
Moving from BI to Data Apps (Part 1)
Ju Data Engineering Weekly - Ep 41


In the past few weeks, I have talked a lot about the data pipeline side of the data stack and especially how to make them more efficient by mixing various engines (e.g. DuckDB X Snowflake).
David and I discussed the potential for bringing that multi-engine setup to data distribution, particularly for use in data applications (like embedded analytics).

In this collaborative post, we’ll deep dive into the distribution side of the data stack and especially the following points:
1: BI is not enough
2: Why is an extra layer needed?
3: Off-the-shelf data backend platforms
4: Data Backend in a Box
BI is not enough
Let’s break data distribution into two buckets: internal and external.
Internal: BI tools, notebooks, internal tool builders (ex: Retool)
External: any customer-facing product or communication
Say we run a SaaS business, and built an internal customer health dashboard.
It provides the customer success team with specific recommendations to improve a given customer’s product adoption.
When the dashboard is internal-only, our requirements are minimal and generally satisfied out of the box:

Once you land modeled tables in your warehouse/lake (using something like dbt), internal consumers like BI integrate natively.
Then imagine, we decide to expose that dashboard within the application itself (as “embedded analytics”).
When we switch to external distribution, our requirements shift to:

These external distribution requirements are what separates a data backend from merely tables in our data warehouse/lake of choice.
Business logic might be the exact same, but integration patterns, query latency expectations and tenant-isolation requirements are quite different.
So if our starting point is tables, and we’d like to use that same business logic + data pipeline to serve customer-facing embedded analytics, how might we develop that backend?
Why do you need an additional layer?
The majority of data stacks are constructed around cloud data warehouses such as Snowflake, BigQuery, and Databricks designed to serve downstream BI dashboards.
However, they are generally not well-suited for feeding external applications.
Why?
Cost considerations
For external distribution, your competition is no longer other cloud data warehouses (Snowflake vs Databricks, vs BigQuery etc).
Your warehouse is competing against either OLTP (Just Use Postgres, generally the "build" case) or a dedicated data backend platform (which we'll cover in the next section).
We haven't yet done the math on how this pencils out in a typical use case, but there is a significant gap between cloud data warehouse prices (~$8-$32 per hour in Fivetran's latest benchmark) and a serverless Postgres platform like Neon.
In that gap lies your opportunity for optimization, either by rolling your own backend or buying one that fits your ideal cost/performance profile.
High Latency
Cloud warehouses excel at querying large volumes of data, but they are less efficient for small queries.
Indeed, for each query, query time is split into:
compilation time
execution time

