward a declarative paradigm.
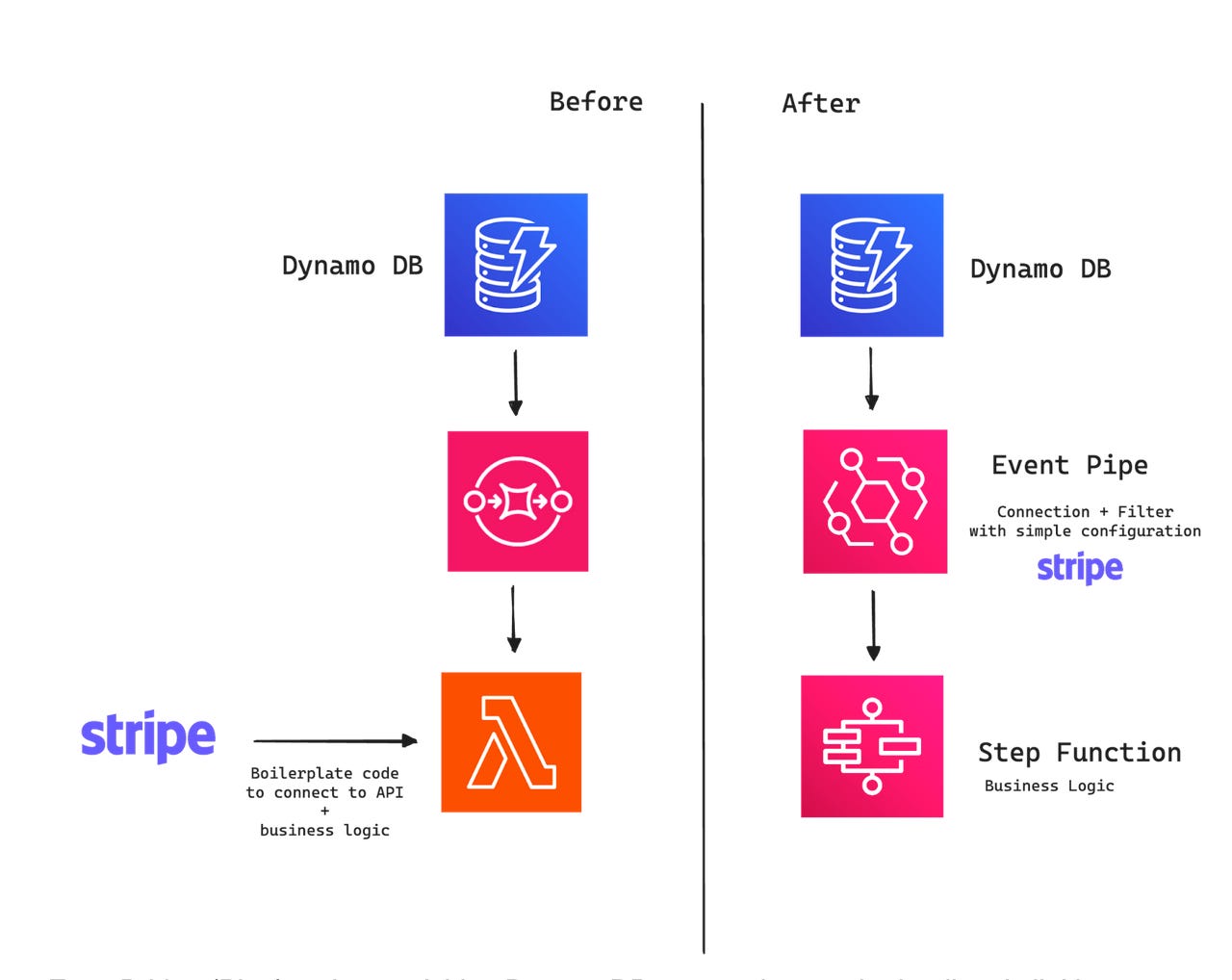
Consider a basic AWS workflow:
A customer places an order.
A record is added to a DynamoDB table.
A verification process checks if the customer exists in Stripe using Stripe's API.
A new Stripe account is created or not.
Previously, calling the Stripe API would have required setting up an SQS queue and a Lambda function.
The modern way to do it is to use AWS EventBridge, particularly the EventBridge Pipes feature.
This method eliminates the need for scripting: by configuring an API endpoint (URL and auth), EventBridge Pipes can automatically enrich an event with the result of an API call.
This approach cuts out the need for setting up queues and triggers, making managing data flow simpler.
