
Time for AI Coding to Turn Boring ?
Ju Data Engineering Weekly - Ep 101

I started 2026 by writing a Boring Engineer Manifesto.
I write this post with the need to somehow put on paper the intuition I have built over the last few years.
Five months later, I feel the same need again — but this time focused on AI coding workflows.
Every week brings new models, new tools, new trends, and new CEO hot takes.
Reflecting on the last few months, this feels a lot like the dynamical systems courses I had at university.
An initial state.
A perturbation.
And then a convergence toward a new stable equilibrium with wide back-and-forth swings in between.

This post is a brain dump of everything I’ve learned about the topic over the last few months.
Where I see things starting to converge.
Maybe the premise of a boring AI coding workflow ? Finally.
Note: This post is not AI-generated. I wrote it manually and only used a single prompt to edit it:
“Correct grammar: <> ” :)
No baby sitting
This was my first step this year: getting the most out of a single agent session.
To do that, I had to stop babysitting the agent.
No more permissions prompts.
No more letting my laptop running.

I now rent a VPS on OVHcloud and run all my work from there.
My agents run there continuously in all persmission mode.
I just use a tool that spots dangeroud command and block them.
And this works perfectly: agents don’t get interrupted and keep running until they finish their tasks.
No Agent Swarms
I got caught up in the agent swarm hype at the beginning of the year.
It was definitely the opposite of “boring” — but still worth exploring.

I tested various tools and workflows, but I eventually came to the following conclusion:
Writing the code was not the bottleneck for me anymore.
The real bottleneck was being able to provide enough spec, context, and direction to properly feed the machine.
And once I realized that, the whole premise of agent swarms started to break down for my use case.
Building a swarm of agents makes little sense if I can’t reliably feed it.
Plan Plan Plan
I learned this the hard way.
If you don’t feed the machine correctly, agents still aren’t good enough to build reliable software consistently.
They tend to overcomplicate things, over-engineer solutions, take shortcuts, and drift away from the original intent.
A common way to overcome this is to:
have good guardrails in
AGENTS.mdspend time writing a good plan
Usually, that’s enough to constrain the model and get good results.
But I find that writing plans is not that easy.
Super detailed plans start to feel like writing the code directly…
