


N engines 🔜 1 language ? 🧐💭
Ju Data Engineering Weekly - Ep 36

If you've been following me in recent weeks, you'll know that I am particularly bullish on the coming possibility of building multi-engine data stack based on Apache Iceberg.
As mentioned by a post from Tabular.io, some recent announcements have further reinforced this trend:
BigQuery announced GA for Iceberg support.
Snowflake announced Iceberg Table performance increase.
Databricks announced future support for Iceberg.
Iceberg is quickly getting traction on the market, and this opens a new way to design a data platform by mixing different engines.
For example:
DuckDB for small workloads
Databricks for heavy Spark workloads
Snowflake for distribution: Data Sharing / User Management / BI “backend”
Being able to mix different engines brings up new challenges.
One of them is the way you interact with the data: each tool has its own SQL language.
The need for a standard way to interact with data has been emphasized by some influential people in the industry recently:
I predict the coming years will bring a new wave of investment in user interface productivity
Meta paper: The Composable Data Management System Manifesto
We believe language frontend modularization to also pave the way for language unification, or supporting a single unified SQL dialect, and a single unified dataframe dialect across data management systems
Let’s use this newsletter post to explore initiatives that aim to solve this problem.
Malloy: New SQL Standard
One possible approach to creating a unified interface for data is to define a new SQL standard, and this is the approach taken by Malloy.
Malloy is a language built on top of SQL, aiming to simplify queries.

They define a syntax that feels familiar to SQL but is more concise and less "cryptic."
I'll let you judge for yourself with their examples:

and with a nice query design when dealing with timestamps:

Malloy offers a better user experience with more understandable operations compared to SQL.
This is especially true for nested queries.
Instead of writing an unending number of CTEs (Common Table Expressions) to construct nested queries in SQL, Malloy proposes the "nest" operation, which generates a subtable for each row in the view where it is embedded.

Checkout Malloy design patterns here, if you are interested in mote advanced use cases.
I had a very positive first impression of Malloy.
However, this project is still relatively new and may not be suitable for advanced analytics for the following reasons:
The list of compatible databases is quite limited: only BigQuery, Postgres, and DuckDB.
There is no DBT plugin available for integration as far as I know.
I recommend keeping an eye on this project in the coming months, as the number of integrations is likely to increase.
Ibis: Unified DataFrame API
Ibis, instead of approaching the SQL API, defines a universal data interface through the concept of DataFrames (popularized by Pandas).

Their goal is to provide a unified DataFrame API on top of various compute engines.
Ibis defines a common API that is transpiled to native code for each backend.
The list of compatible databases is impressive, which, from my point of view, makes it a more credible candidate than Malloy for a cross-engine interface:
Apache Arrow DataFusion (experimental)
Apache Druid (experimental)
Oracle (experimental)
Polars (experimental)
Snowflake (experimental)
Trino (experimental)
If you know Pandas, Ibis datagram manipulation is really similar:

Due to differences in SQL dialects and support for various operations in different backends, support for the Ibis API varies.
For example, here's the coverage:
Bigquery: 80%
DuckDB: 73%
PySpark: 63%
Snowflake: 72%
I came across a very interesting post about a data team using Ibis.
Their primary motivation was to future-proof their data stack and avoid tying their data workflows too closely to the underlying engine:
Ibis can be an incredibly powerful tool for modern data teams who are looking to future-proof their data workloads. Technical debt is a real force to be reckoned with as data systems come and go.
Ibis can be integrated into DBT, and as SQL coverage increases over the next few months, it will become a very interesting candidate as a multi-engine interface.
LLMs: On the fly transpilation
As you saw, defining a new standard is very challenging because the data ecosystem is highly fragmented.

