


Test in Prod !! Ghost Mode Development Process.
Ju Data Engineering Weekly - Ep 27

The development process is a crucial aspect of building and maintaining a successful data platform. It should enable developers to thoroughly and rapidly test new features before deploying them.
Using multiple development environments is a standard practice in data engineering to isolate code testing from the production environment.
This paradigm comes from an era where direct control over the production database was limited: running resource-intensive queries on the production database had the potential to disrupt the entire system.
As a solution, organizations replicated the production database at regular intervals and used this test database to safely test new features and changes.
However, this brute-force solution may not be well-suited for modern data platforms.
Let’s discover why.
No more half-filled dev environments
Data pipelines, by their nature, deal with varied and dynamic input data, often coming from external systems. In traditional API development, requests and data formats are standardized as you define how consumers interact with your API and write data into your system.
However, in data pipeline development, the code's behavior is directly impacted by the characteristics and variations of the data it processes. Therefore, to ensure the reliability and accuracy of data pipelines, the development process must be centered around the actual data that the code will handle in production.
Replicating production data entirely in the development environment can be challenging and expensive: it requires significant resources and leads to increased cloud costs.
As a result, many organizations compromise on replicating data (load site, frequency of materializations) leading to discrepancies between the development and production environments.
Luckily the modern data landscape has evolved significantly, and today we have:
Iaac: infrastructure is now managed as code, allowing for easy replication and version control of computing resources.
storage decorrelated from compute (s3 / Lambda, Bigquery, Snowflake, Databricks). This separation enables different processing units to work with the same data concurrently, avoiding contention issues that were common in traditional databases.
These advancements allow us to design smarter development environments where new developments are directly tested in prod on a fork of the data flow (“ghost mode").
Let’s see how such a system can be implemented.
Inspiration from modern data warehouses
One of the most powerful features of modern Cloud Data Warehouses is the ability to decouple storage and compute. With a simple SQL command, you can create a clone of an entire database, including all the tables, views, and other objects.
As an example, in Snowflake:
CREATE DATABASE FEATURE_XX_DB CLONE PROD_DB;With this feature of database cloning, the need for traditional development databases is eliminated. When a developer creates a new branch, the CI can automatically replicate the production database and duplicate all the ingestion pipelines.
As a result, the developer gets a development database fed by production data within the same account, enabling them to work with real-world data to develop new features.
The advantage of having the development and production data in the same account is the maximum flexibility it provides. The developer can easily reference data from the production database if necessary, allowing for more comprehensive testing and development without compromising data integrity.

To further optimize credit consumption and resource usage, the CI should offer developers the flexibility to reduce the scope of the models being updated by the scheduler. This way, only the necessary models are updated during the development process, conserving computational resources.
Once the branch is successfully merged, the CI system can automatically delete the temporary database, ensuring a clean and efficient development environment.
By leveraging the cloning capabilities of modern data warehouses, development teams can work directly on production dataflow and get immediate feedback on their changes without impacting the production environment.
This warehouse cloning feature can actually be replicated for upstream data lakes design as well. Let's take a closer look at how.
Ghost mode in the data lake
"Ghost mode" development process can also be extended to your data lake with a well-designed CI (Continuous Integration) and proper role management.
To illustrate the concept, let's consider a straightforward use case, based on AWS, but adaptable to Azure and GCP, where multiple data transformations are performed sequentially using several Lambda functions. Each Lambda function is triggered by a new file written to S3, processes that file, and writes the processed data back to S3 again.
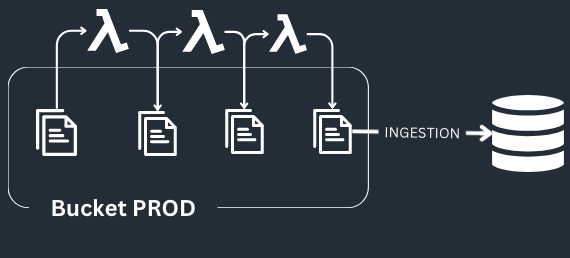
Let’s imagine we want to update the second lambda in the workflow.
In a classical development process, the CI would replicate the complete infrastructure (lambdas + s3 bucket) in another account.
The idea in ghost mode development is to only deploy an additional dev version of this lambda and to fork the prod data flow:

Here is what the process looks like:
1- The CI deploys the new version of the second lambda
2- The dev lambda is triggered by events from the PROD bucket and writes files to its own bucket.
3- The next step of the transformation is done by the next prod lambda, which should be able to source data from both DEV and PROD buckets. If this poses too much risk, as the downstream lambda experiences increased load, you may also replicate the downstream lambdas.
4- The forked data flow feeds a feature DB cloned from the prod DB.
All the new resources should be created automatically by the CI and deleted when the branch is merged.
In order to avoid any mistake deletion, the CI assigns restricted roles to dev resources. These restricted roles should only provide the necessary permissions for the dev resources and should not grant write access to the production bucket. This ensures that the development team can work safely with the production data without risking any unwanted changes or disruptions to the live system.
With this setup, you gain a lot of flexibility in releasing new features and changes to your data platform.
You can test and observe the impact of your modifications step by step before fully deploying them to the production environment.
Developers have then different options to release new features:
Switch the DBT model first, observe, and then switch ingestion
Switch the ingestion first, observe, and then switch the DBT model
In conclusion, the ability to decouple storage and compute along the data stack, combined with modern CI/CD practices, enables the design of highly flexible ghost mode development processes centered around the production data flow.
Although implementing the initial DevOps effort to set up this development process may require more investment, the return on investment becomes evident over time.
Resources:
https://increment.com/testing/i-test-in-production/
https://squeaky.ai/blog/development/why-we-dont-use-a-staging-environment
https://launchdarkly.com/blog/what-are-feature-flags/

Thanks for reading,
-Ju
I would be grateful if you could help me to improve this newsletter. Don’t hesitate to share with me what you liked/disliked and the topic you would like to be tackled.
P.S. you can reply to this email; it will get to me.