It’s still very early (the extension is not yet listed) but has promising potential.
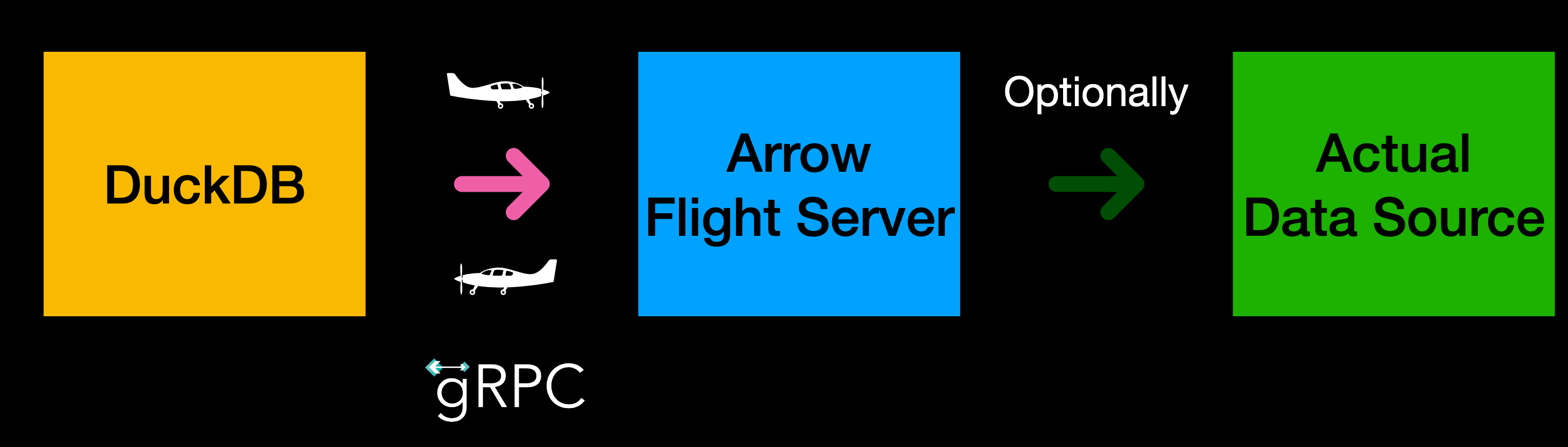
Note: The DuckDB team is actively working on improving extension development. At the beginning of this month, they released a C API to facilitate this process:
Snowflake + Snowpark
Now, let’s see what big cloud warehouse providers like Snowflake offer.
Snowflake is heavily SQL-centric—all features are packaged as SQL functions you call directly within queries.