Instead of creating a new meta layer, another approach could be to leverage the recent advancements with LLMs to automatically transpile SQL requests from one language to another.
I played a bit with GPT-4 by asking to transpile Snowflake queries to DuckDB SQL.
I started with a simple pivot.
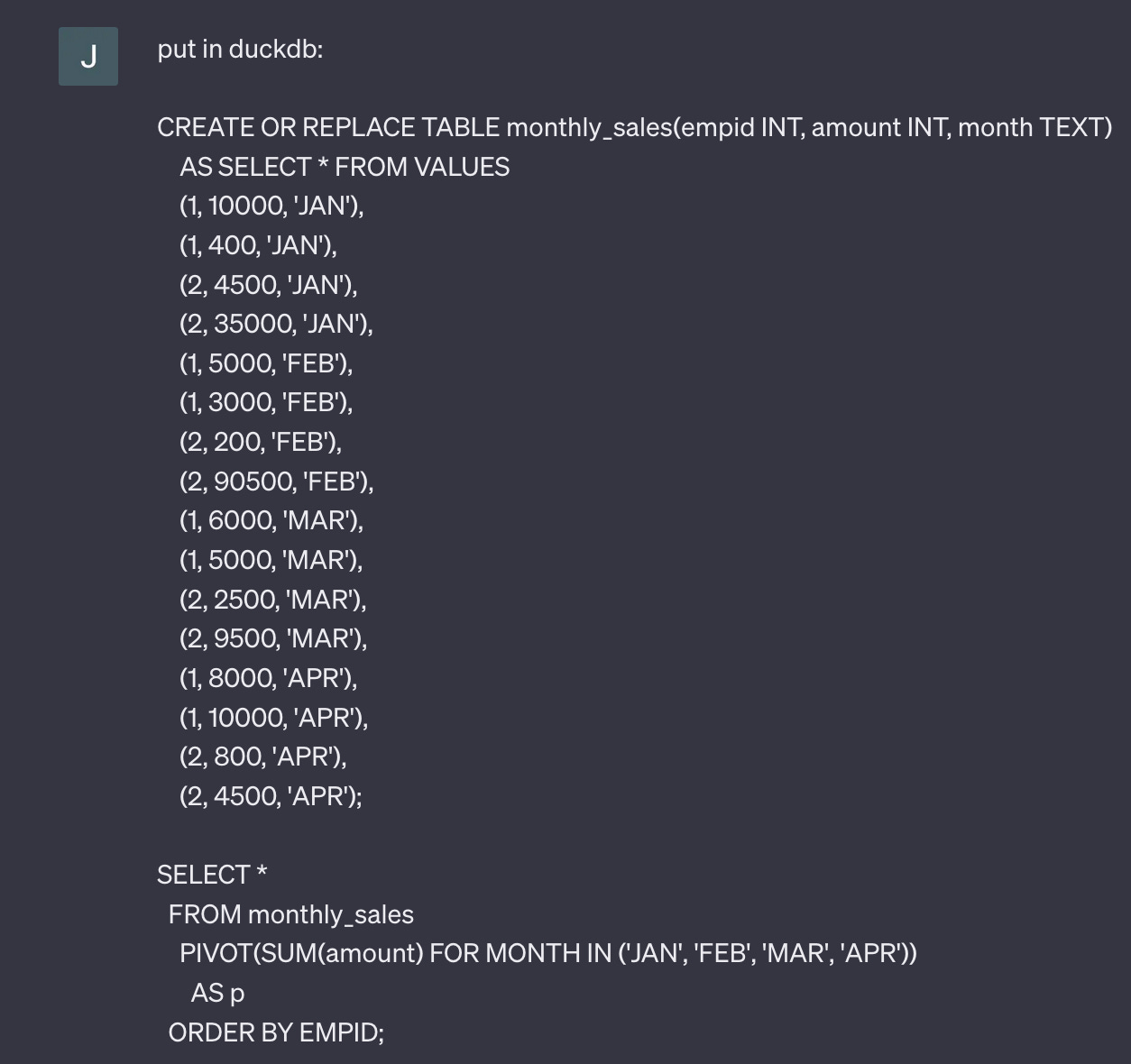
and got correct code in DuckDB SQL:

Continued with a more advanced nested query:

which failed in DuckDb:

I tried to provide him row errors but GPT did not manage to correct itself.
Even if this may be error-prone for more complex queries, with some fine-tuning and iteration (since we know what the query should return), LLM or LLM based Agents should be able to do the job for most of the queries.
Teams can write and test their code in the standard of their choice and transpile it to the best engine adapted to run the job in production.
We have explored three approaches to create a unified access to the data: SQL, Dataframe, and LLMs.
None of them is really 100% mature for now, but they should evolve over the next few months as the business need is going to increase.
Thanks for reading,
-Ju
I would be grateful if you could help me to improve this newsletter. Don’t hesitate to share with me what you liked/disliked and the topic you would like to be tackled.
P.S. you can reply to this email; it will get to me.
The article is missing https://substrait.io/. An intermediate representation language that could finally bring cross-engine compatible plans.
It is like the LLVM for query engines .
Why not use Delta instead of Iceberg - Delta 3.0 released recently with Uniform support meaning you can write in Delta and read as either Delta or Iceberg with no data transformation needed for then use in either format and high performance on either and so even broader support across the ecosystem?
For folks who then use DBT for their sql code management there is an auto-migration for either snowflake or redshift to Delta as well open sourced to just use the best engine for the best jobs.