The compilation time is not compressible and easily reaches a couple of seconds for complex queries.
Waiting 1s for a dashboard updated every hour is ok… But waiting for 1s for a web application is not..
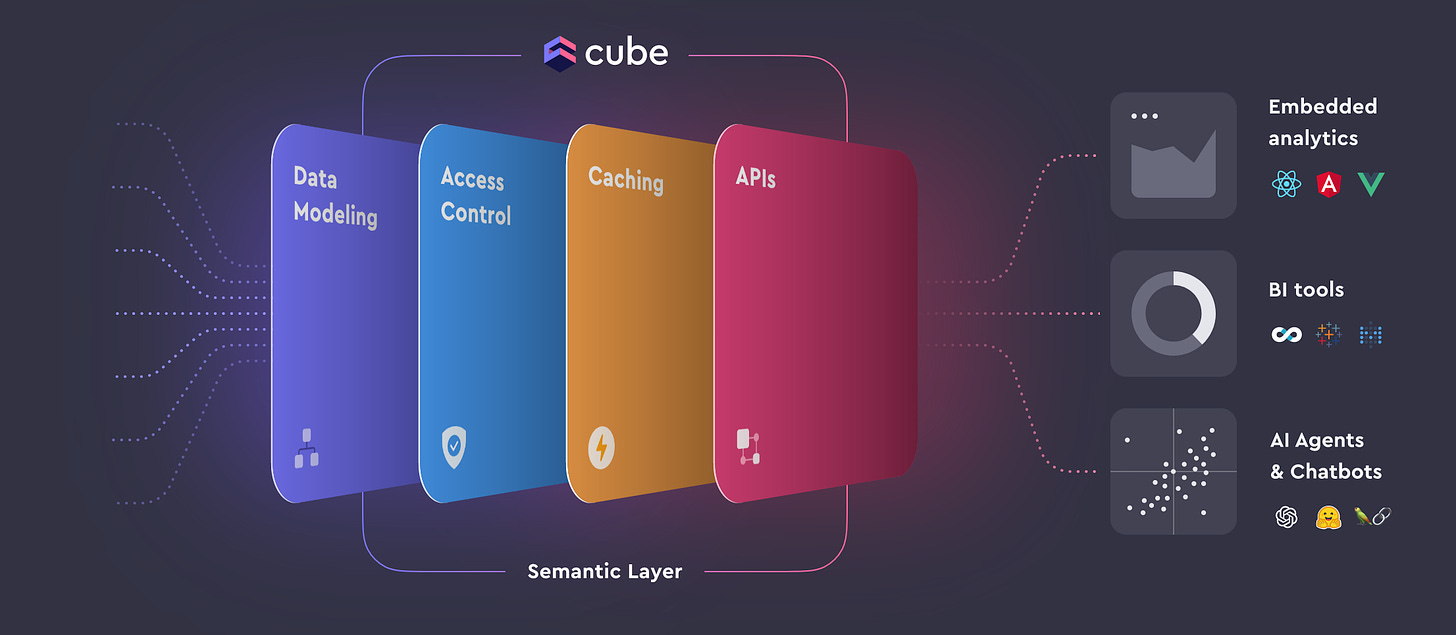
Off-the-shelf data backend platforms
There are a number of existing and emerging tools that seek to turn your data warehouse/lake into a data backend.
In alphabetical order, tools that we see fitting in this category are:
They all solve in different ways for the requirements of a data backend: low-latency querying, tenant-isolated access control and APIs / SDKs for access from a variety of clients.
Most of these platforms offer dials to turn depending on your data freshness requirements: pay a bit more for lower time-to-live on the cache / API (generally down to 1 minute TTL).
From what we’ve seen these platforms are generally hitting the mark in terms of feature completeness for a data backend.
But—we do see a few areas for improvement, which hopefully platforms like these will implement in the future:
Unified application developer experience
Managing schema drift
Cost of data egress to the platform
Data Backend in a Box
As we hinted at earlier, there are a few areas where we’d like to see better support from existing data backend platforms.
If you’re considering implementing one at your company (whether for embedded analytics, AI or a standalone data application), these are just some areas to consider when making a build-vs-buy decision:
Application developer experience
All of these platforms introduce a new API to the application developer workflow, which means handling an additional set of:
authentication/access control requirements
methods of generating type interfaces (if Typescript is your thing)
If you’re embedding analytics within an existing application (our example customer health case), you likely already have a means of solving for these (likely on your OLTP database like Postgres).

It’d be lovely to layer in a data backend to an application, without needing to also layer in a sidecar developer experience (maybe more on this in future posts).

Schema drift between the data backend and the application interface
It’s often true that a data backend is fed by analytical data models built using a tool like dbt.
What happens when the schema changes upstream in the warehouse, breaking our ability to serve that dataset to an application downstream?

At the moment no data backend platform that we’ve seen solves for this problem natively, although most will gracefully recognize the breaking change, stop serving new data to that endpoint.
Some, like Patch’s dpm (data package manager), approach breaking changes by cutting a new API version automatically.
In any case, if dbt is an important part of the data backend development workflow, we’d like to see the ecosystem integrate natively with dbt’s model contracts + model versioning, to make for an explicit change management process.

Paying for data egress
These platforms are generally able to offer a smooth developer experience by taking on end-to-end responsibility for the backend (from data storage through the API gateway).
Like all things, this comes with a cost—you must pay for the egress of data from your source data platform (whether warehouse or lake) to the backend platform.
In some cases, this is unavoidable—if your source is Snowflake, you must pay to query Snowflake to ingest it into the caching layer.

If you already are running on a lake architecture (with modeled data landed in s3), this can hurt a bit more.
Why can’t I just leave data in-place and serve the API from it?

After this initial reflection about the state of the art in the distribution layer world, we asked ourselves the following question:
Rather than use an off-the-shelf data backend platform, what would it take to build it yourself from existing open-source tooling?
Teaser for the next post
In the next post, we will try to build the v0 a complete distribution layer made out of open-source tools that can serve the requirement mentioned above.
As a teaser, we have already played a bit and got the following stack up and running:


with the dashboard in action querying a 60m rows dataset with duckDB and AWS Lambda:
If you are interested in the topic, subscribe to get notified about the following post.
Get in touch!
If you’ve built a data backend to serve embedded analytics or another customer-facing use case, we’d love to hear from you.
What was hard? What was easier than you thought it’d be? What’d we miss?
Thanks for reading,
David & Julien
 | A guest post by
|