


Pandas v1 is dead, what's next ?
Ju Data Engineering Weekly - Ep 39

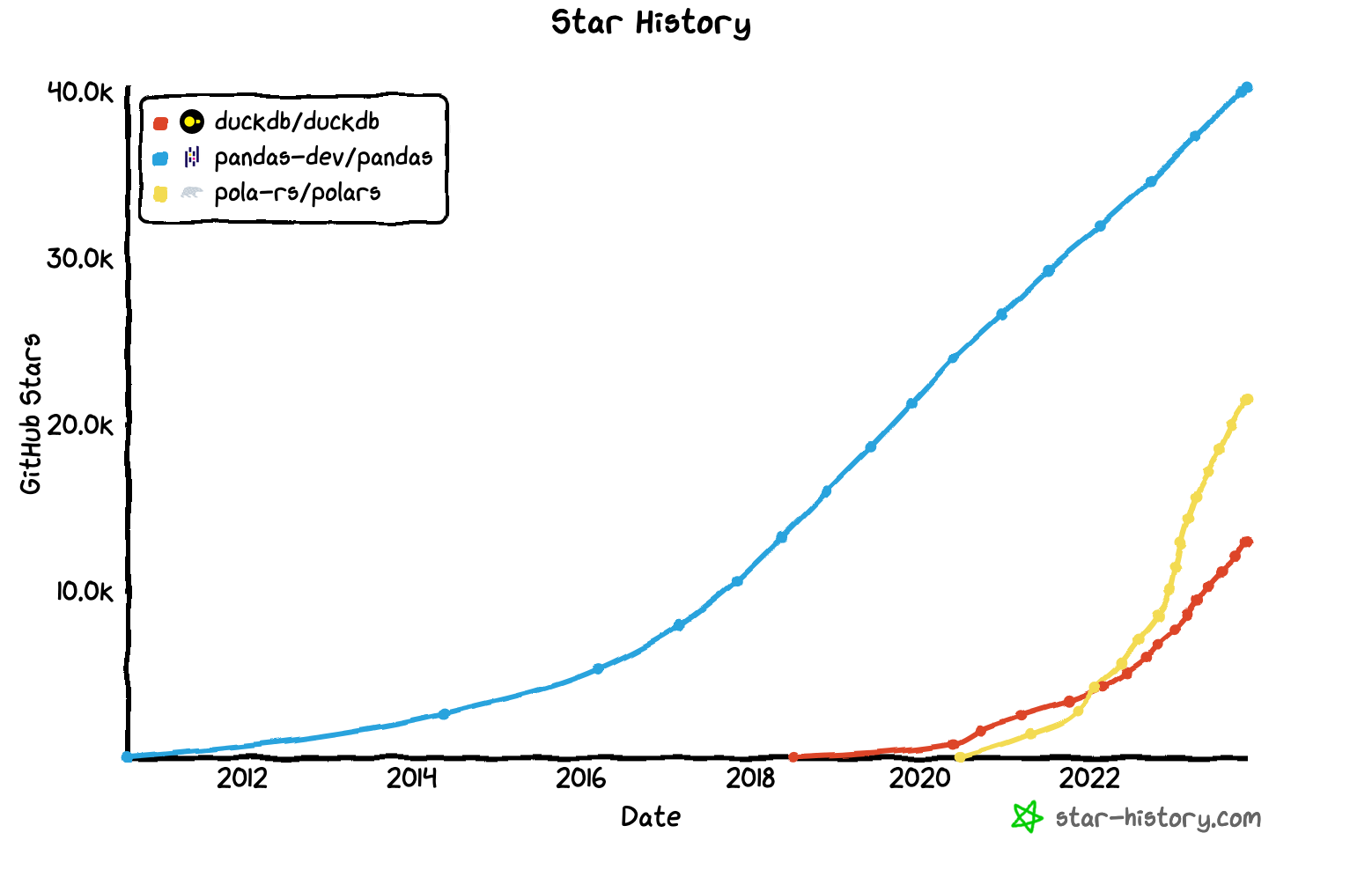
Pandas has been an important player in the data science field for years.
Scientists are using it a lot for local data manipulation saving the pain to load data into a database.
However, transitioning Pandas code from proof-of-concept to production has often led to lot of frustrations for data engineers..


