
SQL Is Solved. Here's Where Chat-BI Still Breaks.
Ju Data Engineering Weekly - Ep 97

Bonjour!
I’m Julien, freelance data engineer based in Geneva 🇨🇭.
Every week, I research and share ideas about the data engineering craft.
Not subscribed yet?
This is the second episode of my chat-BI series in collaboration with nao.
In the last post, I explored a modern approach to chat-BI: using the filesystem to store and serve context to the model.
Here, the LLM reads the codebase to reconstruct the data model, then runs iterative queries—refining its hypothesis each step—until it converges on an answer.
In this post, I continue the exploration and try to find the limits of this setup. I want to understand when it fails and what kinds of errors it produces.
The goal is to build intuition for where agentic chat-BI breaks down—and why.
I think this can help data teams a lot: not just to benchmark models, but to understand the practical limits of these systems and how to improve them.
This will be quite empirical, but I think it’s a necessary step to build that intuition.
Let’s go.
The Setup
Inspired by Jacob Maston blog post, where he tested BIRD-Bench with schema-only context, I used the following two benchmarks:
BIRD: the most widely used text-to-SQL benchmark. It has 500 question–SQL pairs across 11 databases.
Context provided: column descriptions only.
DABStep: a newer benchmark from Adyen and Hugging Face. It includes 450+ tasks derived from real financial analytics workflows—not synthetic questions, but actual problems data analysts face at a payments company.
Context provided: one large manual.md file + some column descriptions.
BIRD is large, but label quality can be uneven. I isolated a subset of BIRD (the financial dataset) and ran an initial LLM pass to validate the labels. Only 15 questions remained.
DABStep, on the other hand, has only 10 labeled questions in its dev set.
So I merged the two sets. I now have 25 questions that should, in theory, be close to the edge of the kinds of “real” questions someone might ask a system like this.
Yes, this is too small to produce a reliable performance metric. But it should be enough to surface failure modes and collect a set of wrong answers.
Eval Framework
