
Manifesto for a Better Dev Experience
Ju Data Engineering Weekly - Ep 45

In recent months, economic constraints have put increased pressure on the efficiency of data teams.
The industry focus is shifting from adding new tools to the stack to improving the efficiency of existing platforms.
In my view, one of the best ways to reduce data team costs is by minimizing the time engineers spend on low-value tasks.
Reflecting on my time allocation as a data engineer, I feel frustrated by the hours consumed due to inadequate tools or poorly designed developer experiences (DX).
This blog post lists wished-for solutions and recurring pain points in the dev experience that I've observed across various platforms.
This list closely aligns with my own experiences and those of my clients.
If you have tools or methods to address these inefficiencies, please don’t hesitate to comment on this post!
Dev Experience Wish List
Local code testing
Infrastructure as Code (IaaC) is fantastic, but it comes at the cost of reduced iteration speed, which is crucial for rapid deployment.
As a developer, I want to develop and test my code quickly on remote data without having to wait 5 minutes for a continuous integration (CI) process to run.
Yes, it's possible to mock cloud services (e.g. Moto for AWS) or even emulate AWS locally (LocalStack), but this often results in a significant amount of time spent on unnecessarily complex tasks.
Initiatives that I appreciate in this area:
Prefect: Offers a unified experience for orchestration, both locally and remotely.
SST: An IaaC framework designed for web app development that enables local debugging of Lambda functions. It reroutes all incoming traffic to the Lambda function to your local machine, allowing you to debug locally your code with real cloud events.
Code testing on prod data
Fully segregated development environments is a legacy of on-premise engineering often lead to discrepancies between dev and production data.
For that reason you cannot be 100% sure that your code is working before merging to prod in this kind of setup.
In my ideal setup, I should be able to test by code on prod data directly without worring about disturbing the prod.
Initiative that I appreciate in this area:
Snowflake 0 copy clone where you can easily duplicate the prod database to develop your feature:
CREATE DATABASE FEATURE_X CLONE PROD_DB;Easy Environment Switching
Data platforms are usually separated into different environments which correspond to distinct accounts, but switching between these can be cumbersome.
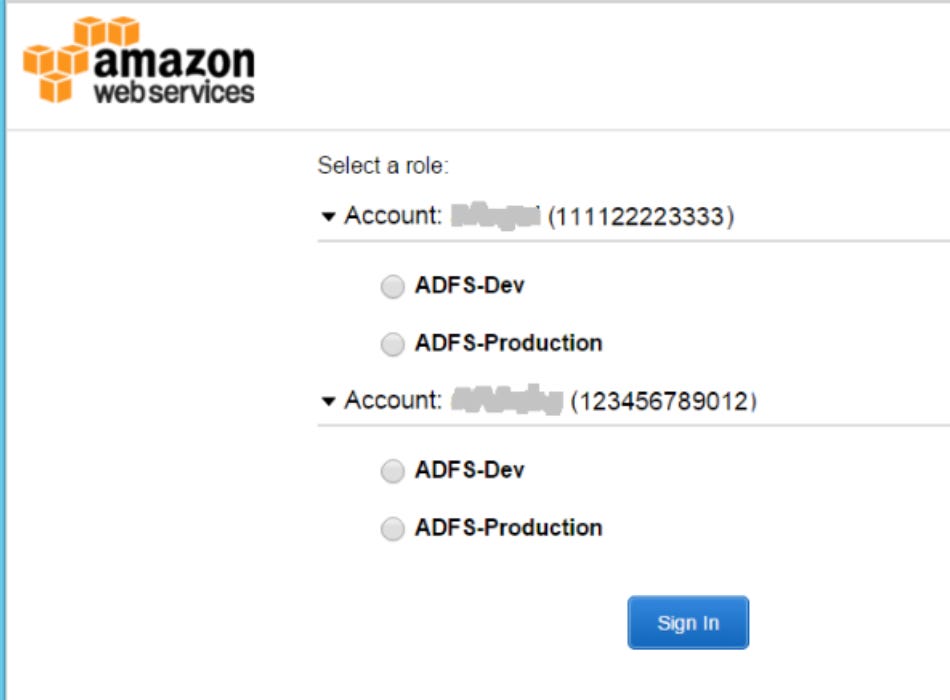
This problem seems stupid but as most tools live in the browser (e.g AWS Console), it takes so much time to simply switch between accounts.
One hack is to use the private browsing window to have several sessions at the same time, but yeah … we can hope for something better.
Easy data lookup
As a data engineer, we frequently work with files stored in a blog storage system (e.g. S3), and I find the developer experience to be terrible.
Indeed every time that you want to have a look inside a file you need to:
start a notebook/python file
(get your AWS creds?)
(google boto3 API)
(google pandas API)
and lose x minutes of your time.
What I wish for:
easily search S3 keys (and please AWS, not only with prefix !!!)
write SQL directly in the browser to query S3 files
Initiatives that I appreciate in this area: blef demo using DuckDB within a Firefox extension to display statistics about Parquet files located in GCP.
Easy replay and debugging
I personally heavily rely on debugging with breakpoints in VSCode to quickly understand code and bugs.
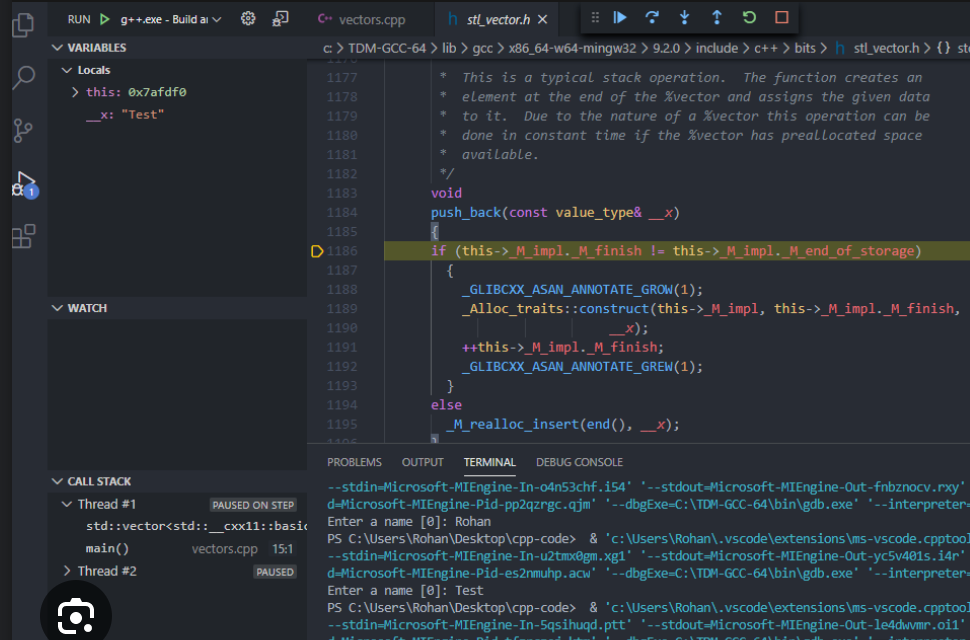
However debugging is often impossible or really hard to setup for many tools:
AWS Lambda debug (in console directly?)
DBT macro debug
I wish data tools would make it easier to debug pipelines with breakpoints to quickly understand what is going on.
Actully, I dream of a tool that enables me to come back to the precise breakpoint where the code failed, providing the entire context for analysis.
Yes, it may seem like a dream, but somehow I don’t understand why nobody has fixed this yet.
Inspiration in that space:
Snowflake time travel:
SELECT * FROM my_table BEFORE(STATEMENT => '8e5d0ca9-005e-44e6-b858-a8f5b37c5726');Get inspiration from the web industry
I began working on a SaaS project a few months ago, which led me to dive back into the web development industry.
I was amazed by the quality of the developer experience offered by some tools in this field:
Tailwind CSS: “Rapidly build modern websites without ever leaving your HTML.”