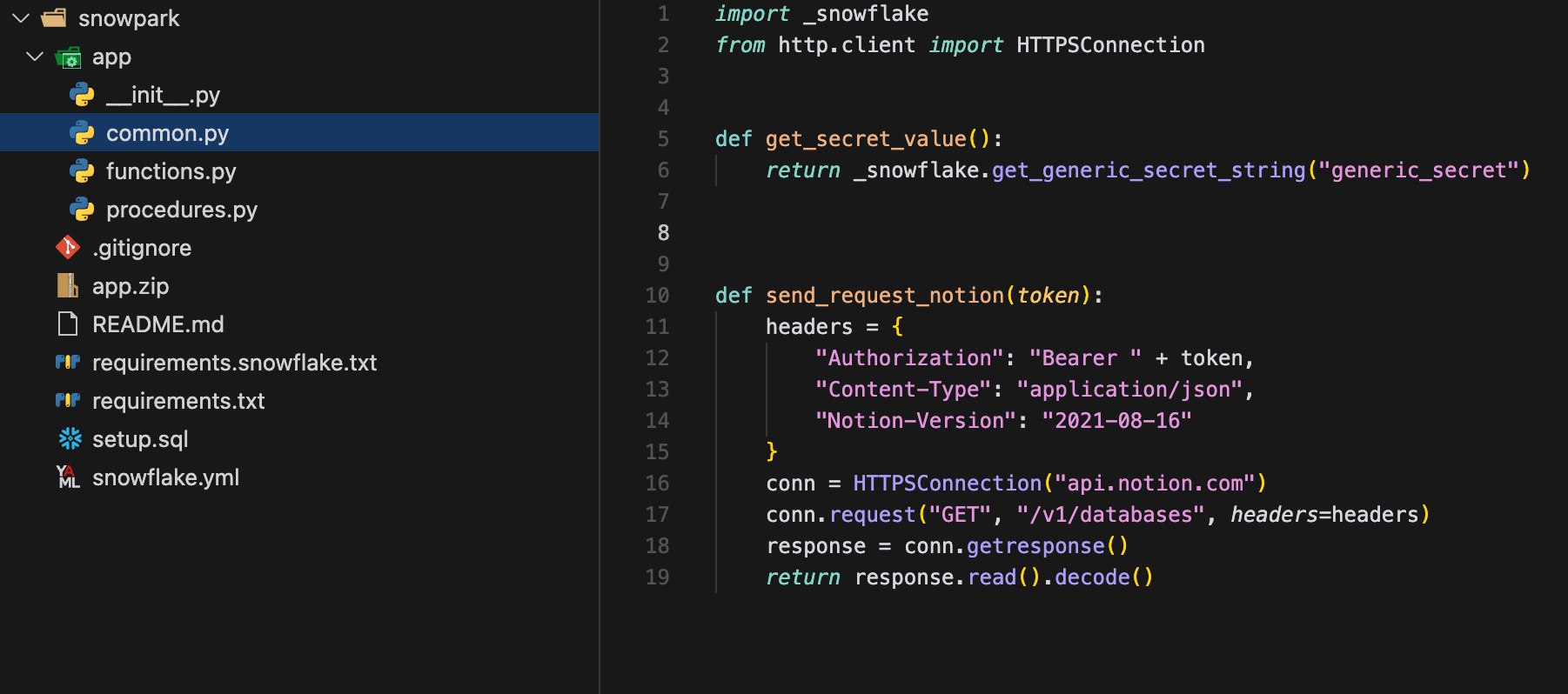
However, interacting with external systems often requires making API requests.
And API requests are much easier to handle in Python…
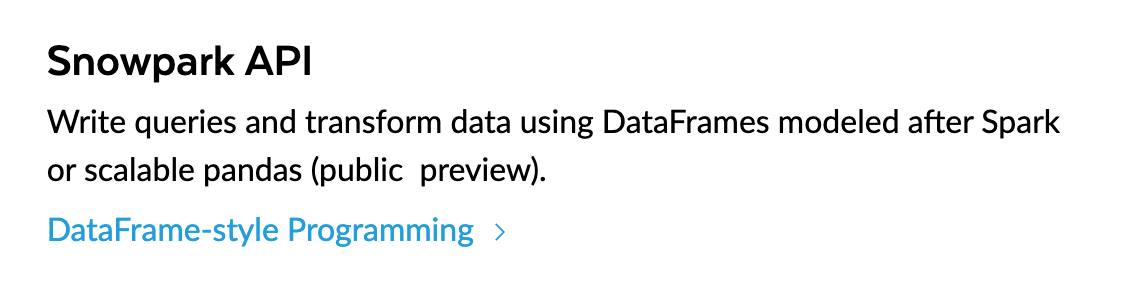
To support this, Snowflake provides a Python API called Snowpark.
While it’s marketed as a Spark equivalent within Snowflake, I believe its real superpower is acting as Snowflake’s version of AWS Lambda (at the other end of the compute spectrum 😊).