I used Nao as the evaluation framework—they provide a few utilities that make the process pretty smooth.
You simply define question/answer pairs in separate YAML files:
name: dabstep_1681
prompt: ‘For the 10th of the year 2023, what are the Fee IDs applicable to Belles_cookbook_store?
Guidelines: Answer must be a list of values in comma separated list, eg: A, B, C. If the answer is an empty list, reply with an empty string. If a question does not have a relevant or applicable answer
for the task, please respond with ‘’Not Applicable’‘’
sql: SELECT ‘741, 709, 454, 813, 381, 536, 473, 572, 477, 286’ AS expected_answer
And then nao test cmd processes them one by one:
Run chat agent on each question
Compare the result with the golden answer
Collect token usage + tool-call metrics along the way
Serve a UI to explore the result
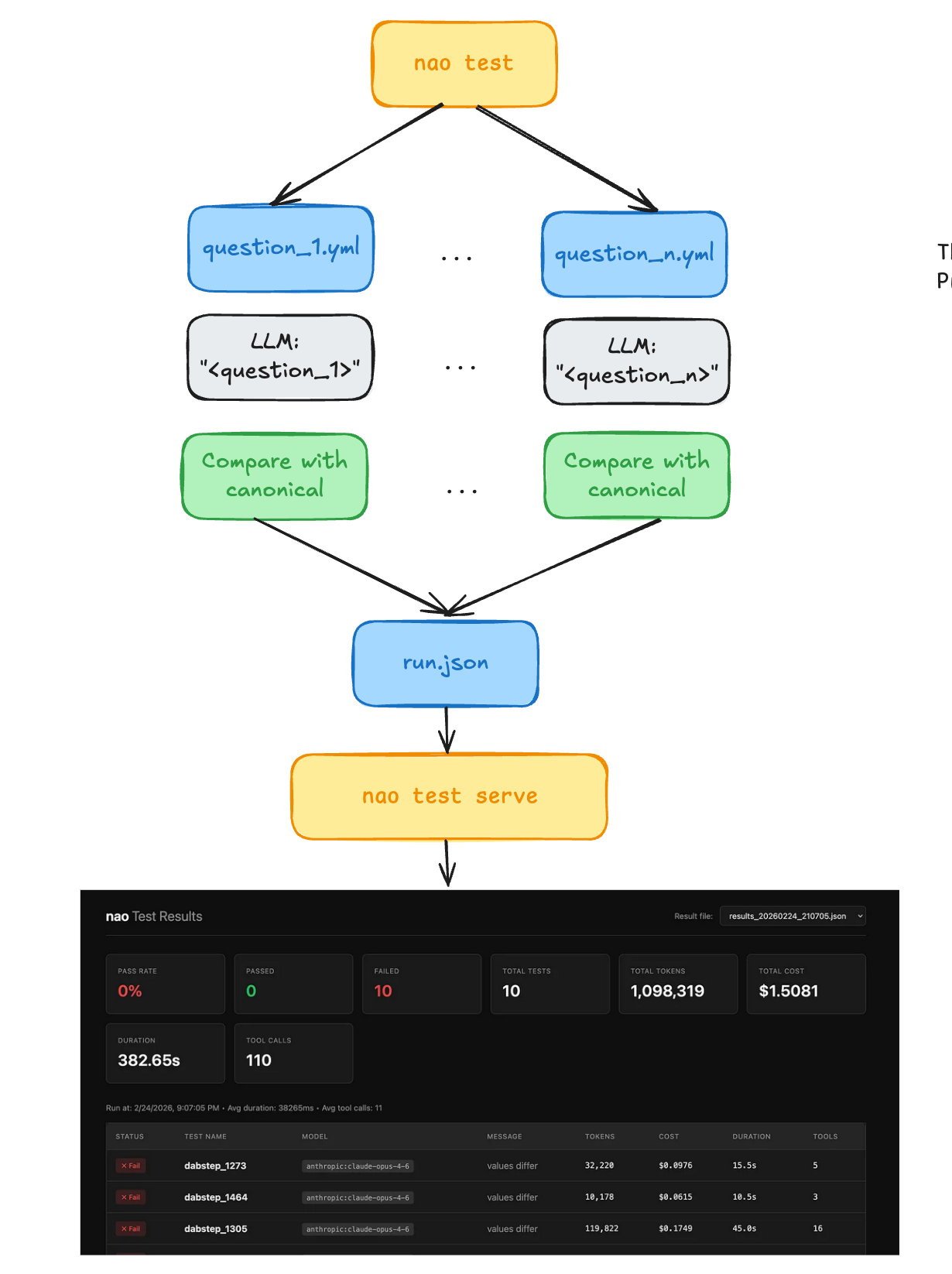
For both benchmarks, I followed the same procedure:
Create a DuckDB instance with the benchmark data
Run nao sync to dump schema metadata into context files
I also cleaned up the context provided by the benchmarks and moved the column descriptions into Nao’s native format for both datasets.
└── databases/
└── type=duckdb/
└── database=dabstep/
└── schema=main/
└── table=*/
├── columns.md
├── description.md
└── preview.mdFor DABStep, I simply copied the large manual.md file into the docs/ folder and referenced it in RULES.md.
I first ran a few smoke tests to get a feel for the models: I had to tweak the RULES.md file for DABStep. The agent was skipping the context files I’d placed in the docs/ folder. So I added a classic rule in RULES.md:
IMPORTANT: Before writing any SQL query, you MUST read `docs/manual.md` first.
It contains critical business definitions that you cannot guess from the data alone.
Then read `docs/payments-readme.md` for column descriptions.
SQL is solved
Now that everything was ready, I ran the benchmark on the two datasets with Opus 4.5.
Here are the first-pass results:
BIRD: 11/15 correct answers
DABStep: 3/10 correct answers
When I first looked at the results, my takeaway was: LLMs have gotten really good at writing SQL. I didn’t see any SQL syntax errors.
So this confirms the intuition that SQL is no longer the bottleneck.
Next, I dug into the failures.
