


S3 is the GOAT 🐐 !
Ju Data Engineering Weekly - Ep 42

S3 was on everyone's lips last week following the re:Invent announcement about Express: a new, low-latency storage class.

This release comes at a time when blob stores are playing a central role in modern data infrastructure design.
Instead of writing to local disks, modern applications are directly using S3 as a data backend, thereby separating storage from compute (serverless architecture).

In this week's post, I'll list various areas where this new pattern has gained traction:
Cloud warehouses: Snowflake & co
Postgres database: Neon
Streaming service: Warpstream
Log store: Datadog Husky
Examples of S3 backends
1: Serverless Data Warehouses: Snowflake & co
Cloud warehouses such as Snowflake, Databricks, and BigQuery all leverage S3 or equivalent technologies as their storage layer.
For example, Snowflake stores data in object storage while maintaining metadata in FoundationDB.
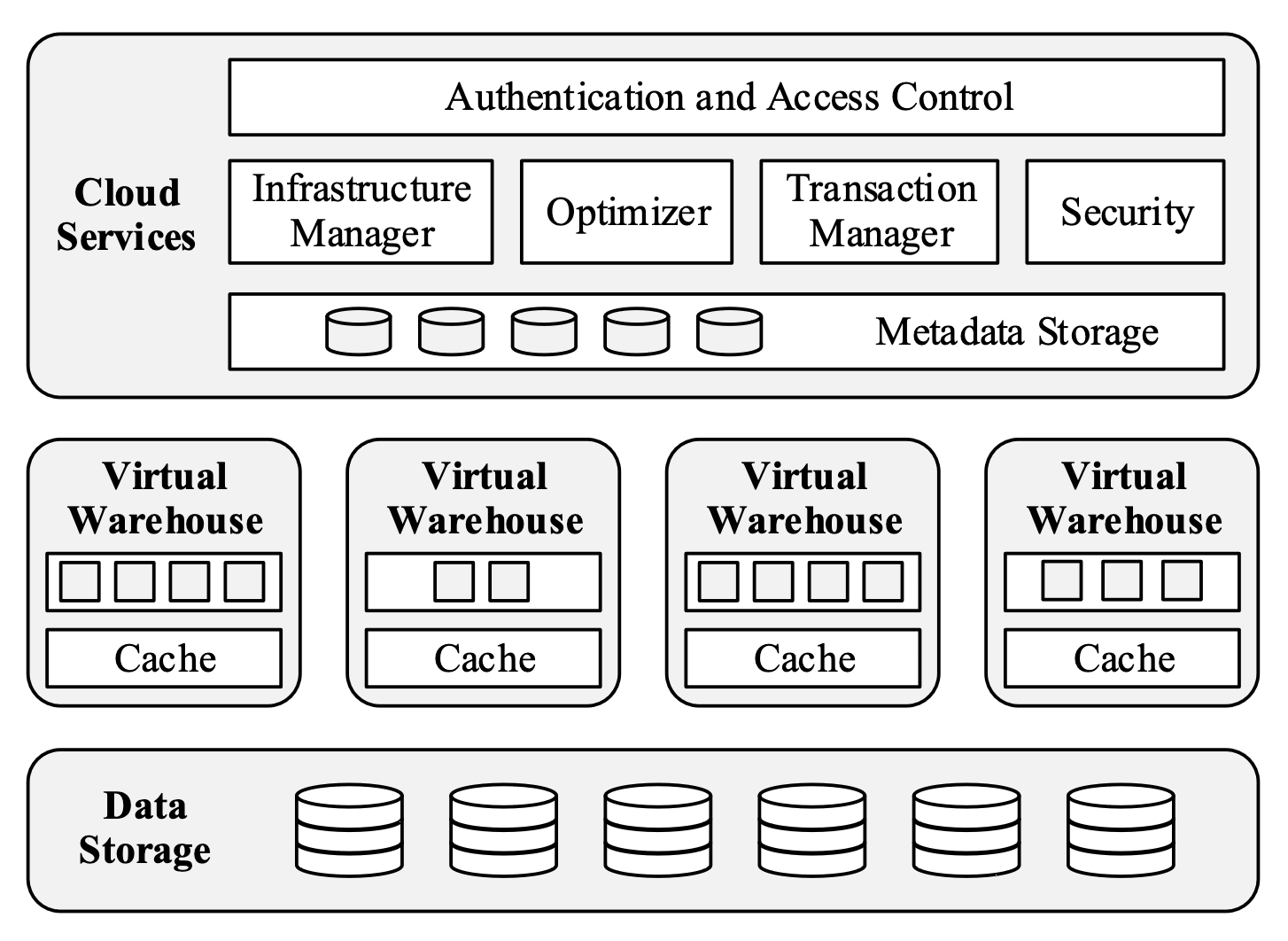
The durability and availability of S3 are explicitly mentioned in the original Snowflake paper as reasons to use it as a persistent layer.
The Data Storage layer of Snowflake today is S3, which is replicated across multiple data centers called “availability zones” or AZs in Amazon terminology. Replication across AZs allows S3 to handle full AZ failures, and to guarantee 99.99% data availability and 99.999999999% durability.
Separating storage and compute has revolutionized the cloud warehouse industry by allowing features such as:
Zero copy clone: one command DB replication
Usage-based pricing
Isolated processing workflows
I wrote a details explanation of these features in a previous article:

2. Serverless Transactional Databases: Neon
Serverless design has also recently reached the transactional world with Neon, a serverless PostgreSQL database.