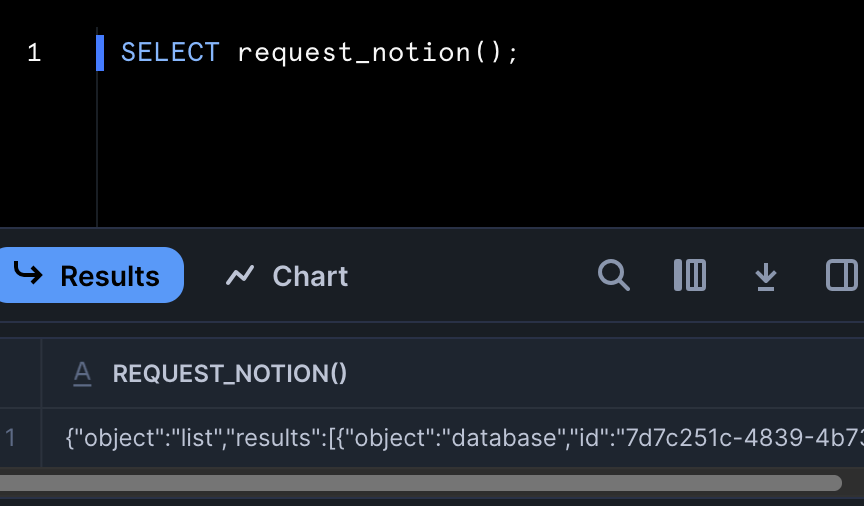
With Snowpark, you can quickly build custom SQL functions:
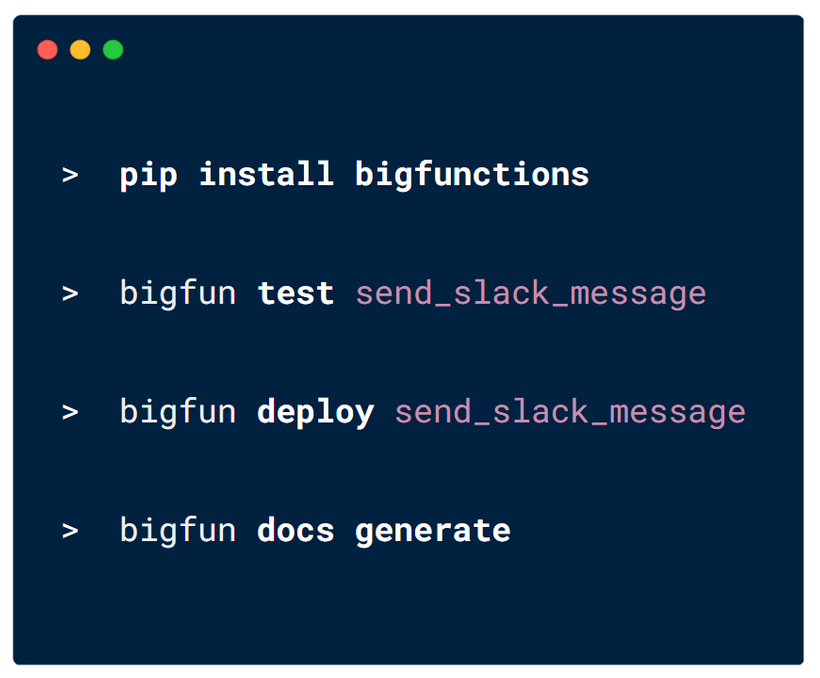
Paul, who works at Nickel, a French fintech, has integrated BigFunctions extensively into their workflows.
They use it to:
create Zendesk tickets
send data to Salesforce
send messages to Pub/Sub topics and handle client communications
send data to regulatory authorities
The best part?
Their data analysts can build these workflows end to end with dbt by triggering BigFunctions directly within their models.
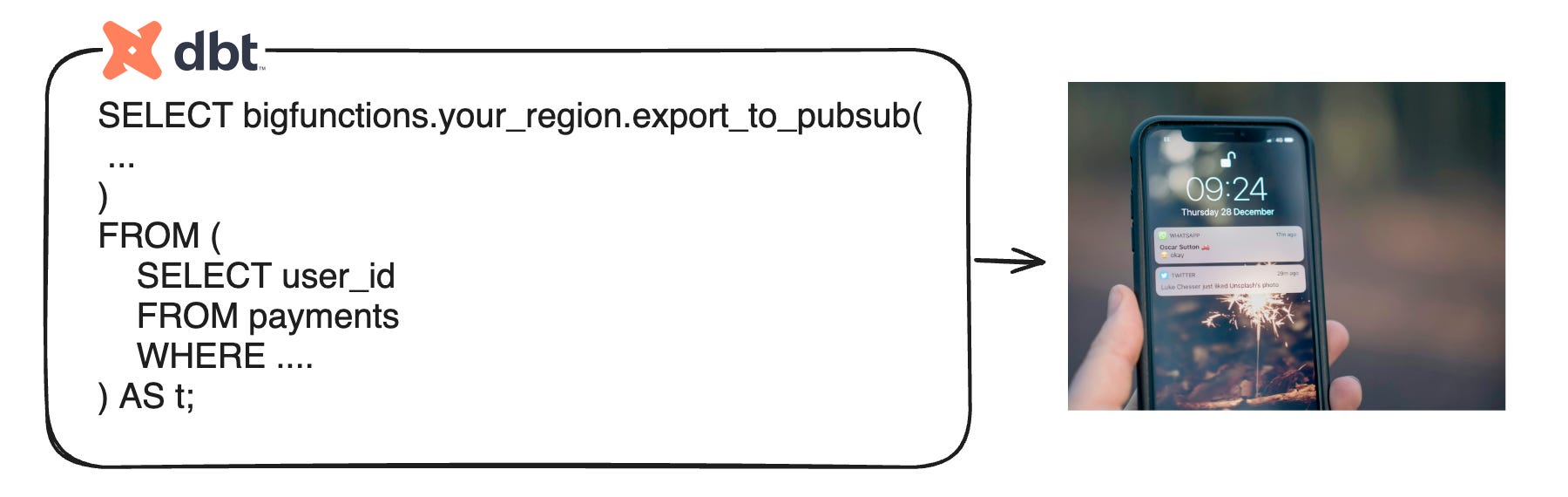
For example, if a user needs to receive a notification when a specific payment sequence of events occurs:
1. The sequence is calculated in a dbt model written by the analyst.
2. When materialization detects the pattern, the export_to_pubsub() function automatically triggers a notification on the user’s device.
No engineers are needed in the middle!
This is what makes this model so powerful—analysts can ship super fast:
• Analysts become fully autonomous
• They can ship new features independently
• Development cycles become faster than ever
Ultimately, this leads to more innovation and directly boosts the data team’s ROI.
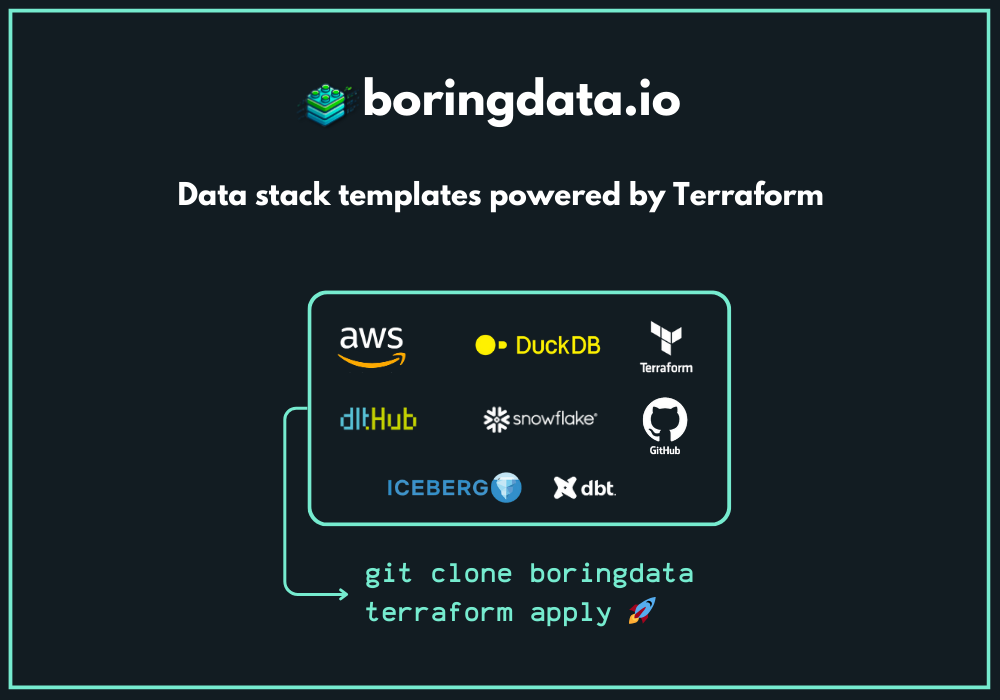
Building a data stack is hard—too many moving pieces, too little time.
That’s where Boring Data comes in.
I’ve created a data stack onboarding package that combines ready-to-use templates with hand-on workshops, empowering your team to quickly and confidently build your stack.
Interested?
Check out boringdata.io or reply to this email—I’d be happy to walk you through our templates and workshops.
Hi, thanks for sharing. Quite interesting. You emphasize analysts autonomy. But don’t you think there’s a similar risk as with the self-service BI? At some point all those actions without governance, standard practices (like CI/CD) knowledge sharing might backfire (and be dumped to the “not needed” engineers?)?













Hi, thanks for sharing. Quite interesting. You emphasize analysts autonomy. But don’t you think there’s a similar risk as with the self-service BI? At some point all those actions without governance, standard practices (like CI/CD) knowledge sharing might backfire (and be dumped to the “not needed” engineers?)?