To do that, I used Nao’s UI, which makes it easy to inspect the agent’s tool calls and reasoning step by step.
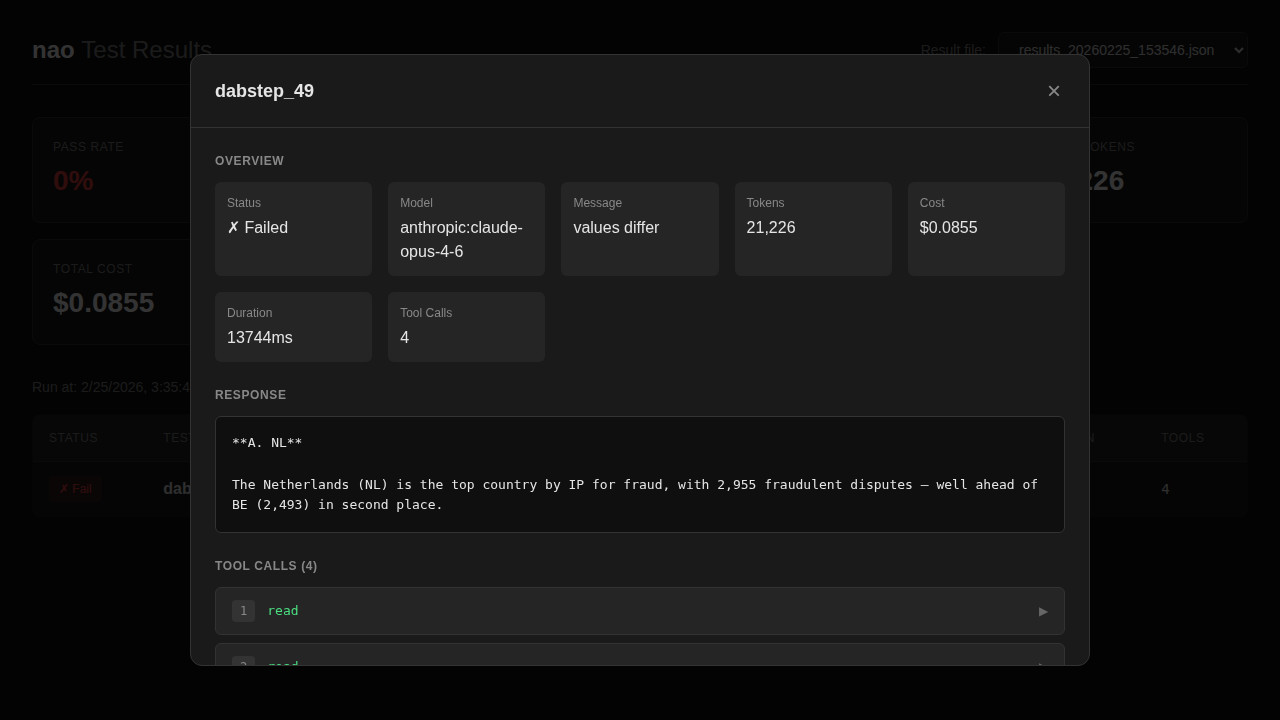
The next sections might be a bit tedious to read, but I think they’re worth it to understand where LLMs still struggle today.
Error: Context Ambuigity
Question
What is the top country (ip_country) for fraud? A. NL, B. BE, C. ES, D. FR
Context
Fraud is defined in the context file as: fraudulent volume / total volume
What went wrong
The agent interpreted volume as number of transactions, so it used COUNT(*).
But the golden answer assumes volume means monetary volume, so it should use SUM(amount).
This isn’t a SQL problem—it’s a definition problem. If the context doesn’t specify what “volume” means, the agent can’t reliably choose the intended metric.
So I added a new rule un RULES.md:
In the payments domain, "volume" always refers to monetary amount (sum of eur_a +mount), not transaction count.
And rerun the eval.
The agent picked the right interpretation of “volume,” but failed at the next failure node: it computed total fraudulent volume (an absolute value) instead of the fraud rate (a ratio).

