

We often see theoretical articles about why a data contract should be implemented but rarely how it can be done concretely.
In this article, I will share my thoughts on:
The problem that data contracts solve
Why the current approach is limited
A new way to build data contracts with DBT, including a small proof of concept (PoC).
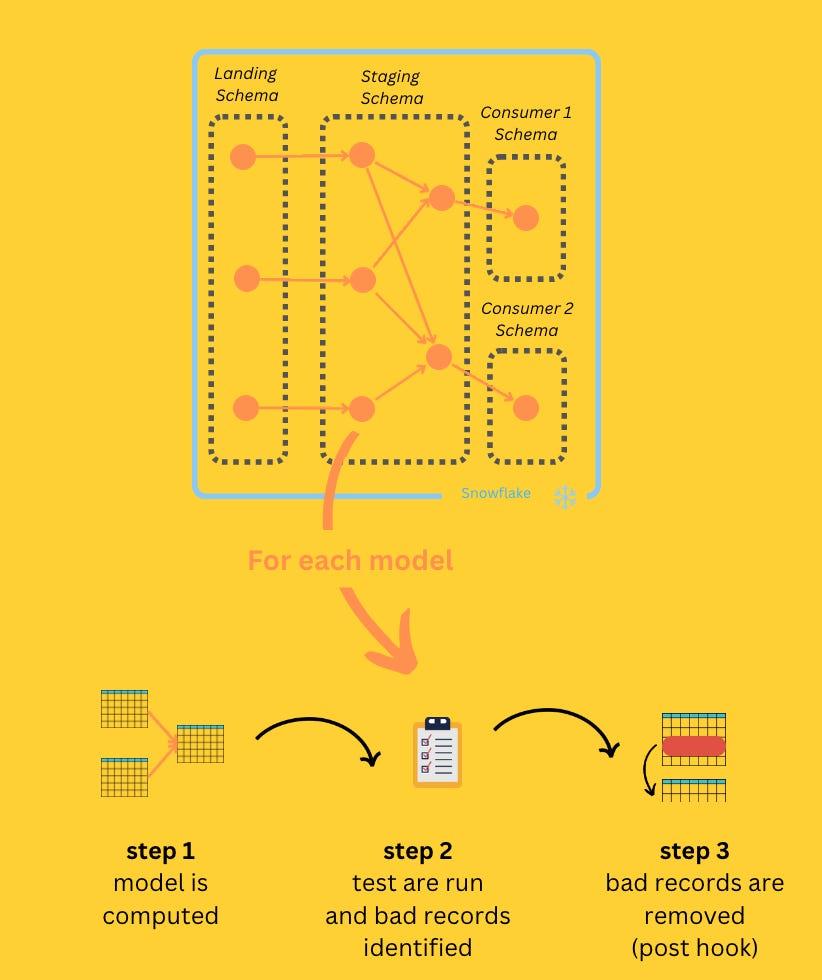
Below is a diagram describing standard data platform layers and incorporating some concepts that I will reference throughout this article that might help you if you are new to the field.
While this specific setup is AWS and Snowflake, it's essential to note that the main points I'll be addressing can be applied to any database or cloud service.

