


The Data Stack Setup Problem
Ju Data Engineering Weekly - Ep 46

If you're a company looking to get started with data, what are your options?
First and before, don’t hire a data scientist ^^.
Jock aside, he/she will end up doing data engineering so you can directly hire a data engineer.
That being said, constructing a data platform from scratch requires combining several tools: data catalog, data ingestion, batch and streaming data processing, dbt, BI, and orchestration.

And that is a looot of work.
For each category of these data tools, you have the option to choose between usage-based SaaS (whether closed or open-source) or self-hosted open-source tools.
Many data consulting companies recommend their clients opt for the complete SaaS solution with the “Ferrari” stack: Fivetran, Snowflake / Bigquery, Looker.
This stack works well and is quite easy to setup but gets expensive to run when your platform scales.

You might wonder, but how expensive it can get? Estuary performed a price analysis of Fivetran that will help you get a first feeling:

So, data teams must decide between:
Quickly launching their platform with off-the-shelf SaaS, risking difficulty justifying credit expenses when adding more data sources.
Self-hosting open-source tools, which may delay the platform's launch and invite pressure from management for faster delivery.
Choosing the full SaaS path makes sense for companies with:
Easy access to cash (which was the case pre-2022 with low-interest rates and easy VC funding).
Gold in their data (a rarity, probably only the case for GAFAM and few exceptions).
A management team that strongly believes in the potential of data to drive internal efficiency improvements (~ no need for ROI).
However, it may not be viable or could be too risky for more and more companies that can no longer justify high credit fees. These companies are probably less attractive to large SaaS proprietary vendors who mainly target larger accounts. Nevertheless, they constitute a growing portion of the market.
The problem of usage-based pricing
All open-source data tool providers now use usage-based pricing, where you pay according to your usage of the service.
This billing format means: “ok we are saving you the setup cost, now you pay a markup for the rest of your life”.
It's essentially the same concept as in real estate: when you cannot afford to buy a house, you pay a monthly rent. Need a larger house? No problem. Increase your rent by x%, and you can move from an x-small to a medium (ware)house ^^.
The usage-based pricing model can sometimes feel like a trap as your bills skyrocket when your platform scales up.
But what if a data team wants to take a long-term approach and buy (self-host) a data platform? This means making a reasonable upfront R&D investment to lower future operating costs.
Buying vs renting a stack
Some companies like restack, plural, or doublecloud are attempting to address this self-hosting challenge.

They offer managed Kubernetes clusters deployed in your cloud to host open-source tools.
I find these initiatives interesting. However, I feel that their pricing model does not align well with usage.
These solutions save you a lot of time in setting up your stack and provide value at the beginning of the platform lifecycle. That’s great but why pay recurring fees for it?
You will probably end up with the same problem as with managed services: low cost at the beginning but a platform not able to scale in terms of cost when the initiative grows.
This is the pricing model I'd prefer for a tool that assists me in setting up an open-source data stack:
a tool for rapidly setting up a data stack with a one-off purchase
consulting-based services to address issues when necessary
infrastructure costs are paid directly to the cloud provider (with the possibility to use credits or negotiated rates)
Back to one-off software purchase?
This aligns with a growing trend in the software industry, moving away from recurring/usage-based fees and towards one-off payments. Here are some examples:
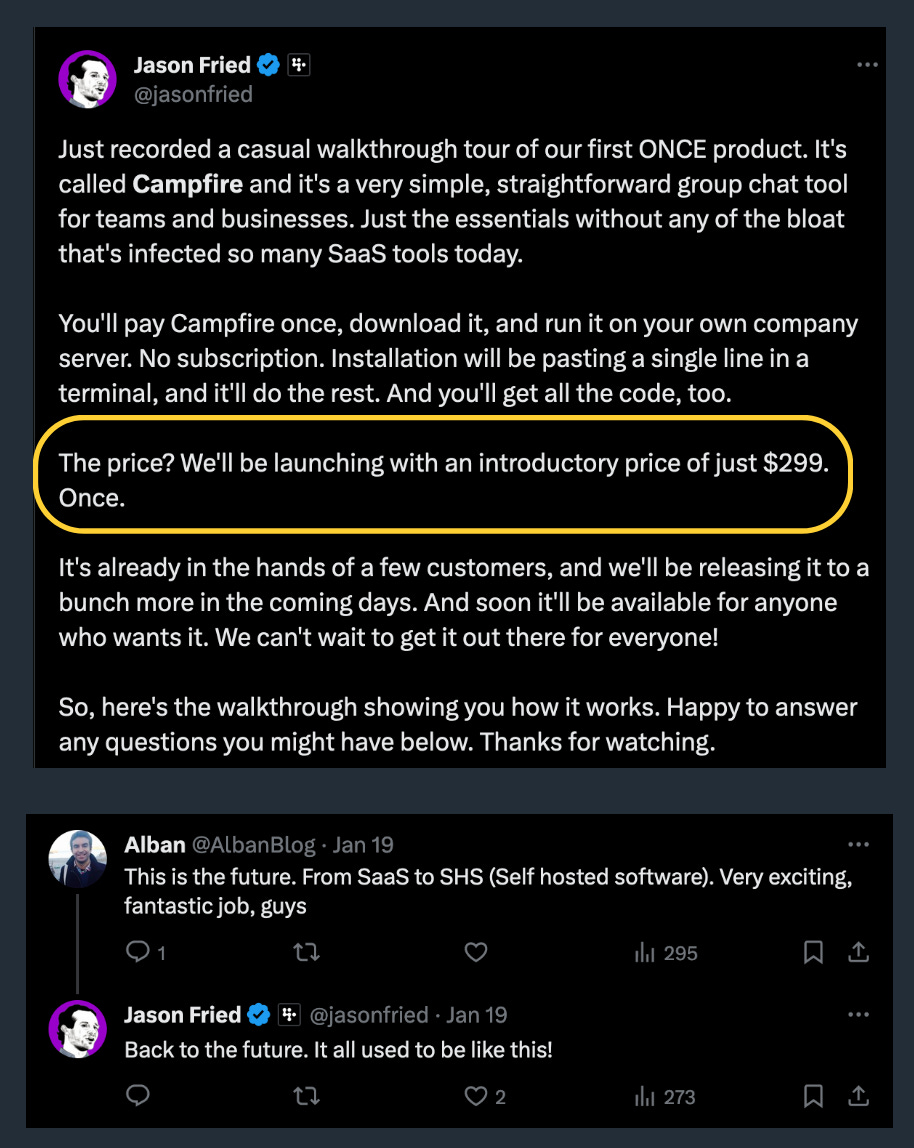
Compfire, a Slack competitor, by
and 37signals
Shipfa.st, a SaaS boilerplate by
I believe this may be the best model to address the data stack setup problem: a one-time boilerplate purchase coupled with consulting services.
Recurring subscriptions often result from VC-funded companies, aiding in valuations and resales based on MRR and churn rates, but they may not suit all types of software.
As a data vendor, you may leave some money on the table in the short term, but you'll gain happier customers, ultimately leading to more business :)
Lowering the entry barrier for setting up and operating a data stack is likely to allow many more companies to embark on their analytics journey as well, resulting in a larger pie to share among data tool providers.

Thanks for reading,
-Ju
I would be grateful if you could help me to improve this newsletter. Don’t hesitate to share with me what you liked/disliked and the topic you would like to be tackled.
P.S. you can reply to this email; it will get to me.
https://once.com/