I'm Julien, freelance data engineer based in Geneva 🇨🇭.
Every week, I research and share ideas about the data engineering craft.
Not subscribed yet?
👨🏽💻 echo {YOUR_INBOX} >>
In this week’s article, we welcome Mihai, a data engineer based in Amsterdam.
When ideating this article, we noticed that one of the challenges we face as data engineers is manipulating semi-structured data, particularly JSON.
In many tutorials, JSON data is clean and not deeply nested, but in reality, we often face the challenge of building data pipelines for extremely messy JSON.
We wanted to use this post to demonstrate how JSON can be manipulated using modern data processing tools such as Polars and DuckDB.
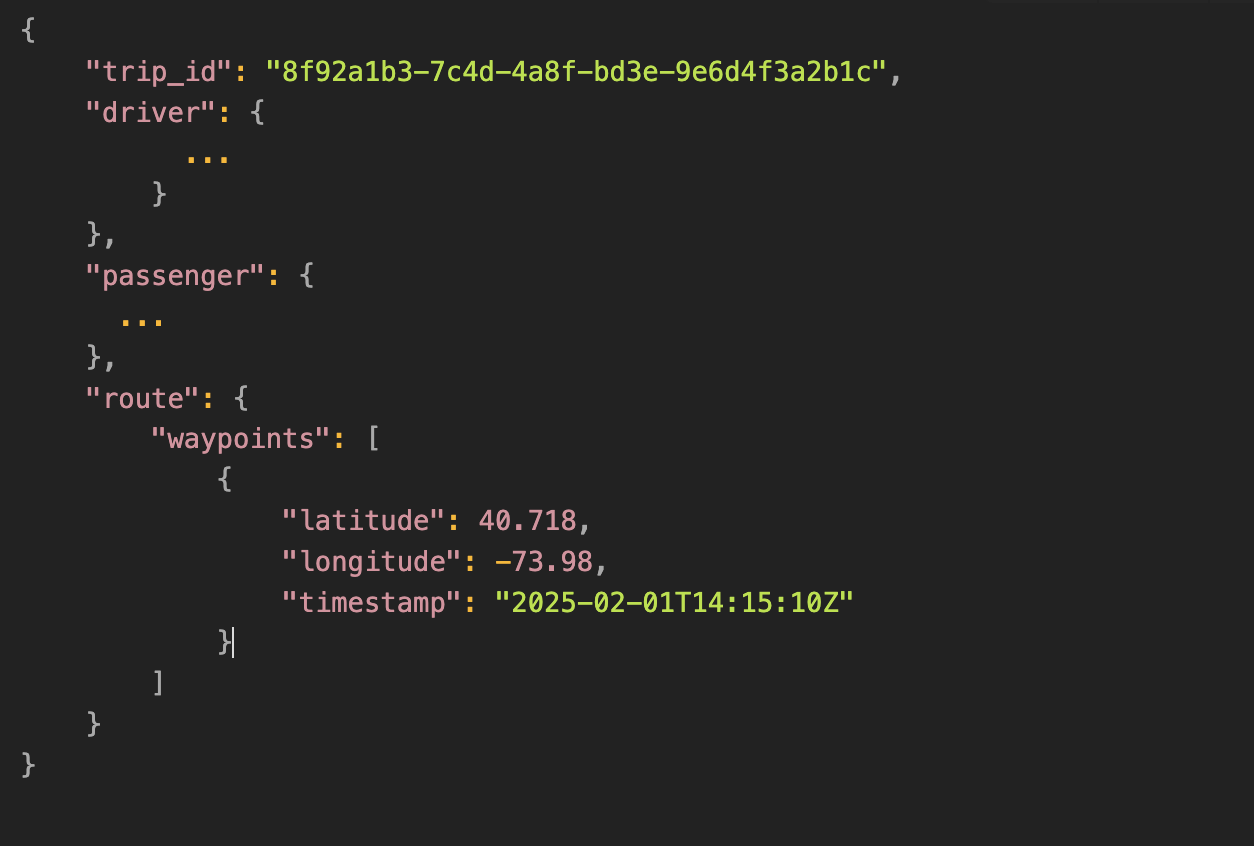
To match our theme, we generated data simulating virtual expeditions in the jungle.
Each JSON record represents an expedition that tracks various species and meteorological conditions.