What is wrong with data contracts?
Data contracts are commonly described as agreements between data providers and consumers, specifying the format of the data being exchanged. These contracts are often represented as YAML files, outlining details such as column names, types, and whether they can be empty (applicable to CSV files).
version: 0.0.1
dataset_name: dataset1
columns:
- name: column1
format: varchar
nullable: False
- name: column2
format: number
nullable: True
...The primary objective of data contracts, as commonly perceived in the industry, is to manage the data entering the platform and thereby mitigate data quality issues.
By adding control over the incoming data, the format can be maintained consistently throughout the processing stages, leading to better data quality that is delivered to consumers at the final stage of the data flow.
But, in reality, this is often impossible…
Analytics systems typically have less influence or "power" compared to production databases and other upstream systems within a business. This disparity often makes it challenging to agree on a standard data format that satisfies everyone's needs.
Additionally, when ingesting data from big SaaS providers like Salesforce, Google, or Bloomberg, you have little control over the format of their APIs. These providers have established their own data structures, and you must adapt to their formats rather than imposing your own.
So it's often not practical to have control over the data entering your platform.
Instead, it's more effective to design a data platform in a way that allows for flexibility and accommodates diverse data sources without constraining them.
Containing instead of Constraining
In my view, data contracts should not be used to set strict input rules but instead, they should be seen as a reference to identify and flag unusual or unexpected data patterns.
Accepting that imperfect or bad data may enter the system is essential, and the focus should be on handling it in a way that doesn't disrupt the overall system or even worst: reach your data consumers.
Typically, data pipelines involve multiple stages, and data is processed step by step before reaching the final visualization layer. The conventional practice is to perform data quality checks after all intermediate tables are computed.
This method has a significant drawback: when you discover an error or inconsistency in your data, it's already made its way through the entire process to your consumer.
This delay can lead to undesirable consequences, including the loss of credibility with consumers and potential negative impacts on business decisions.
Let's see how we can avoid it.
Data contract-based quality system with DBT
To efficiently utilize a data contract, we need a system that:
1: checks data continuously against the contract at each processing step. This way, any errors or inconsistencies in the data can be promptly spotted and addressed.
2: captures bad data and prevents it from progressing further down the data flow. This ensures that only clean and reliable data continues through the pipeline until the issue is resolved.
DBT offers a powerful set of features that can be leveraged to build a robust data quality monitoring and correction system:
Running the DAG with
dbt build: With this command, each model is processed and tested one after the other, enabling data validation at each stage of the transformation process.store_failures option: DBT allows you to extract and store failing records in a separate table. This feature is valuable for identifying and addressing data issues efficiently.
Tables and views in DBT are interconnected through references, creating a clear processing flow. This facilitates the implementation of data quality controls at the end of each node (post-hook)) to clean the tables from bad records.
Pre-defined functions: DBT provides a comprehensive library of pre-defined functions that simplify the creation of simple tests for data quality. These functions include checks for uniqueness, null columns, and foreign key existence ect.
Let's take a closer look at an example project. DBT provides a GitHub workspace that you can clone and quickly set up a DBT environment with a pre-existing data models:
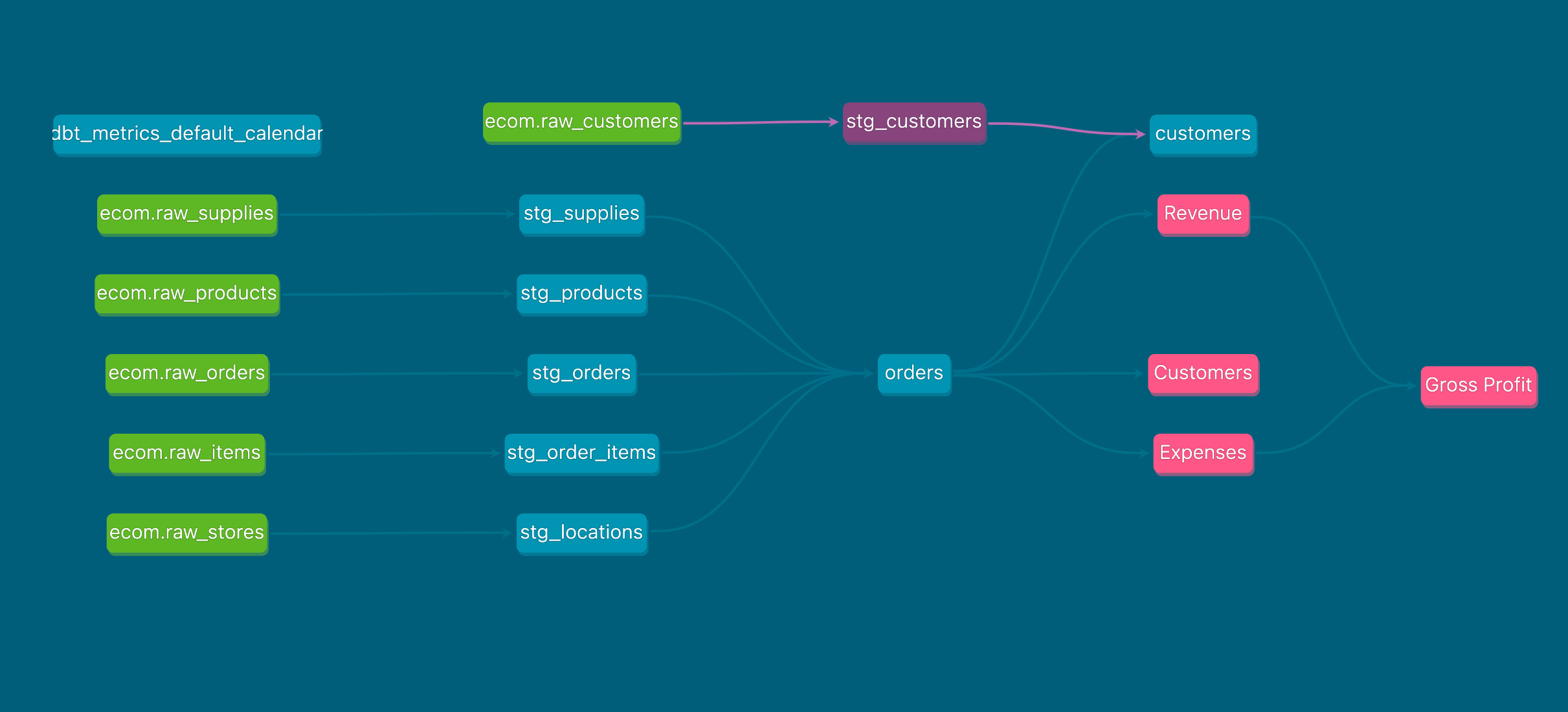
I will update this template project to implement an automated process for identifying and removing duplicate customers from the "stg_customers" table (code available here).
Note that this approach can be easily adapted to conduct any other data tests: check for null values, validate data ranges, enforce referential integrity, etc.
I started by deliberately introducing a unicity error in the customer dataset:

I made then a series of updates to the "stg_customers" model:
added a unicity constraint on the "customer_id" field with the
store_failuresoptions activated

implemented a new feature in the "stg_customers" model—a flag called "is_duplicated." This flag can be used by downstream models, specifically, the "customers" model, to efficiently filter out duplicated customers.

Eventually, I updated the "customers" model to filter out the duplicated records

And that's it!
Let's run the DBT DAG and take a look at the results.
The duplicated customers have been identified and stored by DBT in a separate table:

They are as well correctly flagged in "stg_customers" staging table:

and filtered out from the exposed table "analytics.customers":

This implementation is a very simple starting point, and there are several areas where it has to be improved before industrializing it:
Macros in Post-hook: Create a reusable macro in DBT's post-hook to automatically create the necessary flags and generate the update query for handling duplicate record
Design a strategy for incremental loads
Design a strategy for views
DBT proves to be a powerful solution, offering all the necessary tools to create a system where data contracts can be used to identify and remove bad data throughout the data processing steps.
This approach allows us to effectively address data issues, ensuring that only high-quality data reaches the end consumers of the platform.
By leveraging DBT and implementing data contracts, we can build a reliable and adaptable data environment that boosts overall data quality.
This article draws inspiration from other data practitioners that I highly recommend exploring for a deeper understanding of this topic.
Benn Stancil:
Ben Sanderson

Thanks for reading,
-Ju
I would be grateful if you could help me to improve this newsletter. Don’t hesitate to share with me what you liked/disliked and the topic you would like to be tackled.
P.S. you can reply to this email; it will get to me.
The yellow backgrounds on these diagrams is not a good UI. You should replace the diagrams so they are easier to read.