
The Hidden Side of Iceberg
Ju Data Engineering Weekly - Ep 37

In this week's release, I wanted to take a deep dive into Iceberg.
Indeed, Iceberg and other open table formats such as Delta and Hudy are opening a new wave of innovation in modern data platforms.
In a previous article, I described the benefits that Iceberg could bring and specifically how it could open the way to multi-engine stacks.

In this week's release, I want to go deeper into Iceberg and explain in more detail how it works.

Open Table Format
An open table format is a standard for interacting with data files inside a data lake.
With Iceberg, Hudi and Delta, a new generation of table formats has emerged providing capabilities similar to those of an SQL table:
ACID Consistency:
Users can update tables with safe transactions, ensuring that data remains consistent even if a transaction fails.
If two or more writers simultaneously write to a table, mechanisms are in place to ensure that the writers are aware of what the other writers have done.
Schema Evolution
Allow the addition of columns to a table while maintaining transaction safety.
Time Travel
Users have the ability to reference a previous version of a table.
Iceberg Open Table Format
Iceberg achieves these capabilities by defining a set of static files that contain metadata.
These statics files live along with the actual data which are usually saved in parquet files.
The compute engines use these static files in order to efficiently write and read data from/to the parquet files.
Iceberg Open Table Format is composed of:
metadata files
vX.Metadata.json files specify the current version (snapshot) of a table.
Each update to a table creates a new metadata.json file.
This approach enables access to previous versions of a table by simply referring to previous metadata files.
manifest and manifest list files
Depending on the partition scheme chosen by the user, the Parquet files are organized so that data is distributed across files following the partition key.
Manifest files contain statistics about these partitions’ min/max limits.
These statistics help the engine perform read/write queries efficiently without having to scan all the data.
a catalog
The most important responsibility of a catalog is tracking a table’s current metadata. When an engine wants to query a table, the catalog should point to the current table's snapshot (metadata json file).
Below is a schema illustrating the organization of metadata files and manifest files:

Reading Data in Iceberg
Here are the steps that an engine accomplishes when reading data from Iceberg:
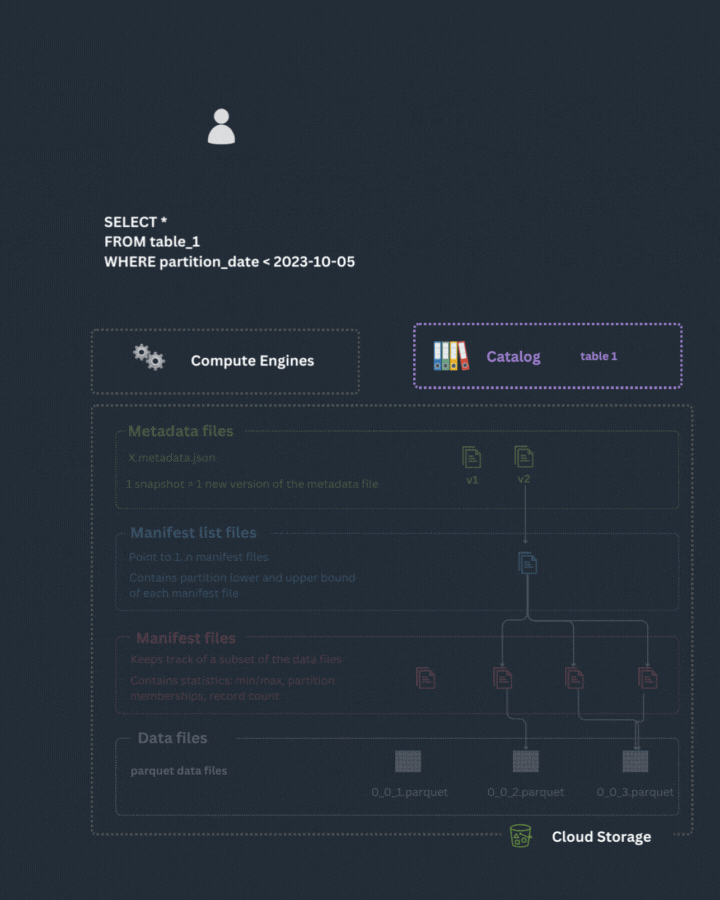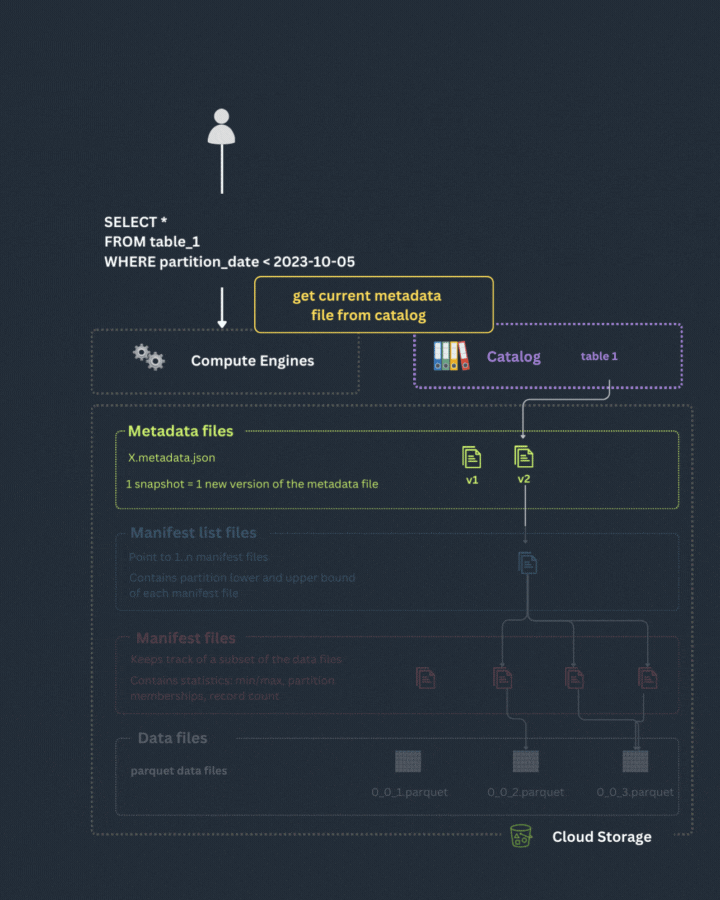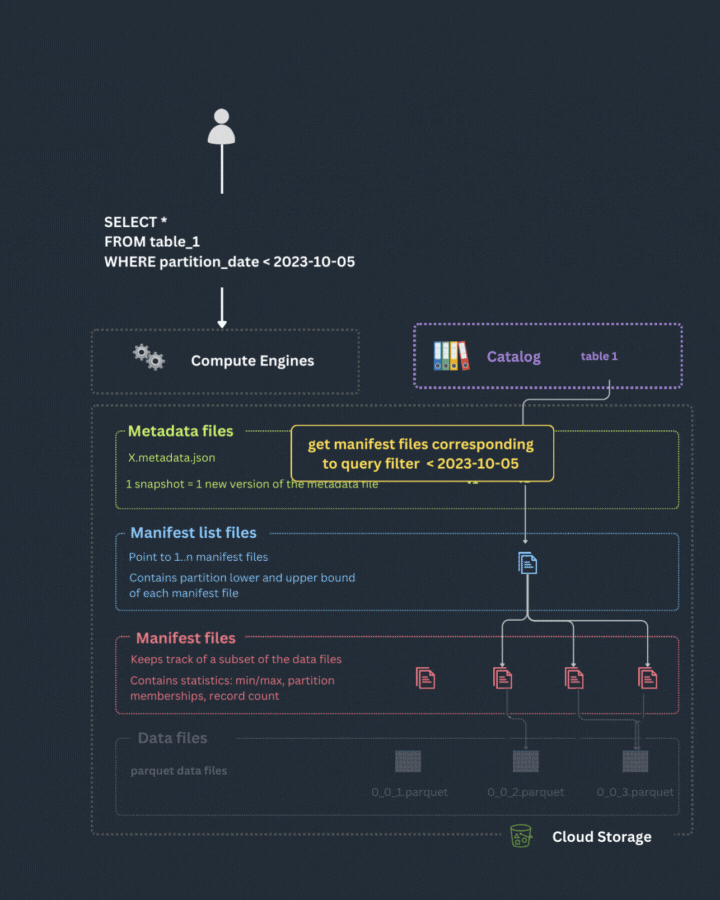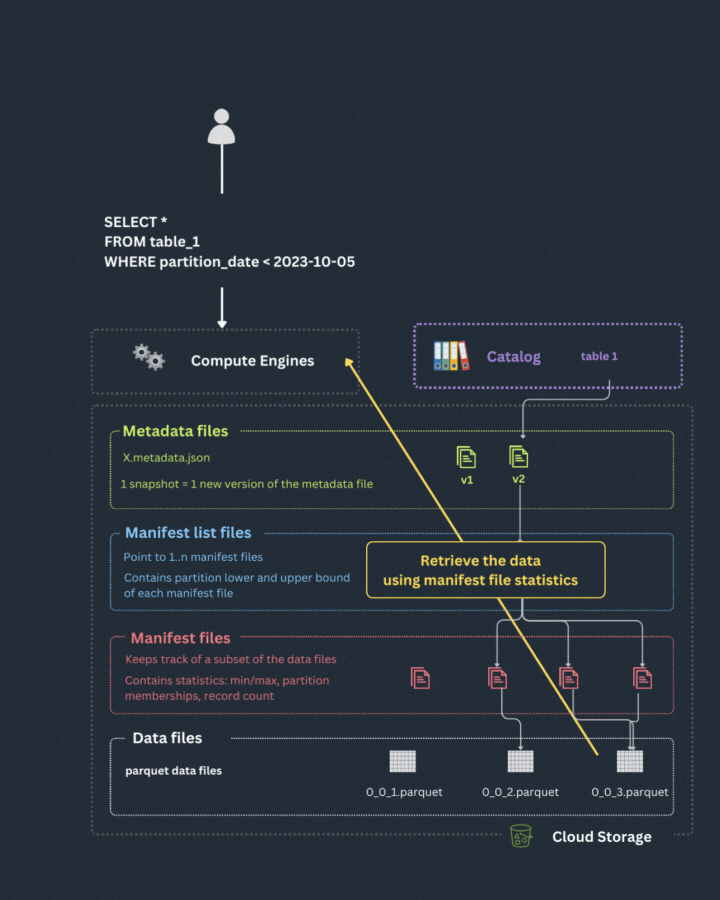
The engine receives a query from a user.
The engine requests the catalog to obtain the latest snapshot for the queried table and the location of the manifest file list.
The engine leverages partition upper and lower bounds contained in the manifest file list to access only the relevant manifest files for the user query.
The engine uses these manifest files to access only the relevant parquet files and retrieve the data for the user
Write Data in Iceberg
Here is how writing data in Iceberg works:
The engine reaches out to the catalog to get the path of the current metadata file and information about the partition schema.
The engine creates/updates parquet files according to the table partition schema.
The engine creates/updates the relevant manifest files with new statistics.
The engine creates a new metadata file.
The engine checks for conflicts and points the catalog to the new metadata file.