In other words, even after clearing the first interpretation step it tripped this time on the next one (“is the metric a ratio or an absolute?”).
So my takeaway is:
Every small ambiguity introduces a new interpretation node—and each node is a chance to fail.
As analyses get more complex, the number of nodes increases, and the probability of an error compounds quickly.
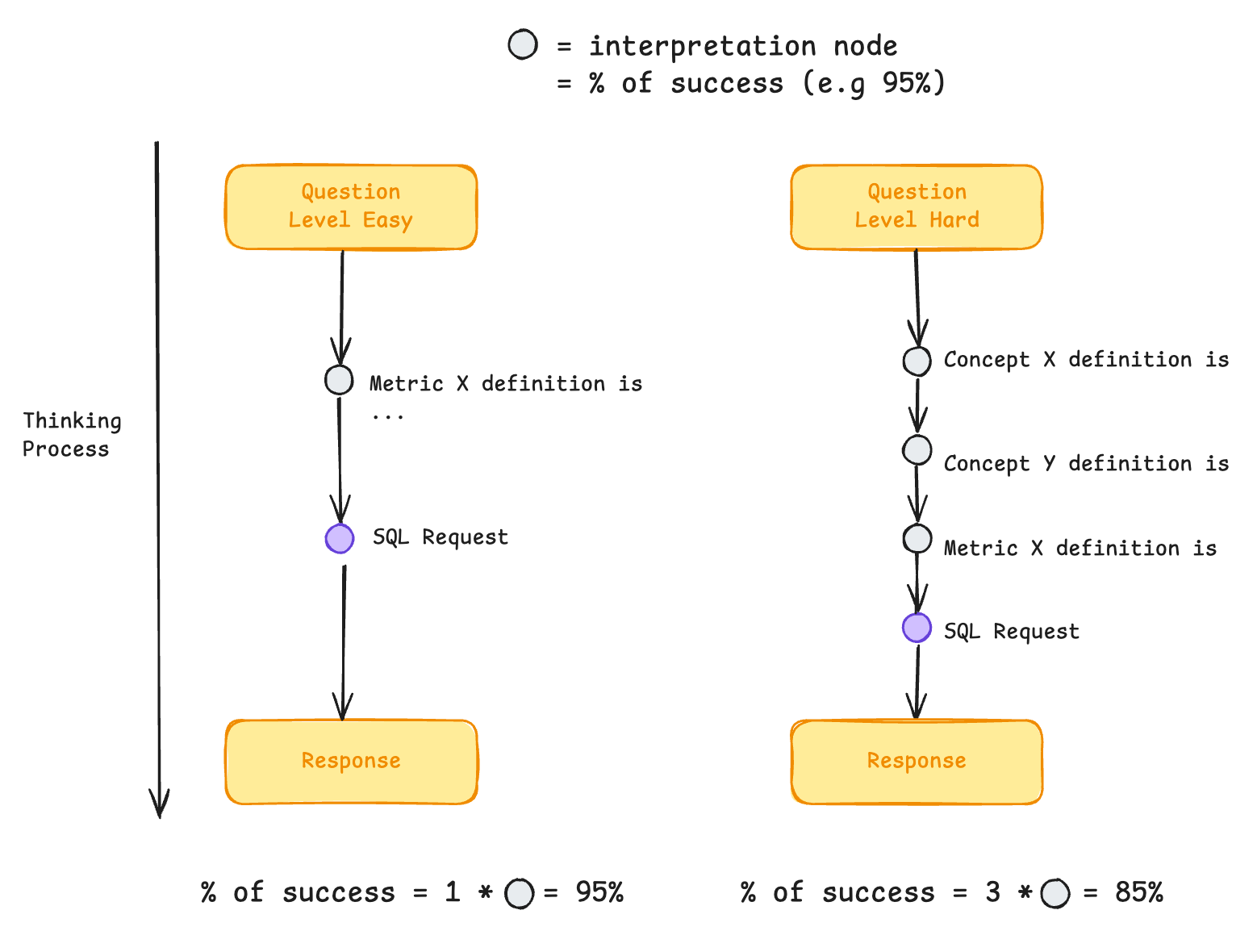
Error: Knowing when you don’t know :)
Question
Is Martinis_Fine_Steakhouse in danger of getting a high-fraud rate fine?
