
If AI Writes the Code, Where’s the Edge?
Ju Data Engineering Weekly - Ep 95

Bonjour!
I’m Julien, freelance data engineer based in Geneva 🇨🇭.
Every week, I research and share ideas about the data engineering craft.
Not subscribed yet?
Every week, a new model drops.
Last week, we even got two.
Models keep getting better.
And somehow, so does my anxiety.
January was a strange month:
Wow moments: crazy productivity gains.
Ouch moments: watching more and more of the value chain get eaten by a couple of players.
The question I’ve been obsessed with lately as a consultant and entrepreneur:
Where is the value now?
How do you build anything defensive at all?
Software as Specs
plan → implement → validate
What’s becoming clear: there is very little defensible value left in implementation.
LLM are much better, faster, resilient that us to write code.
But what about the spec side ?
LLMs are excellent at doing. They are much worse at structuring.
If you let them loose without constraints, you get:
- JSONL files scattered everywhere,
- massive, unreadable code files,
- implicit conventions no human would ever agree on,
- “it works” systems nobody dares to touch.
Why ?
Because structuring requires understanding a company context, an ecosystem context, and a problem context. That context exists in the real world — and AI doesn’t have direct access to it.
That asymmetry is our edge: we perceive the environment, understand the vision and constraints, and the agent implements the solution. This is likely where a true defensive moat can be built.
And I think this implies we should rethink how we distribute our knowledge.
Previously, as consultants or entrepreneurs, we delivered value through code and implementation. Now, perhaps the leverage shifts toward delivering specs — not the software itself.
To illustrate this “spec-only” shift, I came across an open-source project last weekend that contains … only four md files:
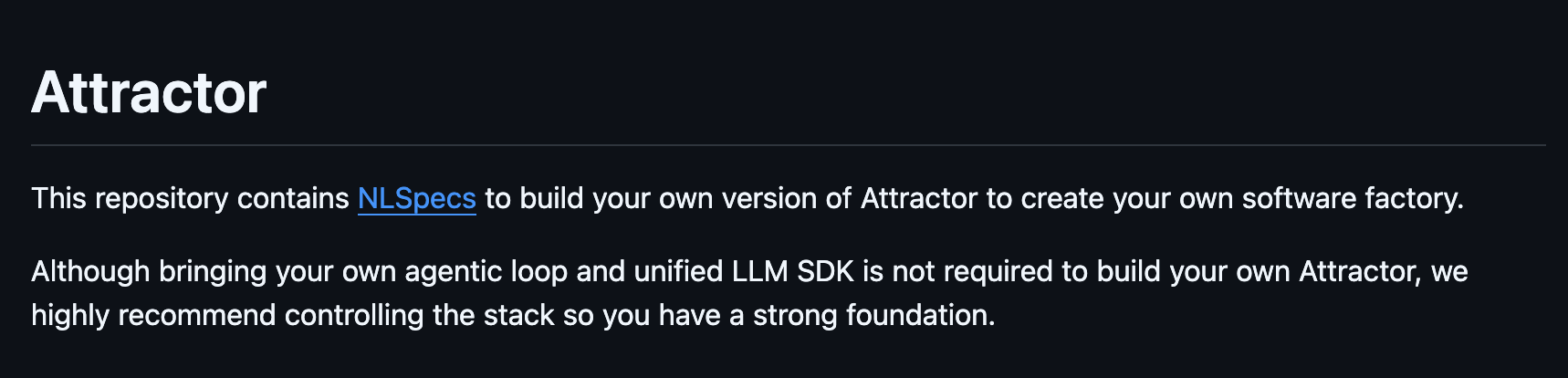
The provider delivers specification, invariants, constraints, and intent.
The user (and their agents) handle customization, environment-specific choices, and ownership of the implementation.