Catalogs
Iceberg specifies only the interface to the data but not the implementation of the interaction itself.
Tasks like creating, dropping, and renaming tables are the responsibility of a catalog.
These methods should ensure the atomicity of the transactions.
However, some file storage systems don't guarantee data integrity when concurrent operations are performed.

In Iceberg, if a writer discovers that the snapshot on which the update is based is no longer current, the writer must retry the update based on the new version.
For this reason, depending on the storage used, the catalog needs to use an external system (e.g., DynamoDB) to ensure that the state remains consistent.
Different implementations of such catalog exist:
Hive Metastore Catalog
AWS Glue Catalog
REST Catalog
ect
These catalogs differentiate themselves with:
the storage they support
the need to setup and maintain additional services
managed or not by a provider (AWS Glue, tabular.io, Snowflake)
cloud compatibility/integration (e.g. AWS Glue Catalog and AWS Athena)
support for multi-table transactions as for REST Catalog
I will prepare a future post to list all existing catalogs and their advantages and disadvantages.
Snowflake Iceberg Tables
This summer Snowflake has released more information about how they plan to integrate Iceberg into their platform.
They will offer the 2 options:
Externally managed Iceberg Table
Snowflake engine can query (read-only) data from an Iceberg table managed by an external Catalog.

Externally managed Iceberg Table Snowflake managed Iceberg Table
Snowflake manages for you the catalog and offers a REST endpoint that you can use to interact with Iceberg (and write to Iceberg).


They have released the first figures about query performance.
Interestingly, there is no performance difference between Snowflake tables and Snowflake-managed Iceberg tables.
This is a really big deal because it means teams can migrate all their tables to Iceberg without losing performance while also opening up the possibility to query them using another engine.

The performance gains are explained by the way Snowflake writes Parquet files, which is optimized to generate Parquet files with enhanced statistics (as explained earlier with manifest files).
Duck DB Integration
I could not finish this post without mentioning DuckDB.
DuckDB has recently launched the first version of its Iceberg integration.
From what I have seen, the support is currently very limited as it only supports read operations on a specific snapshot of an Iceberg table for now and has no proper catalog integration.

I will prepare a post in the coming weeks on the state of different engines and catalog compatibilities.
The demand for Icebergs is increasing significantly, so I expect that the different integrations and compatibilities will evolve rapidly.
Sources:
Iceberg doc
Dremio - Apache Iceberg: The Definitive Guide
Thanks for reading,
-Ju
I would be grateful if you could help me to improve this newsletter. Don’t hesitate to share with me what you liked/disliked and the topic you would like to be tackled.
P.S. you can reply to this email; it will get to me.
So, Iceberg basically stores all the historical versions of the table in different parquet files? I know parquet is efficient but won’t it still cause storage overload given how frequently updates are made to tables? Or is there a limit on the number of historical versions it stores at any given point?