


Open Source ChatGPT Clone
Data Eng Weekly - Ep 11

Welcome to the exciting world of data engineering!
Every week, you'll get a chance to learn from real-world engineering as you delve into the fascinating world of building and maintaining data platforms.
From the technical challenges of design and impementation to the business considerations of working with clients, you'll get a behind-the-scenes look at what it takes to be a successful data engineer. So sit back, relax, and get ready to be inspired as we explore the world of data together!
This week was crazy in the AI field. So many news and releases:


I wanted to look deeper at one that almost nobody talked about this week: Alpaca 7B.
No, I won’t provide you this kind of non-sens / clickbait graphics that you surely saw this week on Linkedin:

but instead try to explain why this news is particularly significant for companies in Europe.
Alpaca 7B: GTP-3 clone for <600$
This week Stanford releases a new paper called Alpaca.
Their goal is to provide an equivalent to chat-GTP in open-source in order to help research teams working on Large Language Models (LLP).
Today, training an LLM is really expensive. It requires large teams of engineers and significant GPU resources (~$500k of GPU cost only for training).
These resources are not accessible to most companies and research teams, which is why they tried to replicate an open-source LLM that is accessible to anybody.
Here's how they did it:
They created 175 human-written instruction-output pairs.
They used GPT-3 to generate 52k instructions from these original 175 labeled data. As you can see in this image, the range of tasks is quite broad

Generating these 52k records only cost them $500.
3- They fine-tuned an open source model called LLaMA on the dataset of 52k instructions generated by GPT-3 from the original 175 labeled data.
During fine-tuning, the original model's weights are adjusted using these new training data, allowing the model to improve its accuracy on that task.
Fine-tuning required significantly fewer resources than training a model from scratch; it took them only three hours on eight 80GB A100s (approximately $100)."
The evaluation of their model vs GTP3 is not really detailed:
“Alpaca wins 90 versus 89 comparisons against text-davinci-003”
The success of Alpaca's approach may be due to a number of factors, including the quality of their training data, their fine-tuning process, and the specific tasks they focused on.
Although their approach is promising, it is unlikely to result in an exact replica of GPT-3 at the moment.
However, it does pave the way for the democratization of this technology, as the entire process cost them less than $600.
LLM Stable Diffusion Moment
As noted by Simon Willison, the current situation with LLM bears similarities to what happened with the diffusion model six months ago, when Stable Diffusion made an open-source version of OpenAI DALL-E available for anyone to run on their laptop.

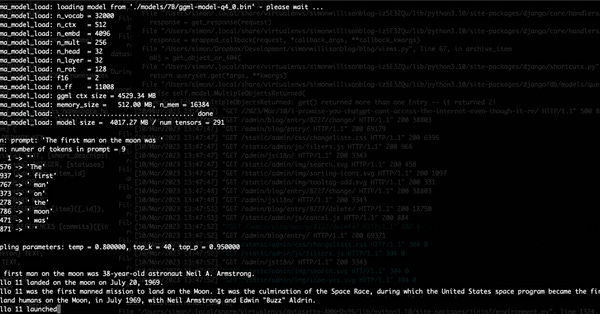
I believe that even though this technology could potentially be utilized by actors with malicious intentions, it can still contribute to a better understanding of how these models, and ultimately leading to more effective regulation of their usage.
What does it mean for EU companies ?
Eliezer provides an example in his tweet to illustrate what it means from a business standpoint.
If you put a lot of work into tweaking the mask of the shoggoth, but then expose your masked shoggoth's API - or possibly just let anyone build up a big-enough database of Qs and As from your shoggoth - then anybody who's brute-forced a *core* *unmasked* shoggoth can gesture to *your* shoggoth and say to *their* shoggoth "look like that one", and poof you no longer have a competitive moat.

It’s open the path to a much more decentralized AI.
The current landscape in the AI industry presents a challenging situation for European companies. OpenAI, Microsoft, and Google are currently leading the race, leaving little room for competition.
It may seem nearly impossible for European companies to develop a comparable AI system, as there is no strong incentive / priority for corporations to invest heavily in R&D in this field.
However, one possible solution for EU companies could be to fine-tune an open-source model to their specific use-cases by leveraging GPT as a synthetic data generator.
This approach could eliminate the need for LLM experts, which are currently difficult to find in the job market, and ensure privacy by hosting the fine-tuned model on-premise.
The issue of privacy has become increasingly important in the chatGTP bubble, as people often forget that all the data they provide while interacting with this agent is stored and potentially reusable.
Before concluding this newsletter, I wanted to mention that Alpaca is open-source but its commercial use is prohibited (LLaMA has a non-commercial license). However, it is highly likely that another version of Alpaca with commercial rights will emerge in the coming weeks or months.
thank you for reading.
-Ju
I would be grateful if you could help me to improve this newsletter. Don’t hesitate to share with me what you liked/disliked and the topic you would like to be tackled.
P.S. you can reply to this email; it will get to me.