Eventbridge Pipes creates a composable space where events-based triggers link pipelines together.
Even if you miss a bit that control plane, infrastructure abstraction from cloud services simplifies maintenance and speeds up development.
It’s only some configuration files to set up.
Your business logic is still made of some Python or SQL code (or whatever), but the orchestration logic is made of a few configuration files.
It’s easy to delete, to migrate and to replace.
Data Warehouse & Declarative Pipelines
Data pipeline abstraction is also making its way into the data warehouse world.
Warehouses are more and more offering constructs that data engineers can use to build data pipelines quickly.
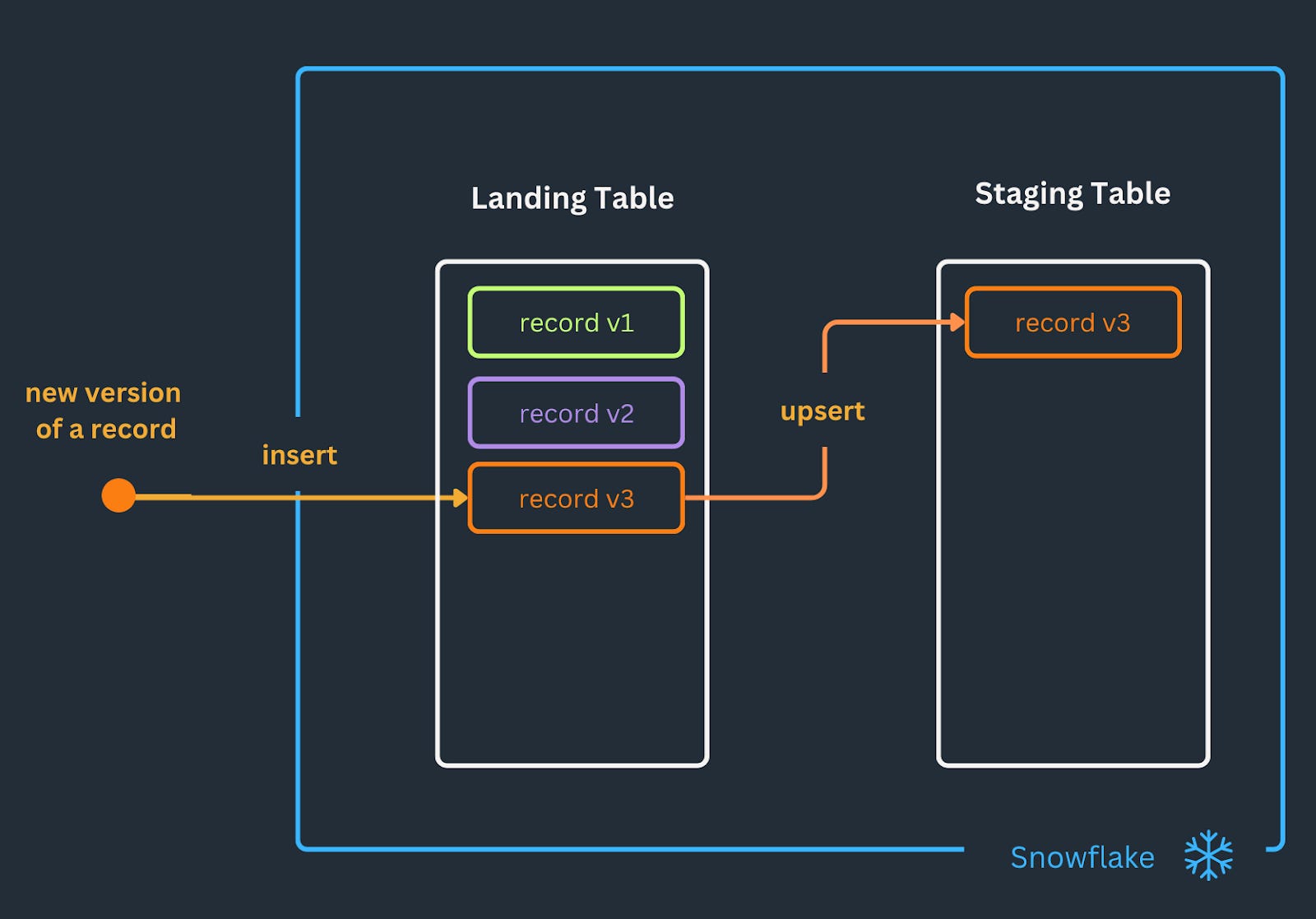
Let's examine a simple ingestion pattern:
Records are ingested into a landing table.