Yes, you can have a Postgres database and only pay when you use it!
How does it work?
Neon built a caching layer on top of s3 for rapid access to the data while saving “cold” to s3.

The page servers are just a cache of what’s stored in the object storage, to allow fast random access to it.
Object storage provides for the long-term durability of the data, and allows easy sharding and scaling of the storage system.
In Neon, incoming WAL is processed as it arrives, and indexed and buffered in memory. When the buffer fills up, it is written to a new file. Files are never modified in place.
More about their architecture here.
3. Serverless streaming service: Warpstream
Warpstream introduces the serverless design concept to the streaming world.
It is a data streaming platform built directly on top of S3, compatible with Kafka and Kinesis.

Similar to other designs, they have split data from metadata and built a caching layer on top of S3.
The "Warpstream agents" are stateless (with no local storage) and optimize the aggregation of records to reduce the number of S3 API calls while keeping the latency low.
WarpStream Agents make a few files per second, but each file contains records from multiple topics and partitions.
In the background the pool of Agents compacts those small files into larger files to make reprocessing historical data for both single partitions and whole topics both cost effective and high throughput.

This approach allows them to leverage all S3 capabilities directly and saves their customers the trouble of managing storage themselves.

More on their architecture here.
4. Serverless Event Store: DataDog Husky
Datadog has used this pattern as well for their event storage system, Husky.
They applied a similar pattern to Snowflake by building on top of S3 and FoundationDB with the following components:
Writers: Read from Kafka, aggregate events into a file in S3, and commit to the metadata store.
Compactors: Compact small files into larger ones.
Readers: Run queries over individual files in blob storage.
The Writers, Compactors, and Readers coordinate a shared view of the world via the metadata store and are not linked to their local storage.
The abstractions of “metadata store” and “blob storage” are the only stateful components left, and we’ve pushed the tough scalability, replication, and durability problems of “store and don’t lose these bytes” to battle-tested systems like FoundationDB and S3.

More on their architecture here.
5: And much more..
Serverless query engine: Dremio
Serverless vector DB: LanceDB
Advantages of building on top of S3
All the applications mentioned above share the same design pattern:
S3 or an equivalent as the persistent layer.
A caching layer to access "hot" data.
Stateless computation units.
Control plane in the vendor's account.

This pattern provides the following advantages:
Durability
Blob storage with high availability, durability, and elasticity is now a commodity.
It makes no sense to solve it on your own (source):
Large cloud vendors like Amazon have spent billions of dollars making their BLOB stores effectively infinitely available, infinitely durable, and infinitely elastic. Using them as a persistent storage layer means you get all of this for free.
Quote from Warpstream:
We also eliminate hotspots, where some Kafka brokers would have dramatically higher load than others due to uneven amounts of data in each partition. All of these hard problems have been delegated to hyper-scale cloud provider object storage services, where tens-of-millions of human-years of effort and billions of dollars have been invested into durability, availability, and operational excellence.
Infinite concurrency reads
Having stateless computation means that you can infinitely increase the number of nodes if you need to handle more requests.
In a disk-based architecture, this would not have been possible as you would need to coordinate concurrent operations.
With the serverless pattern, this problem is delegated to S3.
Usage-based pricing
In a disk-based architecture, one node needs to be operational all the time.
With stateless workers, this is not necessary: you can scale down to 0 when the system is not in use, thereby avoiding paying for unused resources.
Time travel
In this pattern, data changes are applied to new files and not overwritten.
This provides "time travel" queries almost out of the box, as you can easily access previous versions of the data.
Bring your Own Storage
From a security standpoint, this pattern is also very interesting. Indeed, the data never leaves the user's account; only the metadata are sent to the vendor.
This solves a large number of data security-related issues a customer might have and helps startups collaborate with corporates.
In that context, it's easy to understand why the recent announcement about AWS Express has generated so much enthusiasm.
Indeed, the caching layer mentioned above could also be outsourced to S3, simplifying even more the design of modern applications:
More posts on S3 Express:
https://jack-vanlightly.com/blog/2023/11/29/s3-express-one-zone-not-quite-what-i-hoped-for
https://www.warpstream.com/blog/s3-express-is-all-you-need
Thanks for reading,
-Ju
I would be grateful if you could help me to improve this newsletter. Don’t hesitate to share with me what you liked/disliked and the topic you would like to be tackled.
P.S. you can reply to this email; it will get to me.