Here's a sample:
We have generated 500 expeditions split across 45 JSONL files and stored them in S3:
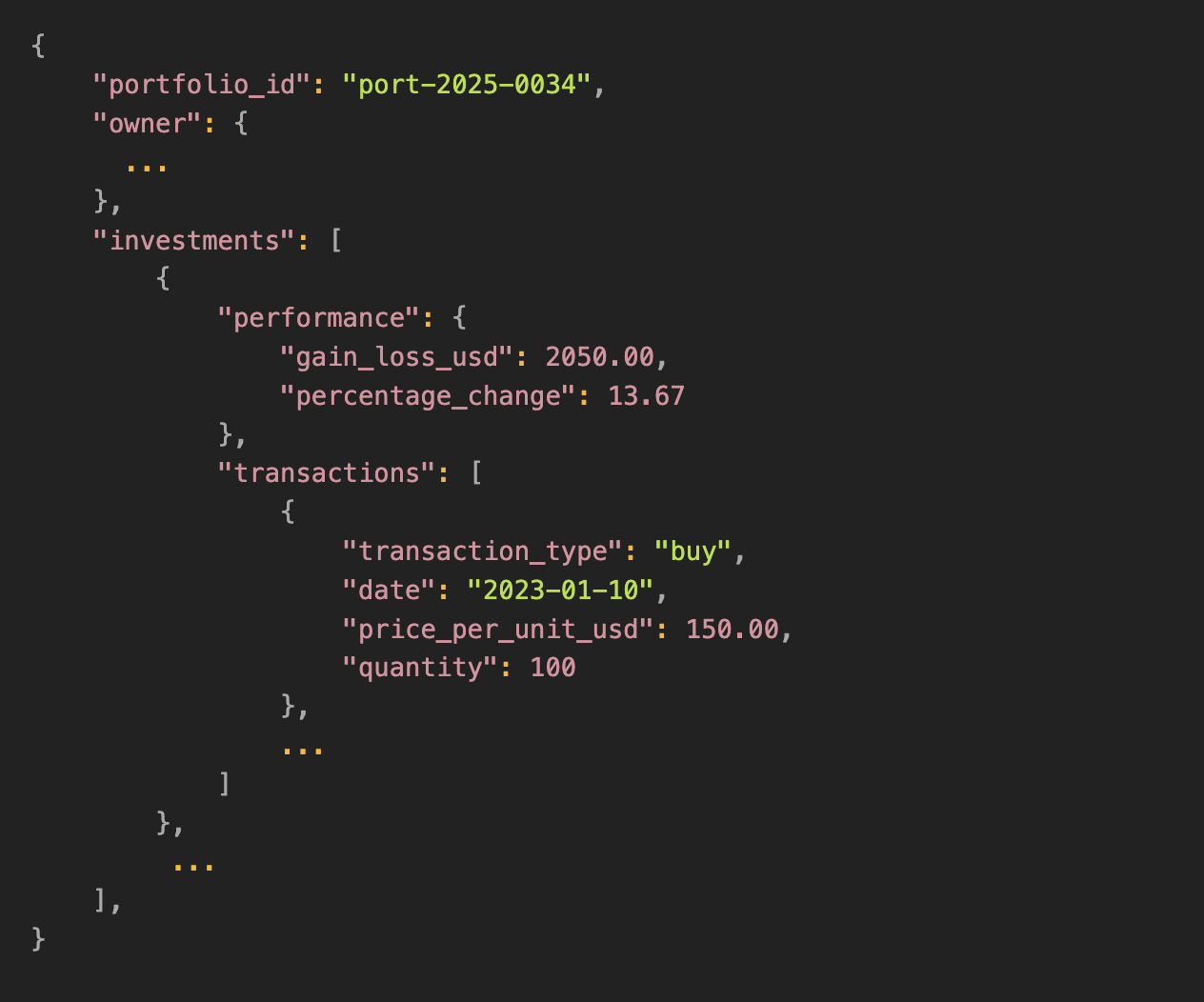
We chose this schema because it models a multi-layered real-world system with several interconnected components.
It has various interconnected dimensions with event-tracking aspects that evolve.
This structure is typical in many datasets, including:
User tracking
Geospatial data
Investment portfolio tracking
Schema juggling
Load data from S3
First, we need to load our JSON data from S3.
Polars and Duckdb both offer similar and nice interfaces:
DuckDB:
SELECT * FROM read_ndjson('s3://<bucket>/jungle/*.jsonl')
Polars:
pl.scan_ndjson("s3://<bucket>/jungle/*.jsonl")
Polars’ scan_ndjson() uses lazy loading, allowing predicate and projection pushdown to reduce memory use.
This means you can load only the JSON records that match specific attributes without reading the entire dataset into memory.
This is especially useful for handling different-sized nested JSON, such as users with different event counts … and therefore ideal for memory-constrained environments, such as AWS Lambda.
Schema validation
A key challenge with JSON is its flexible schema.
Unlike structured formats like Parquet or Protobuf, JSON lacks built-in schema validation, allowing data producers to send inconsistent structures.
To avoid issues, validating the schema before querying is crucial.
Luckily, Polars and DuckDB offer built-in schema validation before loading data, providing two key benefits:
• Ensuring JSON format consistency
• Selectively loading JSON data into memory
After experimenting (with some help from GPT), we came up with this code:
As you can see, the Polars code appears more intuitive to write, while DuckDB's string formatting approach proved slightly more challenging.
Polars being Python native, it was easier to build reusable schema “blocks”:
Now that we can access the data via each engine, let’s run some queries.