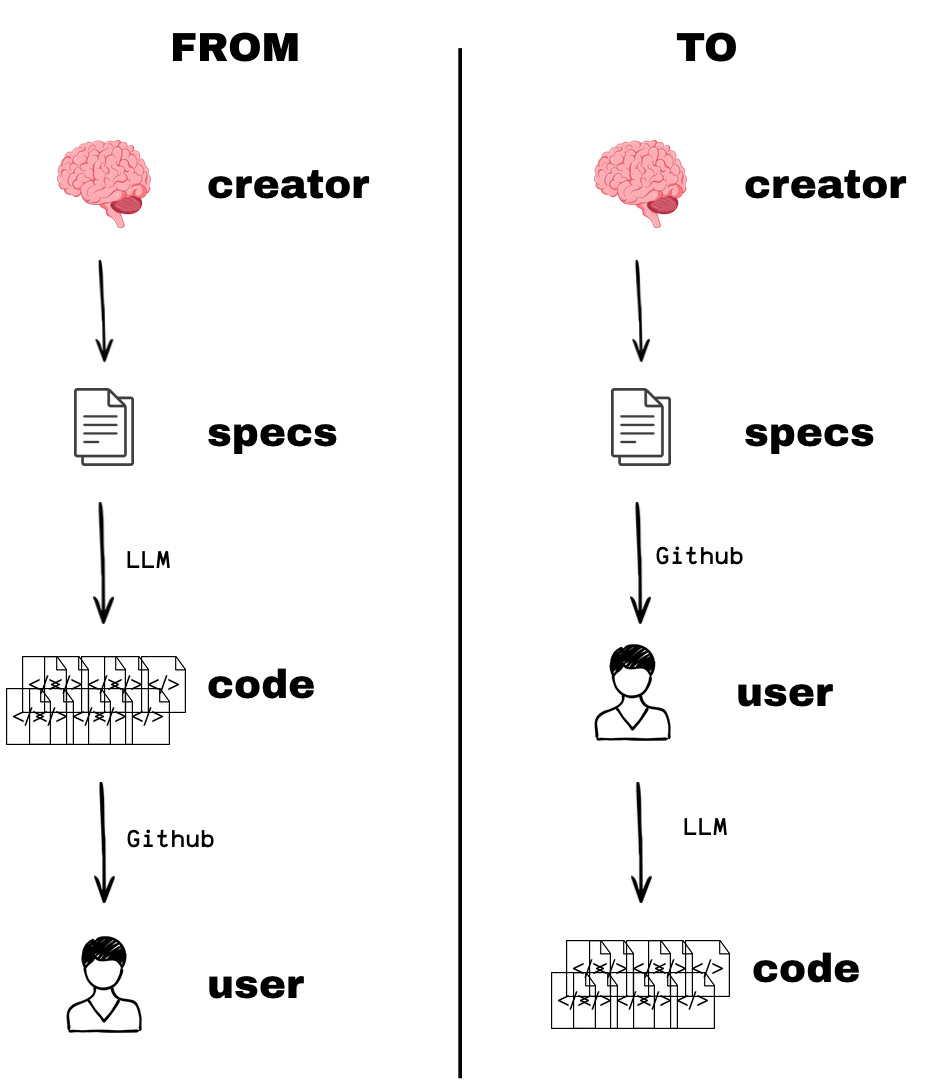
If implementation is just a commoditized expansion of a plan… why distribute the expanded form at all?
IDE for X
In the last 12 months, I’ve moved from code writer to agent orchestrator.
This new abstraction has materialized in a shift in my tooling. My development tools have changed focus: from an IDE to an Integrated Review Environment.
My IDE is now mostly a diff viewer.
tmux has become my multi-agent chat manager.
There’s no reason this evolution should apply only to developers.
Many SaaS tools today are rigid workflow builders — forms, and if you’re lucky, a drag-and-drop canvas.
But I think there’s an ocean of opportunity to build workflow-specific, agent-centric environments:

Such tools would focus on two core tasks:
Context gathering — collecting files, artifacts, documentation, and rules.
AI-generated artifact review — validating and refining what the agent produces.
For example:
Accountants provide a set of transactions and review the finalized company balance sheet.
Marketing teams provide company documentation and review generated content (blog posts, LinkedIn posts, campaign drafts).
Doctors input patient observations and review the proposed diagnosis.
Teachers upload learning objectives and review the generated teaching materials.
There’s no reason developers should be the only ones having all the fun 🙂
Inter-agent distribution
OpenClaw — and especially Clawbook — are showing us something important: a new agent-to-agent market is emerging.
Right now, only one side of the transaction is truly LLM-powered.
The user searches for a product through ChatGPT (or another assistant). The demand side is agent-augmented but the supply side is still mostly human-optimized: websites, dashboards, forms, traditional SaaS interfaces.