Fortunately, the field of lightweight compute engines has evolved significantly in recent months with the following releases:
Pandas v2 = New backend for Pandas
CudF = Pandas + GPU
Polars = Rust version of Pandas
DuckDB = in process OLAP DB
In this week's post, I wanted to explore these recent innovations and provide an overview of the current state-of-the-art in this field.
Pandas v2.0
✅ Backend: Apache Arrow
✅ API: Dataframe
✅ Binding: Python
The first version of Pandas was developed using NumPy (C++).
At the beginning of this year, Pandas v2 was released, with Apache Arrow as its new backend.
This update addressed significant issues in Pandas v1:
Inadequate support for strings
Absence of handling for missing values
Moreover, adopting Arrow has notably improved both reading and processing performance:

More technical details about the advantages of the new Arrow backend can be found here.
Pandas + GPU = CudF 🔥
Last week, Nvidia announced the release of a new version of cuDF, a library enabling dataframe manipulation on GPUs.
This latest release allows developers to use pandas on GPUs without any code modification!
With just one command line, Pandas computation can done on GPU and achieve up to a 150x boost (number from Nvidia..) in performance:
%load_ext cudf.pandas
import pandas as pd

Polars
✅ Backend: Apache Arrow
✅ API: Dataframe + SQL
✅ Binding: Rust, Python
Polars is the equivalent of Pandas within the Rust ecosystem.
Rust provides speed advantages for several reasons:
It's written in Rust :)
It enables lazy execution.
Lazy execution means that computation is deferred until the point when it's absolutely necessary.
In the example below, the filter and group by operations are only computed when collect() function is called.

This enables Polars to analyze the logical plan of the query and apply various optimizations and heuristics, reducing the amount of work required to execute the query efficiently.
DuckDB
✅ Backend: OLAP DB + support for streaming queries back and forth to Arrow
✅ API: SQL
✅ Binding: Python, Node, C++, Java, R, Rust etc

Contrary to Pandas or Polars, DuckDB is not an in-memory format; rather, it is an in-process database that offers several advantages:
One-line setup:
pip install duckdbSpeed: columnar-vectorized query execution engine
A diverse ecosystem of extensions.
Extensions are installed by Duckdb directly and not via pip (bye-bye dependency hell ☠️).
These extensions enable interaction with a wide range of connections (such as AWS S3 and internet-hosted zip files) and formats (like JSON, Parquet, etc.).
This addresses the same pain point that Pandas did in its time: you don't need to spend hours loading data into a database before starting to manipulate them.
Interoperability with Apache Arrow
These three engines either use Apache Arrow as a backend (Pandas, Polars) or have compatibility with Apache Arrow (DuckDB).
Apache Arrow is a standard designed for the exchange of in-memory data between different systems.
It enables in-memory data to be shared without the need to be saved and loaded from disk (serialization and deserialization).
What's particularly exciting about Arrow is the interoperability of the tools built on top of it.
For example, you can run DuckDB queries on top of a Pandas DataFrame to benefit from its speed…

… and then work back in Pandas to build visualization with pandas-compatible packages such as scikit-learn.
Additionally, Arrow improves performance by using a columnar format.
As illustrated in the figure below, this approach maximizes query efficiency by enabling the scanning and iteration of large chunks of data.

Performance Benchmark
I spent some time evaluating how these engines compare in terms of performance.
I used the TPC-H benchmark and a repository provided by Polars, which facilitates the comparison of benchmark queries between engines.
The results are as follows for different sizes of datasets:
TPCH-1, based table with 1.5 million rows

TPCH-10, based table with 15 million rows

I would not interpret the results as one engine being X times faster than another.
However, it helps to get a feeling about the differences you might expect when selecting an engine for a specific type of task.
It's important to note that I only considered the query time and did not evaluate the IO time which can be quite long for Pandas on GPU.
For further reading on this topic, I recommend works from two creators I enjoy, Simon Späti and Mehdi Ouazza.
If you are interested in building this kind of PoC for your current stack, don’t hesitate to reach out.
I would be happy to guide you through the process !
Thanks for reading,
-Ju
I would be grateful if you could help me to improve this newsletter. Don’t hesitate to share with me what you liked/disliked and the topic you would like to be tackled.
P.S. You can reply to this email; it will get to me.