Vercel: “From localhost to https, in seconds”

Supabase: Postgress Database + Auth + Storage in one click



They exemplify what I consider to be an excellent developer experience:
great templating that helps you get started very quickly.
attractive free tiers.
perfect configuration management: the configuration is initially hidden to allow for a swift start, yet it remains accessible for more advanced use cases.
polished user interfaces and well-written documentation.
I love these tools because they allow you to start quickly and for free, while also offering the capability for more advanced use as needed.
All three of these tools are constructed on top of existing technologies: CSS (Tailwind), AWS (Vercel), and Postgres (Supabase). However they differentiate themselves by offering a superior developer experience.
I think there is a huge opportunity in the data space for this kind of approach.
Data platforms expecially when mixing cloud vendors with open source tools are time-consuming to set up and challenging to work with and maintain.
I hope that new projects will emerge in the coming months to resolve these issues and assist engineers in quickly launching/maintaining data platforms with reduced DevOps efforts.

I'm open to discussions and suggestions on these topics – feel free to comment on this post or reach out if you have tools or methods to address these inefficiencies.
Thanks for reading,
-Ju
I would be grateful if you could help me to improve this newsletter. Don’t hesitate to share with me what you liked/disliked and the topic you would like to be tackled.
P.S. you can reply to this email; it will get to me.
Have you checked Dagster? To me, they deliver precisely on the local to prod, especially with their resources model. It eases many things and has a beautiful local dev experience. Also, it's at the center of modern data, integrating all tools. So, testing with dbt, adding DQ tests, and others is much easier than without.