Vague plans lead to disasters.
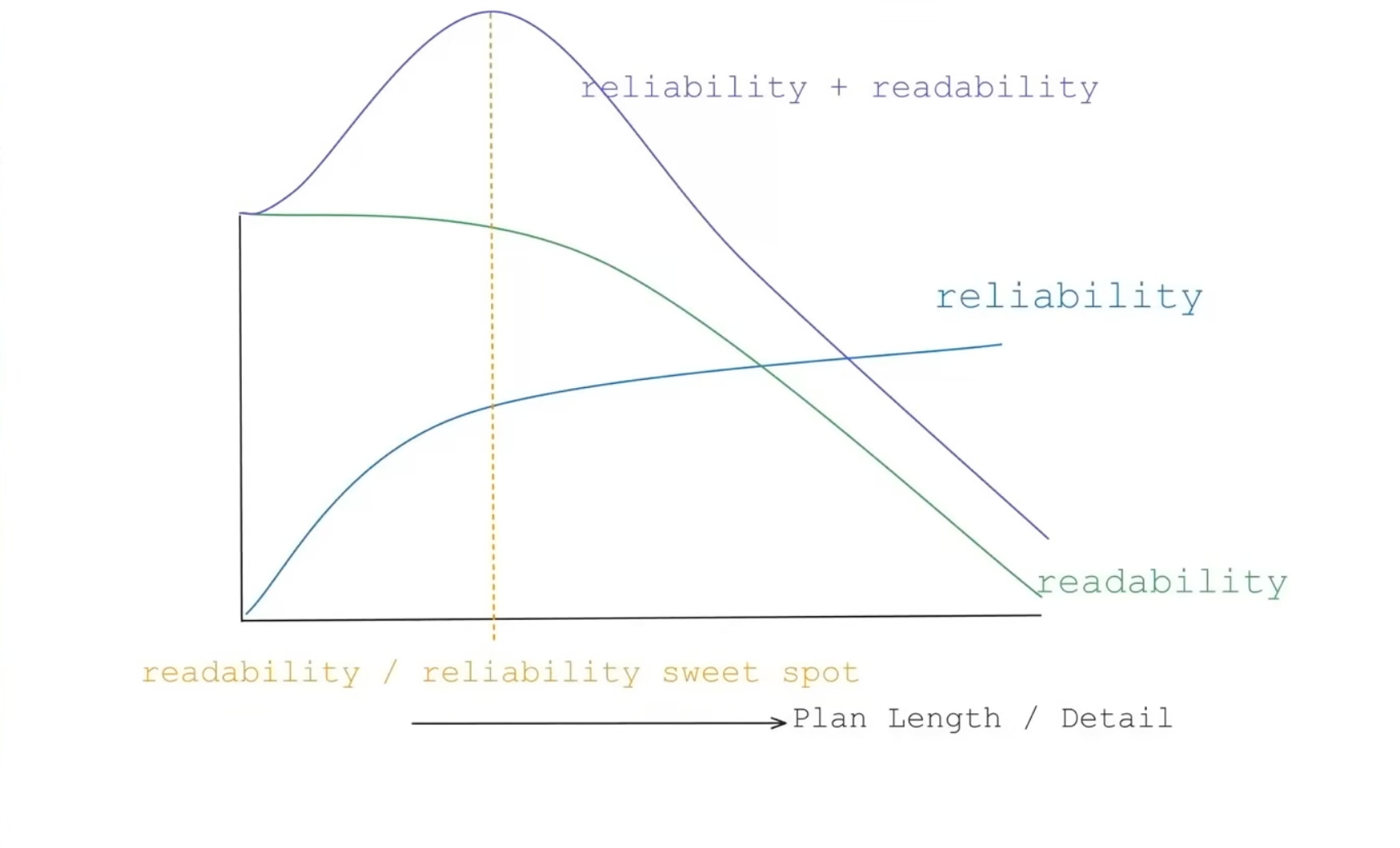
Building the intuition for what to constrain and what not to constrain is probably the real craft now.
Engineering craft is now:
Finding the right plan at the right level of abstraction
Knowing what to put in the plan — which means knowing what you actually want
… And review
I built some advanced review workflows where several agents using different models review each other’s code.
It worked pretty well — especially when asking Codex to review Claude-generated code.
But as they both lack common sense I still need to review things manually.
I review the overall shape of the code and the details of the most important sections, not every single line.
And that’s part of the craft as well:
Choosing what to review, and at which level of detail.
To do that well, you need to understand your infrastructure, your codebase, and the tradeoffs inside it.
There is no way around.
Up-Skilling
This has been a real aha moment for me over the last month: agent skills.
When they’re well written, they can convey an enormous amount of value for very specific tasks.
The skill I’ve been the most impressed with is impeccable for design. It produces much better designs than a raw model alone.
Personally, every time I do something that I may need later, I try to turn it into a skill.
All my skills are version-controlled in a repo, and I have a simple dispatch script that copies them into ~/.agents/skills on my machines.
But there’s a real danger with this approach: each skill is referenced in the harness system prompt.
So if you accumulate dozens of skills in ~/.agents, you end up polluting the context on every turn, which degrades the quality of the output.
So I’m very careful about what actually gets dispatched globally, and I try to isolate skills to specific projects as much as possible.
OSS to save us
OSS models
Like many developpers after couple months of subusised hoony moon, I have started to get nervous about my dependainy to claude code.
I started playing with OSS models and honestly, I’ve been more than impressed.
I now run Qwen 3.6 on my Mac M3 and use it for all kinds of tasks: research, testing, and bug fixing.
When you run your own model, it feels like entering a new world of freedom.
No “x% of quota remaining” warnings.
No strange feeling of giving my data away.
Just my Mac sweating next to me :)
Note: this is the setup I used.
OSS harnesses
The same lock-in concerns I mentioned about models also pushed me to look for alternatives to Claude Code itself.
That’s where Pi started to get really interesting.