Expected
Not applicable
Agent answer
Yes
What went wrong
The concept of a “high-fraud rate fine” isn’t defined anywhere in the data or documentation.
The manual discusses fraud levels and how they impact processing fees, but there’s no explicit fine mechanism.
The agent inferred that such a fine exists and answered “yes,” instead of recognizing that the question refers to something outside the available context.
I tried adding this to RULES.md:
If a concept or metric is not defined in the documentation or data,
do not invent a definition. Answer "Not Applicable" instead.But the agent kept returning the same wrong answer. It finds enough related data to construct something plausible.

My takeaway:
In line with the last section, we don’t only have interpretation failure nodes (ambiguous metrics, vague definitions, etc.).
We also have framing failure nodes.
Those framing decisions add another layer of compounding error:
Interpretation failure nodes = choosing meaning
Framing failure nodes = choosing scope (is this answerable from the available schema/docs, or is it out of scope?)
As we’ve seen, this is hard to fix with prompting alone. One possible approach would be to add a grounding mechanism, where the agent has to cite and justify its answer using specific sources from the available context and data.
Error: Lack of Common Sense
Question: For the 10th of the year 2023, what are the Fee IDs applicable to Belles_cookbook_store?
The agent debated whether “10th of the year” meant January 10 or October, and eventually settled on October.
LLMs still miss basic conventions and “common sense” assumptions.

This adds a third failure node:
Interpretation failure nodes
Framing failure nodes
Common-sense failure nodes = applying basic conventions and implicit assumptions
The problem with these common-sense failures is that they’re hard to fix with context. You can’t keep adding endless rules to RULES.md for things that should be basic intuition.
These issues ultimately need to be solved by the underlying model.
Iterative Context Building
As you can see, building an evaluation loop—where you confront your LLM with canonical (gold) answers—is essential.
It’s the only practical way to surface failure nodes, understand what kind they are, and then decide what to do next.
A key trap is to use an LLM to generate the evaluation set.
That’s usually the wrong approach: the model will generate the most likely questions given your context, which means you’ll mostly test “happy paths.” Your agent will look artificially good—and you’ll miss the real failure nodes.
The better approach is to observe the system in production:
Log failures and wrong answers
Classify them by failure node type (interpretation, framing, common sense, etc.)
Look for recurring patterns
Once a pattern emerges, add it to your evaluation set. Then iterate on your context and prompts until the results stabilize.
The advantage of tools like Nao is that this process becomes reproducible and easy to plug into CI. You can run the test suite on every context change—every RULES.md update, every new column description, every doc tweak—and catch context drift the same way you prevent code regressions.
Rules.md Spaghetti Prompt
RULES.md can quickly turn into a dumping ground of “Important:” instructions.
And at some point, the model stops treating it like guidance and starts treating it like noise.
There’s also a second trap: overfitting.
When you debug by patching each new failure with a very specific rule—something like:
“If you get asked about X, then do Y.”
…it might fix that case, but it doesn’t generalize. It doesn’t scale. And it gradually makes your context longer, more brittle, and harder for the model to follow.
So where does that leave us?
If context isn’t enough—and rules don’t scale—how do we get reliability?
Probably by combining probabilistic LLM behavior with deterministic metric definitions.
That’s what we’ll dig into in the next post.
I hope this post helped you understand how modern Chat-BI systems are built.
This is the first episode of a mini-series we’re working on with the Nao team, exploring Chat-BI architectures and design patterns.
In the coming weeks, we’ll publish deeper dives on:
Semantic models and Chat-BI
The impact of Chat-BI on data roles
Stay tuned.
We have released a new episod of our podcast with blef (in french). Check it out here:
Thanks for reading,
Ju
> Probably by combining probabilistic LLM behavior with deterministic metric definitions.
And that's where you introduce BSL for the metric definitions hehe