The staging table containing the latest version of each record is incrementally updated.
Previously, to track and integrate changes in the staging table, it was necessary to:
Create a stream to monitor alterations in the landing table.
Create a scheduled task to merge the stream's changes into the staging table.
Now, Snowflake has simplified this process with the introduction of a dynamic table construct.
Users are only required to set up a dynamic table and define its update interval: Snowflake autonomously handles the underlying update mechanisms.
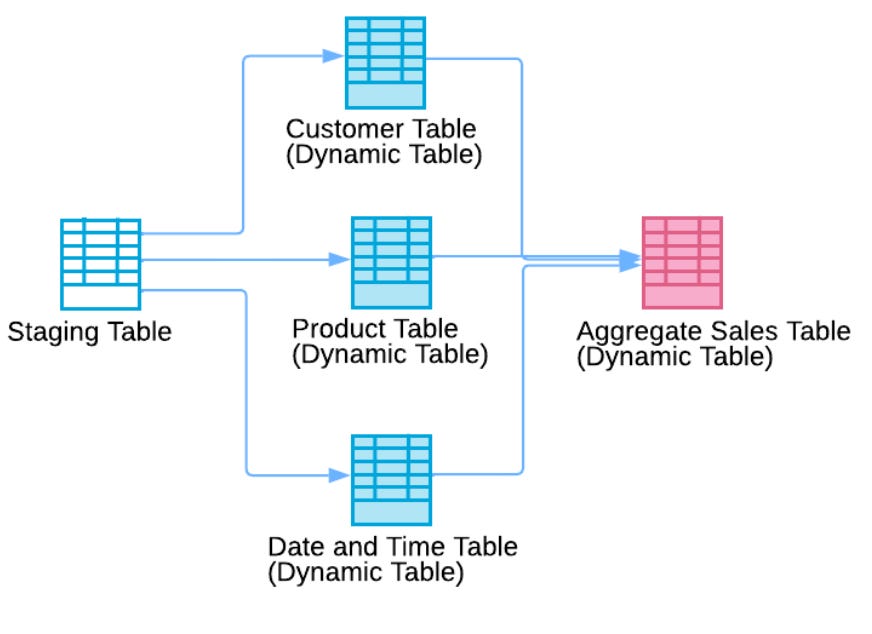
This significantly streamlines the code and enhances the maintainability of the data pipeline.
Additionally, Dynamic tables can be linked together to create end-to-end pipelines that automatically refresh themselves…
Orchestration & Declarative Pipelines
Orchestration is the control plane of every data stack.
Still, most of the tools from that category are primarily built either for:
Data Engineers (Airflow)
DevOps (CI/CD and infrastructure management systems)
Business users (drag-and-drop automation frameworks).
The declarative paradigm here isn’t just a trend: it's the realization that a proper domain system language is needed to bring people around the same table.
Kestra pushes a lot toward this direction by providing a lot of pre-build integrations and building blocks that are configurable via Yaml files.
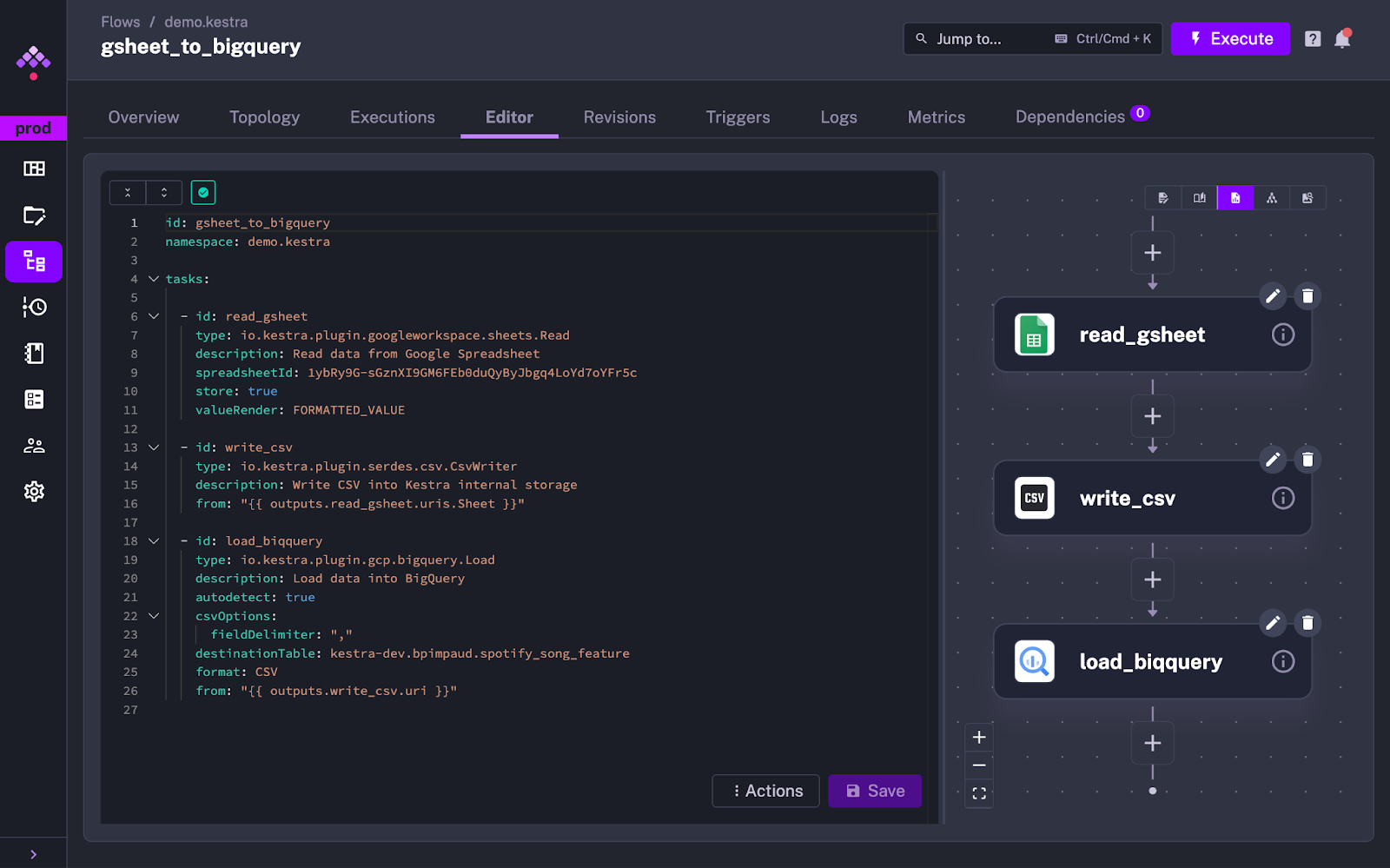
For instance, to load a Google Spreadsheet into GCP BigQuery, one can simply configure the pre-existing building blocks within Kestra:
Kestra supports a lot of different technologies: DBT, Airbyte, Python scripting, cloud provider services, etc.
Orchestration logic is done in YAML and users can connect any tool or use any scripting language (Python for example) to run business logic.
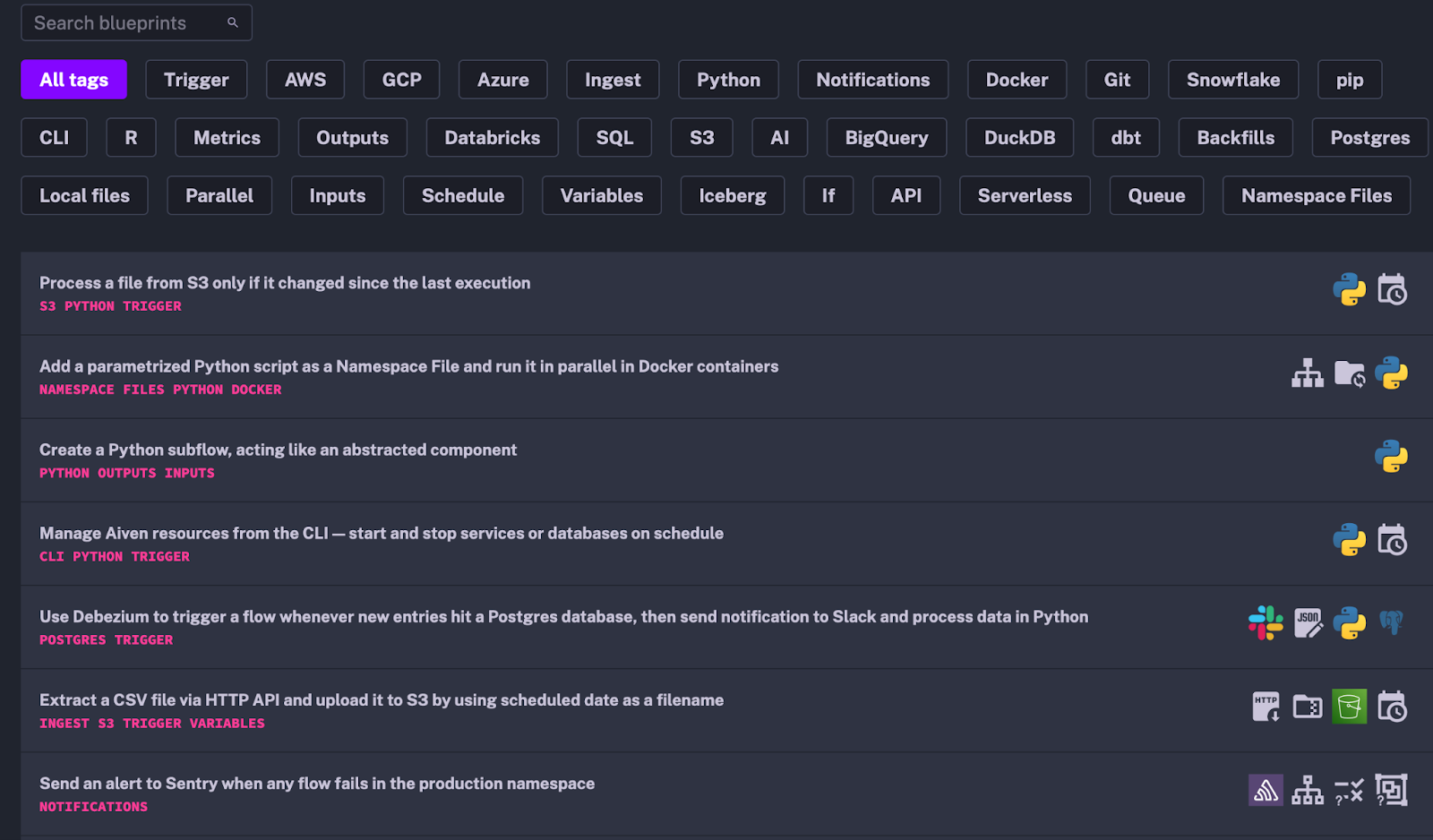
Additionally, Kestra offers a library of data pipelines, known as Kestra blueprints, which facilitate the rapid setup of new workflows.
Reusing configuration and adjusting to specific needs is then very straightforward.
Kestra’s library of pre-defined pipelines
Toward End-to-end Declarative Pipelines
As we have seen, abstraction is entering every vertical of the data stack.
However, this is likely to evolve horizontally as well.
Indeed storage standards are emerging:
Arrow for in-memory storage
Iceberg for data lake storage
and recently OneTable for cross-open table format conversion.
The adoption of unified storage solutions will enable all tools within the data stack to rely on a common storage layer, thereby facilitating the standardization of end-to-end pipelines.
Data teams might only need to specify (in Yaml?) the desired outcome, like:
"I want this external data merged with my internal financial data within a maximum delay of 10 minutes"
and the data pipelines would be automatically generated end to end.
This would free time for data teams to create new models and present them to the business without worrying about the underlying infrastructure.
In such a world, the cost of analytics will be dramatically reduced and data teams will become less of a bottleneck.
The remaining responsibilities of the data team would include:
Coding business-specific transformations.
Building data quality monitoring and alerting processes.
Implementing data governance processes, including data cataloging and data contracts.
Building a data stack is hard—too many moving pieces, too little time.
That’s where Boring Data comes in.
I’ve created a data stack onboarding package that combines ready-to-use templates with hand-on workshops, empowering your team to quickly and confidently build your stack.
Interested?
Check out boringdata.io or reply to this email—I’d be happy to walk you through our templates and workshops.
Awesome read. I am a big proponent of declarative and data-aware orchestration and the shift towards data product (see https://www.ssp.sh/blog/data-orchestration-trends/ if interested). DSL is the next layer of adding abstraction and automation to it. Thanks for listing it step by step and with an actual example.







Awesome read. I am a big proponent of declarative and data-aware orchestration and the shift towards data product (see https://www.ssp.sh/blog/data-orchestration-trends/ if interested). DSL is the next layer of adding abstraction and automation to it. Thanks for listing it step by step and with an actual example.
Excellent article, as usual! I like the brevity and useful examples that make it easier to understand the point being made