It’s a super lightweight harness designed to be extensible through plugins.
The community is incredibly productive, and almost all the features you find in Claude Code or Codex are already available through plugins.
Most importantly: it works with almost every provider.
Except one: Claude Max Plan :)
I’ve been using it for the last few weeks, and I’m honestly super satisfied.
My model usage has naturally gravitated toward a wider diversity of models:
GPT-5.5 (Pro Plan) for coding
DeepSeek 1.4 via OpenRouter for coding
Qwen 3.6 via Tailscale (running on my Mac) or OpenRouter for general tasks + simple coding
Gemini 3.1 for reviewing
Grok for reviewing
Having a single multi-LLM harness makes it incredibly easy to mix models together.
One plugin I use a lot is the subagent plugin. It lets you combine reviews from multiple models within the same session. And honestly, it works very well.
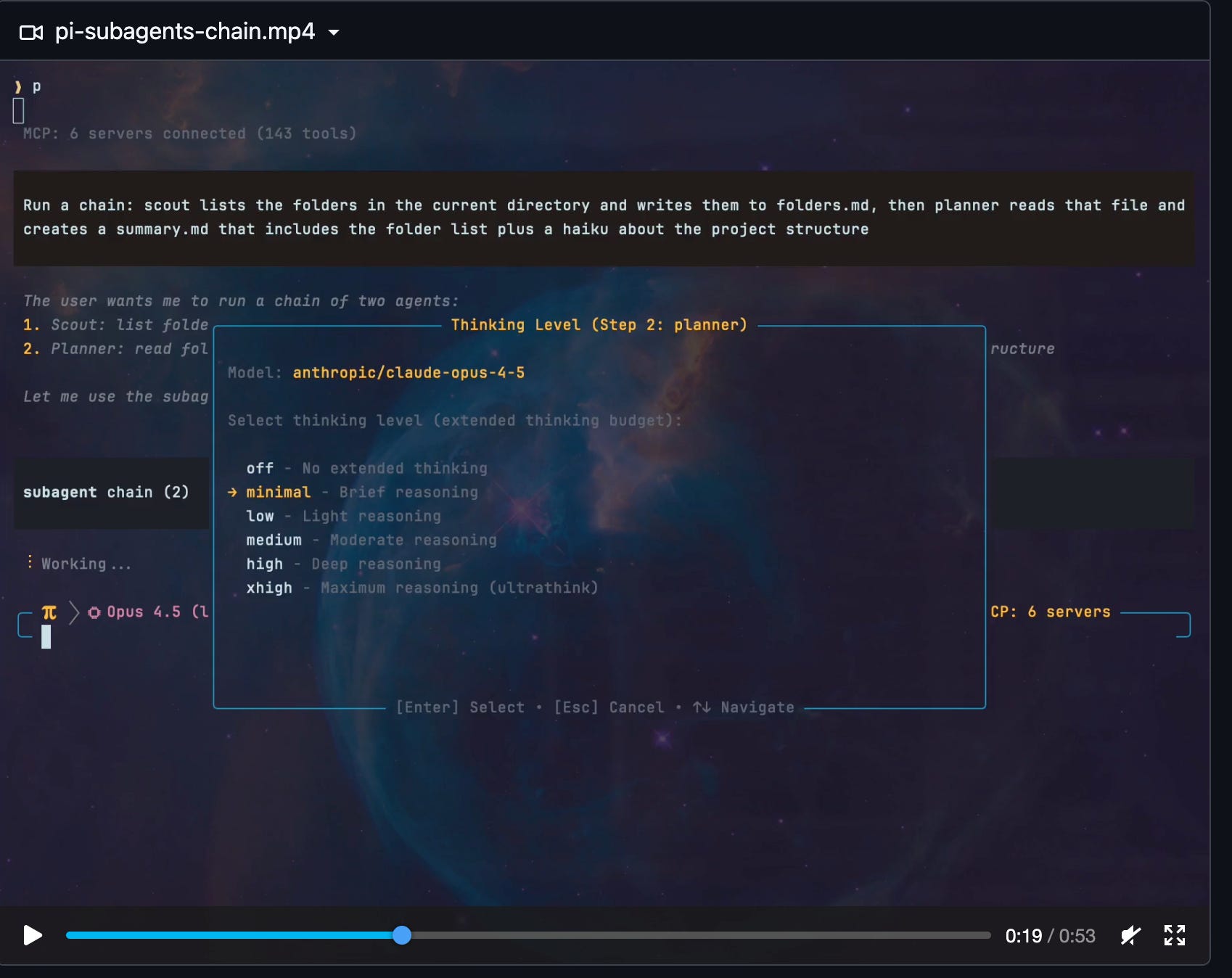
Resisting the tool tsunami
For the rest, I avoid spending too much time testing every new tool popping up in my feed.
My reasoning is simple:
If a tool is truly good, it will eventually get implemented into the harnesses like Claude Code, Codex, or Pi.
The time I’d lose setting it up, integrating it, and maintaining it usually isn’t worth it.
I couldn’t resist, however, playing with the OpenClaw wave: especially to automate some admin work for my company.
I made the classic mistake: I spent time setting it up, it broke many times, and the whole thing became a distraction.
Eventually, I just passed:
the OpenClaw GitHub repo
the Hermes GitHub repo
the Pi GitHub repo
…to my agents, and I one-shotted my own minimal “boring-claw” setup that perfectly fits my needs: one Slack channel per project, each connected to a pi session running on my VPS.
It has now been running for weeks and has required almost zero maintenance and reduced security risk..
This is everything I’ve learned over the past few months.
The convergence is probably temporary, but writing this has helped me measure how much things have evolved in such a short time.
I hope you got something out of this.
Do not hesitate to respond to this email with your experience.
Or, even better, share it publicly in the comments.
Thanks for reading,
Ju
Loved this honest brain dump Julien! The planning sweet spot point is something I've felt but never put into words. Curious how you manage context across long VPS sessions?
Wow, great recap! The material was very useful for me.
PI and QWEN OSS is something definitely worth knowing. I'm still a little bit old-fashioned and think coding is only one part. I tried to solve the context part for myself and came to https://github.com/kpruntov/SpecLoom - it traces requirements to code with AI, providing the plan part you are talking about. But it is much more manual than the tools you describe and requires babysitting for sure.
Can you tell more about the VPS setup you use and how you control work with sessions there - a simple remote terminal? Any alerts on the completeness of the task and controls?