
From DuckDB to DuckHouse
Ju Data Engineering Weekly - Ep 84


Bonjour!
I'm Julien, freelance data engineer based in Geneva 🇨🇭.
Every week, I research and share ideas about the data engineering craft.
Not subscribed yet?
DuckDB has become well-known as a lightweight, portable, and fast OLAP database.
I've primarily seen it used for local testing and stateless computations.
While it excels as an embedded engine, could we push its boundaries further?
Could we build an actual data platform centered around DuckDB?
This post, written with Hussain, explores how to build such a stack and transform your DuckDB into a DuckHouse.
—
You can find the source code of this project here.
Note: This project is an exploration and is not production-ready.
Design
Here are the requirements for our DuckHouse:
We must support concurrent writers because we need multiple ETL jobs running simultaneously. This would also enable a single DuckHouse instance to support a multi-tenant setup.
Allow multiple concurrent readers to access data
The storage format must handle both small and large tables efficiently
Support seamless integration with dbt
Out of scope:
Governance and read/write limitations across users.
—
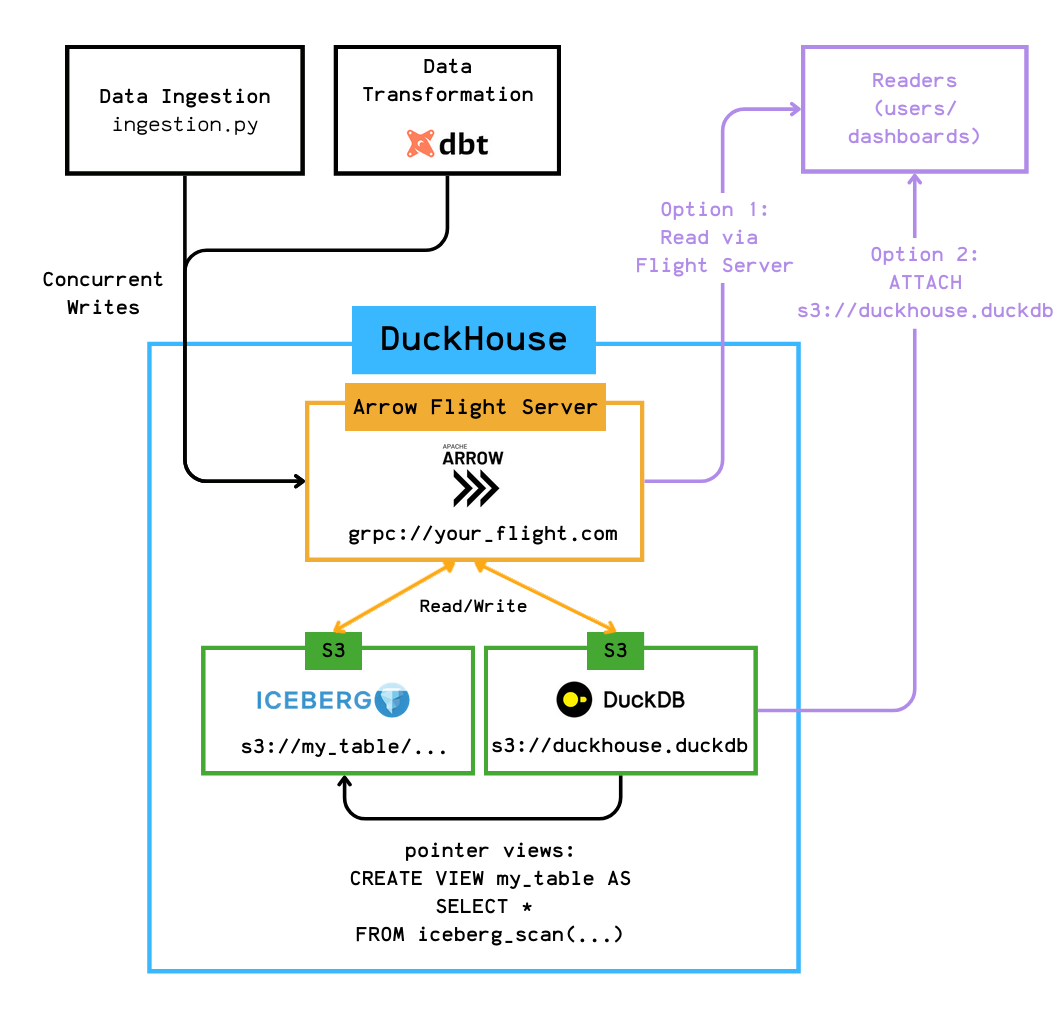
To address these requirements, we implemented a hybrid storage design:
Small tables are stored in .duckdb format directly on S3
→ e.g., s3://<bucket>/duckhouse.duckdb
Large tables (like events) are stored in Iceberg format on S3
→ e.g., s3://<bucket>/<table>/
This setup provides DuckDB's simplicity and performance for light workloads while scaling with Iceberg for heavy datasets.
Let’s dive in!
1. Arrow Flight
TL;DR
We implement an Arrow Flight server as a gateway to our DuckDB storage, solving write concurrency challenges.
DuckDB and Write Concurrency
Writing concurrency is likely the first challenge you’ll encounter on this journey.
DuckDB isn’t built to handle concurrent writes automatically—it only allows one writer at a time.