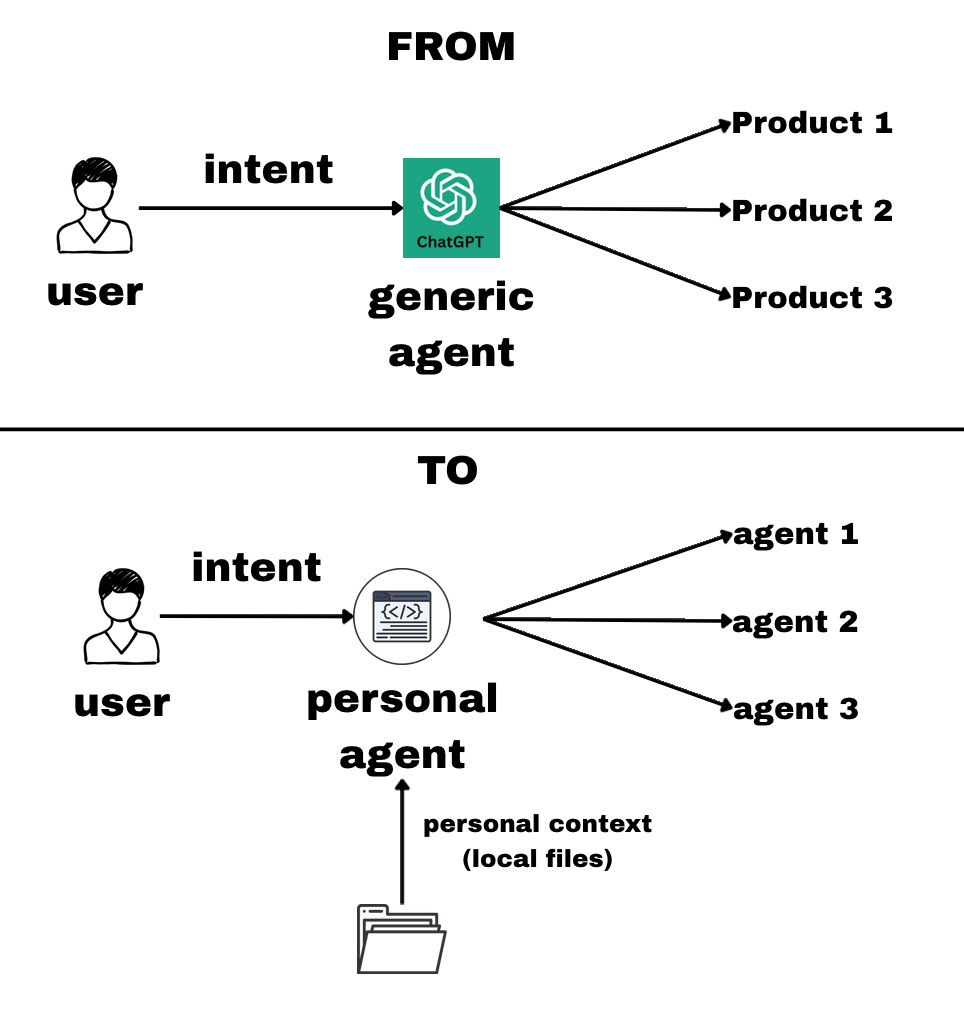
We all understand by now that LLMs are only as good as the context we provide them.
If an agent has access to your emails, files, Notion, and internal documentation, it becomes dramatically more powerful. It doesn’t just answer questions — it acts.
And this new generation of local-first agents is essentially coding under the hood. Which means they prefer interacting with systems that are agent-native, such as:
CLI interfaces
MCP servers
API-first services
They don’t need visual interfaces.
They need structured, programmable access.
When your personal agent researches, compares, or integrates services, it will naturally favor tools that require less effort — and fewer tokens — to use.
That’s why I think there’s opportunity in transforming services built around human UIs (web apps, dashboards) into agent-native interfaces (CLI, MCP, APIs).
The intelligence embedded inside the user’s agent (Claude Code, local agents, etc.) handles the final-mile customization — adapting your service to the user’s specific context.
That level of personalization — grounded in the user’s own data and environment — is extremely hard to compete with.
To illustrate this: Stripe is moving in that direction and has released an agent charging feature.
So these are the areas where I see opportunity in the coming months.
I’m starting to see signals that the market is moving in these directions, as I tried to illustrate with a few examples.
Let’s see how it plays out.
One thing, however, feels certain:
Value is concentrating in the hands of a small number of companies — and even individuals.
And it’s becoming harder and harder to compete…
I am launching a new podcast with blef :)
The idea?
Everyone is trying to figure out how to get the most out of all these AI tools.
With this podcast, we want to share what we’re discovering — and invite guests to explain how they use AI in their day-to-day work.
“How Do I AI?”
The first episode is in French, but we’ll also be releasing episodes — and inviting guests — in English.
We’ll keep improving things episode after episode, so don’t hesitate to share your feedback.
Thanks for reading,
-Ju

I agree agents are a game changer for productivity, but they still seem to always be behind the times, for example, when working on new Databricks features, I have to constantly feed relevant docs and examples, say "No, do it this way," or "Read this".
Also, I find that unless the data engineering task is simple to mid, they tend to write so-so code, and given what they are trained on, it's not a surprise. I find it's like dealing with a junior to mid-level engineer, with me saying, "Are you sure you want to do it like that?"
The future is bright, I think, for those data engineers who can build AI systems and be systems and architectural designers.
Issues I see with specs. (text) only:
- Human are not very good at writing/reading a big bunch of text and keep the full context (our brains don't have 1M token window). Switching from specs to code doesn't fix the cognitive overload though. A 100k-line codebase is also too big to hold in our head. The real question isn't text vs. code in the end, it's: what representation lets humans reason about intent at scale?
- English is a terrible programming language (programming in the broader sense here) https://orbistertius.substack.com/p/english-is-a-terrible-programming. Writing code was mainly for human to read (our future selves/teammates). But reading code is complex because the semantic is dense (vs. a bunch of sentences where the meaning is not "compiled" by every human the same way)
I am not saying "specs are bad" but more that we don't yet have good representations of design decisions that survive the transition to AI-generated implementation.. yet. Or we should all improve our writing/reading skills to be better at thinking/designing and expose our intent. (kinda resonate with https://boz.com/articles/communication-is-the-job)