Many queries require joining nested dimensions and performing counts and groupings.
A common approach is flattening the entire JSON into a large table.
Alternatively, some normalize the data into 3rd Normal Form (3NF) by splitting it into multiple tables and joining them at query time.
However, deeply nested structures can cause data to bloat and waste memory.
In the example below, the blue block is duplicated for each item in the list (green and red), illustrating how flattening can lead to unnecessary data expansion:
Fortunately, our tools provide functions that eliminate the need to flatten JSON structures.
In DuckDB, the unnest function:
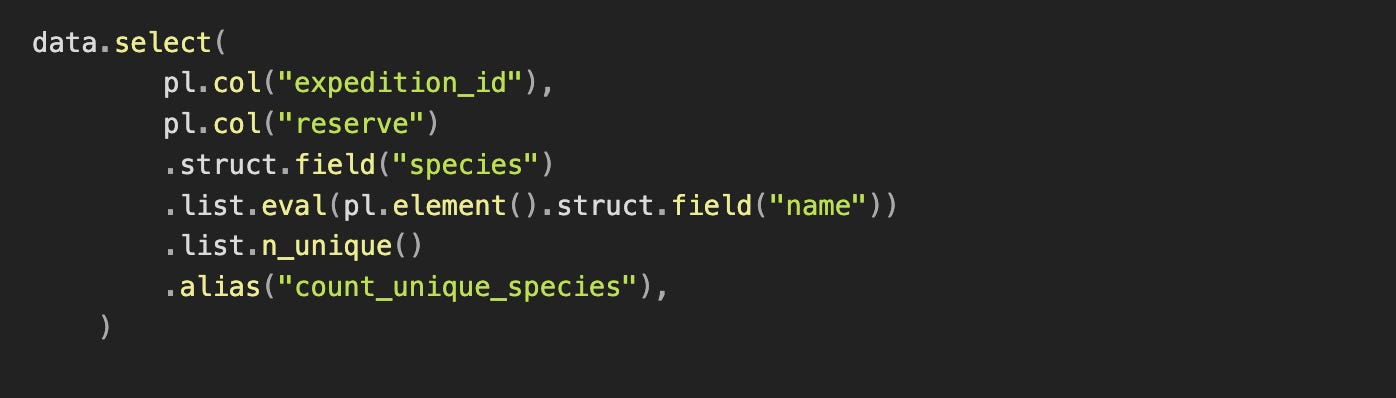
In Polars, you can use the eval function within the list namespace of a column or expression to apply a function to each element in a list.
Additionally, the struct namespace allows direct access to specific fields within a structured column, making it easier to work with complex data types:
In both cases, only the necessary attributes from the nested list are extracted, exploded, and grouped—avoiding complete JSON flattening.
For multi-level nesting examples, check out the source repo.
Advanced queries: mix'n'match
Let’s go further and compute each species' most commonly sighted activity across all sightings and expeditions.
So we need to:
- group all activities across all expeditions for each species
- get the most common one
DuckDB:
Polars:
Performance
We noticed a performance difference between DuckDB and Polars when running the same query.
Although not a rigorous benchmark, our measurements showed:
• DuckDB: ~2.7s execution time
• Polars: ~1.22s execution time
Let’s take a closer look at what might be causing this difference:
Interestingly, Polars’ lazy loading makes it more efficient.
While DuckDB executes individual queries faster, it spends extra time loading all data into memory up front.
Polars and DuckDB both offer powerful tools for manipulating JSON data, but they excel in different areas.
Polars integrates seamlessly into a scripting paradigm, offering:
✅ Easier variable injection
✅ Lazy data loading
✅ Better unit testing – isolating transformations into small, testable functions
✅ Easier data exploration – quickly filtering, grouping, and aggregating data
No winner here—just pick the one that best fits your use case! 😊
Building a data stack is hard—too many moving pieces, too little time.
That’s where Boring Data comes in.
I’ve created a data stack onboarding package that combines ready-to-use templates with hand-on workshops, empowering your team to quickly and confidently build your stack.
Interested?
Check out boringdata.io or reply to this email—I’d be happy to walk you through our templates and workshops.
Just curious, in a real life scenario, would you try to convert the JSON to some other file format before query, or would you do it like this? I wonder how easy both DuckDB and Polars could convert the JSON to say parquet.
Great article thanks for sharing. In my experience as long as i dont have to use unnest function on gb scale data it is all good. I m curious of your approach when mixing geospatial functions with json functions in duckdb, its one of the only things that makes my macbook fans make noise.















Just curious, in a real life scenario, would you try to convert the JSON to some other file format before query, or would you do it like this? I wonder how easy both DuckDB and Polars could convert the JSON to say parquet.
Great article thanks for sharing. In my experience as long as i dont have to use unnest function on gb scale data it is all good. I m curious of your approach when mixing geospatial functions with json functions in duckdb, its one of the only things that makes my macbook fans make noise.