


Create Promo Videos In Minutes: The Magic of Stable Diffusion
Data Eng Weekly - Ep 23

This week, I had the opportunity to create a demo video for a non-profit documentary project I'm supporting.
Despite having no background in design, I was able to produce a decent video in just 10 minutes using Stable Diffusion:

Not so long ago, creating such a video would have demanded several hours of a professional designer's time.
Today, however, anyone can achieve this with very few resources.
With this article, I want to present the world of image generation that I've been exploring over the past few months with Interiobot.com, using this small side project as a case study.
Diffusion models
Last year, a company named Stability AI introduced an open-source version of a model architecture known as diffusion models.
These models enable the user to guide the generation of a new image using a specific prompt.
It's the same kind of technology that powers services like Midjourney or Dall-e: the user provides a prompt (description of what he expects) and the algorithm generates an image.
What's impressive about Stability AI's model is its accessibility. It's completely free to use. You can download it onto your computer and start experimenting with it right away. This makes it an incredibly useful tool for anyone interested in image generation.
Some interfaces have been created to facilitate the usage of these models. Let’s have a look at some free ones.

This tool is very popular in the open-source world.
It's like Photoshop for image generation.
It includes many of the newest models available and the possibility to combine them easily.
It's very strong, but the user interface is not great.
I would primarily recommend this tool for people willing to dedicate some time to understanding and working with it.
Hugging Face serves as a platform housing a wide range of open-source machine-learning models. It’s kind of the GitHub of the machine learning world.
Not only can you host your model weights there, but you can also display a Gradio interface (web interface) to let others use your models.
Even though the customization options are somewhat limited, you can still try out various models and gain a preliminary understanding of the type of outputs you can expect.
For this project, I would recommend using this Hugging Face space to start playing with stable diffusion.
Here is the model you can use for this use case.
Controlnet
The primary issue with services like Midjourney and Dall-e is the lack of control over the image generation process.
These services are fantastic for crafting entirely new images, but they fall short when you need to update an existing image or control certain elements.
In this case, I needed the project's logo to remain consistent throughout the generated images.
The open-source community has developed a solution for this issue known as ControlNet.
ControlNet allows you to constrain the diffusion process with various conditions derived from your original image.
For instance, I used a condition called "Lineart" in this example. This condition identifies all the lines from the original image and ensures they remain consistent during the image generation process.
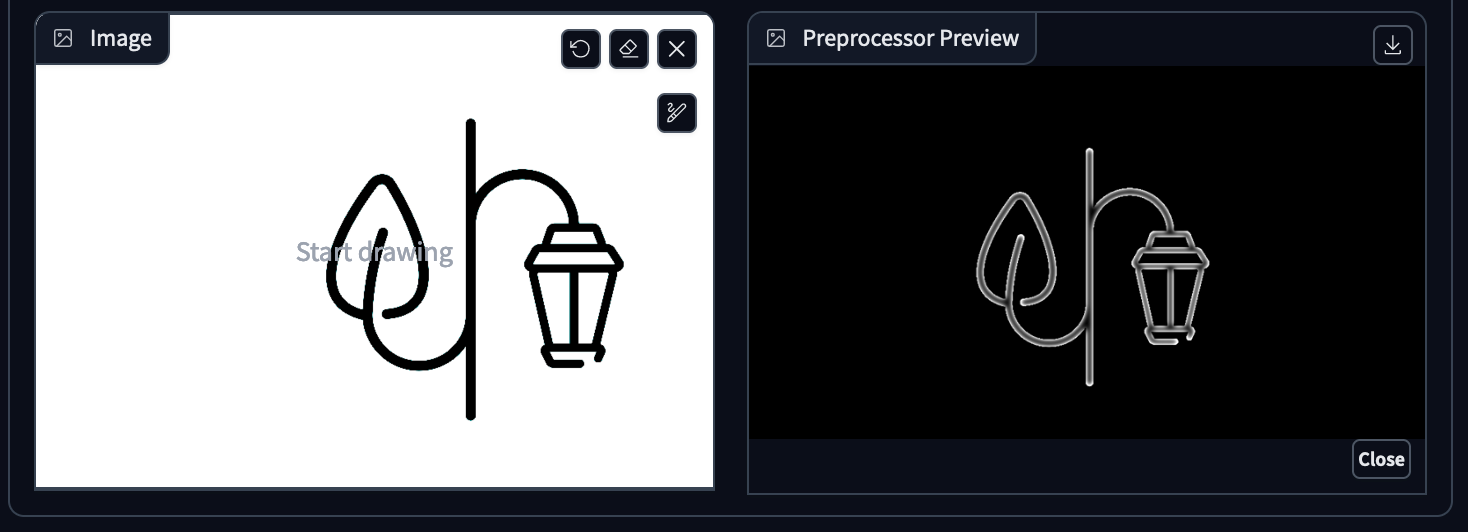
The image on the left is the original one, while the one on the right is the condition used by the diffusion model.
You can give this constraint in the Gradio interface and then append a prompt that describes the image you desire:

For instance, if you supply "aerial, desert" as the prompt, you would obtain the following result:

We see that the diffusion model has respected the condition during the diffusion process.
A lot of different constraints exist:
depth of the image
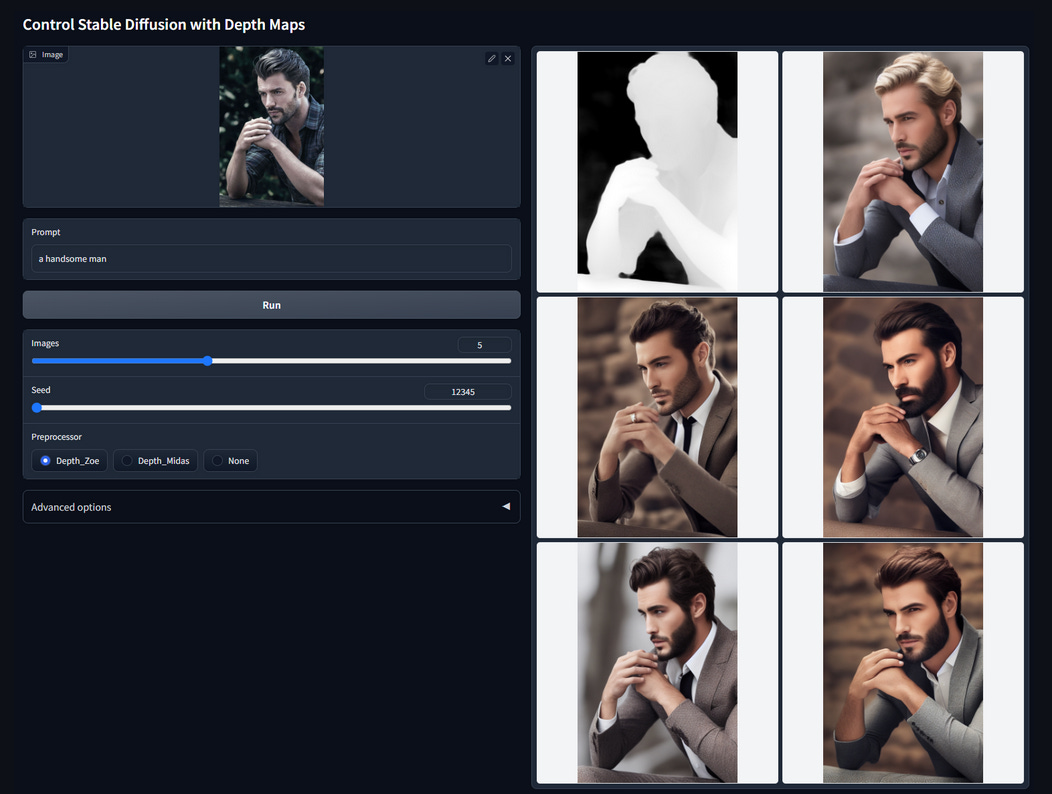
normal plans