An external component must handle the concurrency control.
This is where Arrow Flight comes into play.
Arrow Flight Server
Arrow Flight is a modern alternative to REST APIs for data transfer.
It enables fast and efficient transfer of large datasets across systems using the Arrow format.
Traditional data systems require multiple conversion steps:
Server converts data to JSON/CSV
Data travels over the network
Client converts back to DataFrame
With Arrow Flight, data stays in Arrow format end-to-end, eliminating the need for conversion.
To solve our concurrency problem, we'll use a Flight server as a gateway for all write operations.
This server queues write requests and processes them sequentially to avoid any locks.
Xorq
Xorq is a declarative framework for building multi-engine computations in Python.
They provide a ready-to-run flight server that can be easily connected.
Running a flight server becomes as easy as:

The server supports SQL and Ibis expressions and provides pre-implemented methods across several backends (DuckDB, Iceberg, Snowflake, Trino, etc): create_table, list_tables, get_schema, and upload_data.
Here’s how to upload data, for example, to a server:

As mentioned in DuckHouse's requirements above, we need to support writing to either a DuckDB instance or Iceberg for data persistence.

This means we work with two backends: DuckDB and Iceberg.
We built for this PoC a custom backend on top of Xorq's native Pyiceberg and DuckDB backends:

The Flight server writes data to either backend based on the user-provided target parameter.
Additionaly, to maintain s3://duckhouse.duckdb as a single read entry point, whenever we write to an Iceberg table, we create (or replace) a DuckDB view that points to its latest snapshot.
2. Writing to the Duckhouse
TL;DR:
Data ingestion via the Flight server directly
Data transformation via dbt and a custom duckdb-dbt plugin
Let's examine how we interact with the Duckhouse for our two write use cases: data ingestion and transformation.
Data Ingestion
The most straightforward way to write to our new warehouse is to call the Flight server directly, as shown above.
This method serves as our primary approach for data ingestion.

Data Transformation
Once data is ingested, we run transformations using dbt.
For this, we use the powerful dbt-duckdb extension.

This extension runs your dbt project pipeline against an in-memory DuckDB database that won't persist after your run is complete.
It provides a super powerful plugin system, which allows you to enhance dbt and provide custom model read/write behaviors:

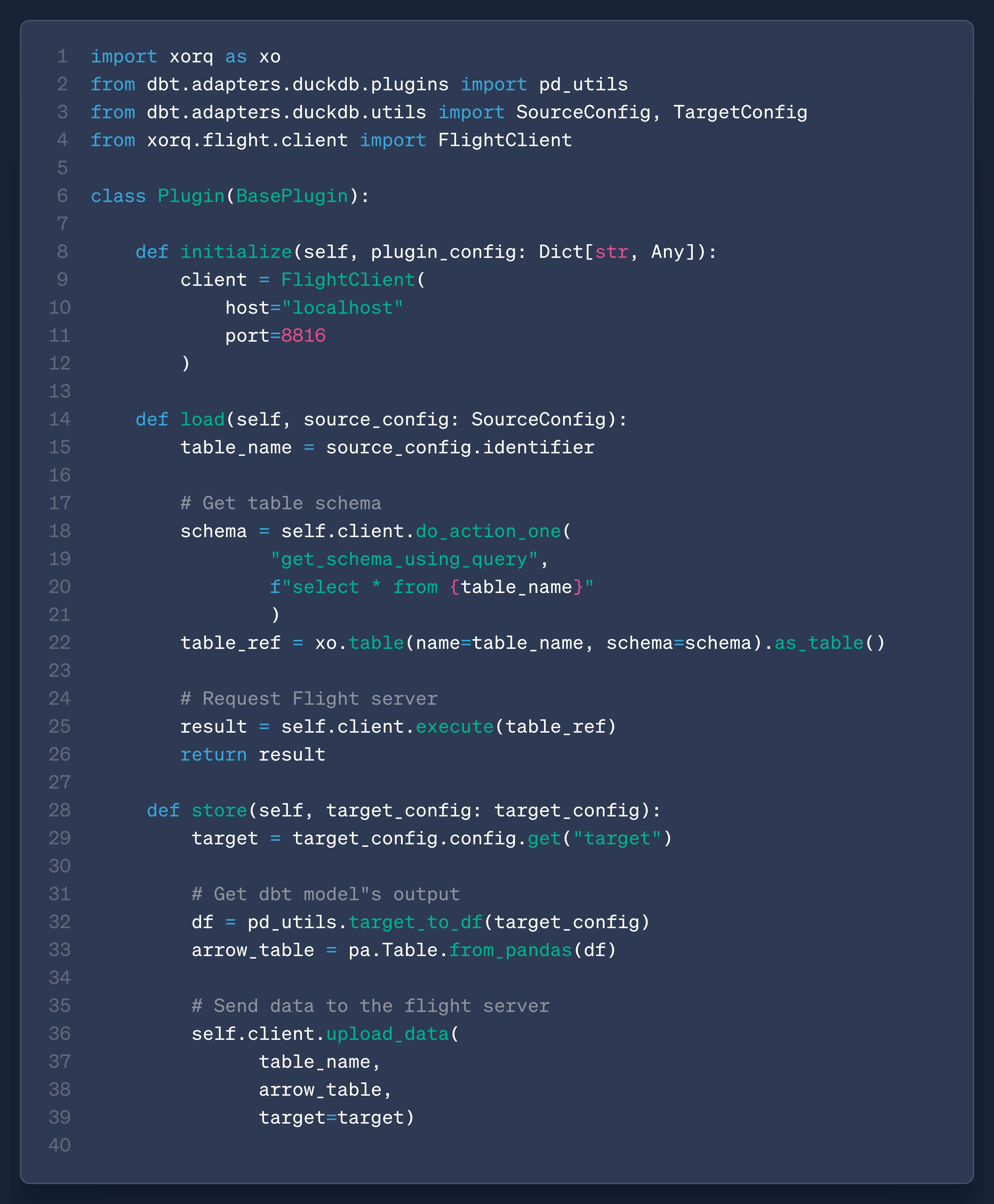
A dbt-duckdb plugin is a simple class that implements these four methods:
initializeconfigure_connectionload: used to load the sources of a dbt modelstore: used to persist a dbt model
Our plugin forwards the dbt read/write calls of each model to our flight server:
A dbt model looks like the following:

Depending on the model’s config, it can be persisted in any of these locations:
materialized="external"target = "iceberg"⇒ Model written to Iceberg
s3://duckhouse/my_table/materialized="external"target = "duckdb"⇒ Model written to our duckhouse
s3://duckhouse.duckdbmaterialized="table"⇒ Model written to the temporary in-memory DuckDB instance used by dbt
Reading from the Duckhouse
The read path is much simpler: you need to expose the duckhouse.duckdb file to your users.
They then need to open a DuckDB shell and run:

That's it!
Users can access both tables stored in s3://duckhouse.duckdb (tables) and Iceberg tables (via views).
The system is fully decentralized—users can query data and run computations on their machine.
Users can also directly access the flight service and use Xorq to perform computations if needed:

Example Pipeline
Let's look at an example pipeline.
First, we'll use an ingestion script to write taxi data to a landing table in Iceberg:

We can then check the data in the Duckhouse via a DuckDB shell:

Let’s create duplicates by rerunning the ingestion; we now have 6.133.532 rows.
We then create a simple dbt DAG:

The sources.yml points to the landing table we have just created:

We then have a first dbt staging model simply deduplicating the rows for the landing table:

This model is stored in Iceberg.
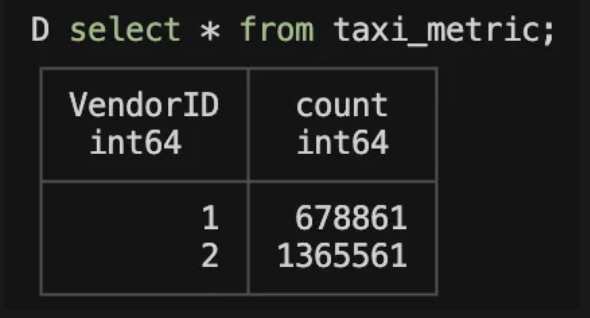
A third model computes a simple metric stored in DuckDB:

We run dbt run:

And that’s it !
We only need to run duckdb duckhouse and we have access to the 3 tables:

We can query the staging table in Iceberg:

And finally, query the metric in DuckDB:
Next Steps
I love this combination of Flight server, DuckDB, and Iceberg.
It’s a perfect compromise:
Light – requires only a single Flight server
Cheap – compute with DuckDB and 100% S3-based storage
Scalable – large tables live in Iceberg - any engine can process them
Several features remain to be implemented:
Flight server:
Add incremental read/write operations
Add MERGE support (currently append-only)
Handle table migration when the target changes
Iceberg:
Integrate with a proper catalog (currently using SQLite)
Enable partitioning and clustering configuration in dbt models
Additionally, we plan to leverage the Flight server to leverage interfaces with additional backends such as Snowflake, BigQuery, and PostgreSQL.
Building a data stack is complex—too many moving pieces, too little time.
That’s where Boring Data comes in.
I’ve created a data stack onboarding package combining ready-to-use templates and hands-on workshops.
Interested?
Check out boringdata.io or reply to this email—I’d be happy to walk you through our templates and workshops.

Thanks for reading, and thanks, Hussain, for the very nice collaboration.
-Ju

 | A guest post by
|
great Articles, today i have met cofounder, the http://linkedin.com/in/hfmuehleisen
Great article can’t wait to test it