segmentation
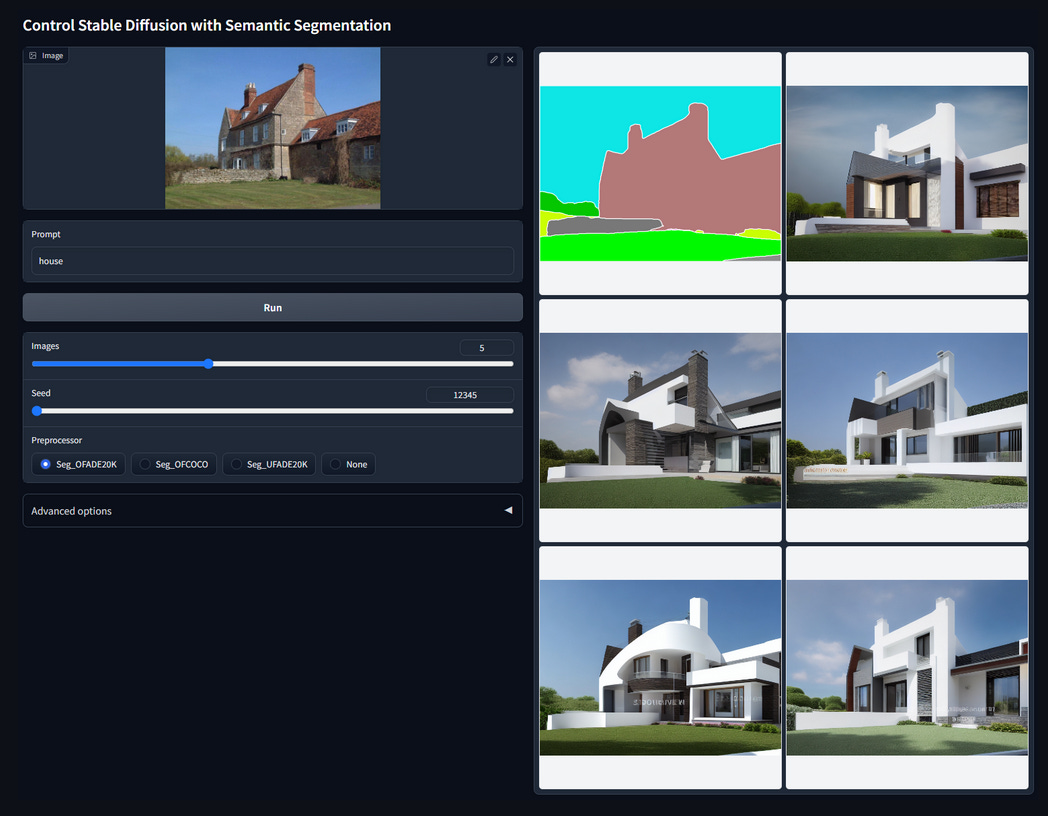
and much more…
The challenge in the image edition process based on stable diffusion is to put enough constraints on the algorithm to respect some aspects of the image but still provide him enough free space to get inventive.
If the pattern you provide him is too complex, the algorithm won’t be able to combine generation and at the same respect your constraints.
It’s a fine-tuning process that involves a lot of tries and errors.
Using this line constraint I was able to generate 10 images with different prompts:
aerial, forest
aerial, city
aerial, parking
ect
I then simply merged them using a GIF creation tool and voila!
In just 10 minutes, I was able to craft this simple promotional video.
I hope this article has provided you with some insight into the current world of image generation.
Thanks for reading,
-Ju
I would be grateful if you could help me to improve this newsletter. Don’t hesitate to share with me what you liked/disliked and the topic you would like to be tackled.
P.S. you can reply to this email; it will get to me.