

The data industry is moving towards commoditization.
Many new tools and products have emerged due to increased funding in the field.
However, this rapid expansion has led to a fragmented and less efficient user experience.
Consequently, data engineers often face manual and tedious tasks to integrate these tools into a single platform.
A new wave of innovation is coming pushing toward a standardization and democratization of data platforms …
… just like any tech hype cycle:

In this article, I explore the present state of standardization within the industry.
Example from an Adjacent Industry: Cloud Infrastructure
I believe the cloud infrastructure segment is a few years ahead of data engineering in its lifecycle.
It has transitioned from manual infrastructure setup using the console to reproducible cloud infrastructure with tools like Terraform.
Even though Terraform facilitates reproducible infrastructure deployment, users still need to specify each resource individually.
Currently, new frameworks are emerging, built on top of low-level frameworks, offering constructs to simplify the development of applications.
Projects like Serverless, SST, and SDK are building constructs that bundle resources together in a standard way.

AWS SDK classifies for example its constructs across 3 levels:
L1 constructs = no abstraction, maps 1:1 with AWS resources
L2 constructs = L1 constructs + standard configuration
L3 constructs = patterns that can contain multiple resources that are configured to work together to accomplish a specific task
I find the SST’s design principles to build constructs really inspiring:
- Zero-config: “one of the design principles of SST is to make sure that it works out of the box. It comes batteries included, making it easy to get started.”
- Progressive disclosure: “the basic configuration for these constructs are simple, easy to understand, and readable. But they still allow you to progressively customize them for more complex use cases”
- Having an escape hatch: “you might run into cases where you are trying to do something that a construct does not support. In these cases, you can fallback to using the native CDK constructs instead. This escape hatch ensures that you are not locked into using SST's constructs.”
Data Engineering: 'As-Code' = ✅
What about data engineering?
Data Engineering is going over the “as-code” revolution.
Many tools in the field are now deployable using code.
dbt models are defined using YAML and SQL.
Airbyte has a Terraform provider.
Meltano pipelines are defined in a YAML file.
Snowflake has a Terraform provider.
BI tools like Rill and GoodData can also be configured using code.
Orchestration tools like Prefect, Dagster, Airflow (using Python), and Kestra (using YAML) all allow for code-based definitions.
The infra constructs mentioned above are built in top of the same API (e.g., AWS), but in data engineering, the challenge lies in building constructs across multiple tools.
Indeed, every tool comes with its unique semantics, concepts, and interface (Python, Terraform, YAML) making the creation of unified "data pipeline" constructs still difficult.
Data Pipelines constructs
As illustrated in the Gartner cycle graph, the "slope of enlightenment" phase involves the refinement of methodologies and the establishment of best practices.
In his last article
highlights the absence of best practices and patterns in numerous data setups.During peak MDS, I noticed that best practices in data slipped backward. Through my consultancy, I’d seen many horror shows of data teams doing some wild stuff in the MDS.
I believe the next wave of innovation in data engineering will focus on pipeline constructs that enforce data engineering patterns and best practices.
Similar to how the Serverless Framework empowers developers to create REST APIs with minimal configurations, we will see pre-configured data pipelines constructs.
We need to move from one abstraction layer above, from :
Each building block can be parametrized in a YAML file.
To:
One YAML file to define a complete pipeline end-to-end.
Config interoperability
This vision will become achievable when configurations are interoperable across various tools.
This has already happened in some places.
For example, dbt now integrates with orchestrators like Dagster and Airflow, allowing them to incorporate dbt projects into their DAG.
They can parse a dbt project and rebuild its DAG completly:


In Dagster, users can provide extra parameters to Dagster through the meta section of a source.
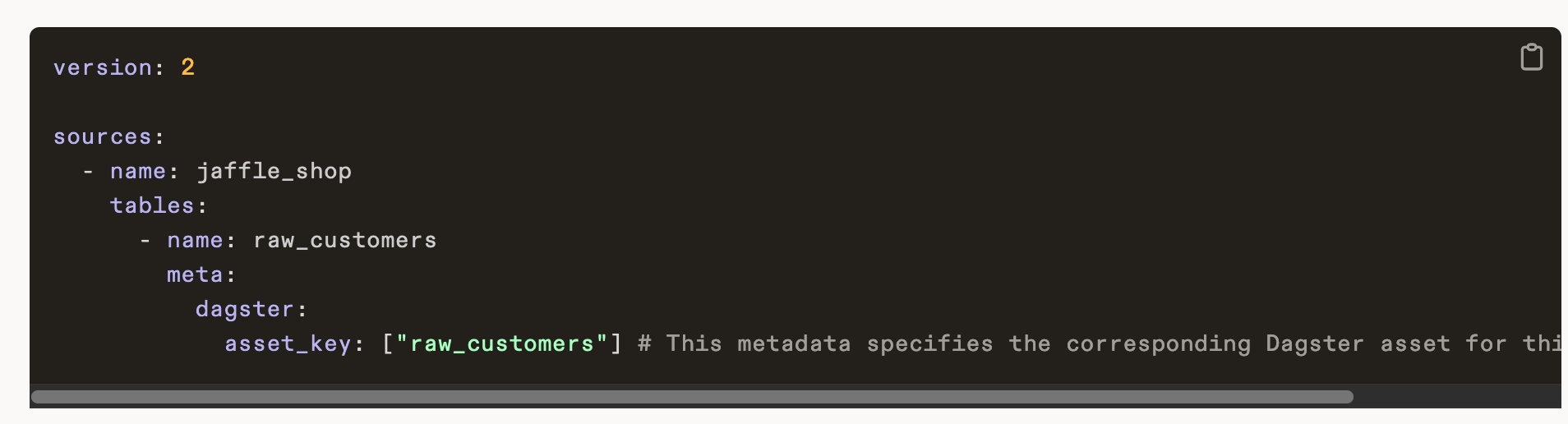
In this manner, users can define both data ingestion and downstream transformation in one format (YAML) from a single location (dbt source + dbt models).
Even if this example is focused on dbt, it demonstrates the potential unlocked by config interoperability.
Moving toward Domain Specific Language (DSL)
Semantic standardization is a critical aspect of config interoperability.
Indeed, each data tool typically introduces its own concepts and semantics:
For data ingestion, Meltano relies on “plugins”, “extractors”, and “loaders”, while Airbyte uses “connectors”, “sources” and “destinations”.
In terms of orchestration, Dagster uses “Software Defined Assets”, whereas Airflow employs “tasks” and “operators”.
Furthermore, Snowflake features dynamic tables, while Databricks offers Delta Live Tables.
We require a standardized method for defining concepts and transitioning towards a domain-specific language, which would signify the next level of abstraction in our stack.
We might already have a standardized format in YAML, but there's a need to establish a consistent method for expressing our expectations and requirements.
Databases have SQL:
Wherever I execute CREATE TABLE I know what I will get.
Infra has Terraform and HCL:
Wherever I write resource … {} I know what I will get.
Data pipelining requires its own semantics.
I would dream of being able to write:
source:
- from: zendesk
- to: snowflake
- engine: airbyte
- target_lag: 60sand get a Snowflake table refreshed every 60s with the latest version of each record.
Thanks for reading,
-Ju

I would be grateful if you could help me to improve this newsletter. Don’t hesitate to share with me what you liked/disliked and the topic you would like to be tackled.
P.S. you can reply to this email; it will get to me.
Great write up! It move the debate around configuration/declarative semantic in the right direction IMO.
In the end it's all come down to how API are open or not... Like, building intercompatibility between tools is *easy* when API can be connected together... The User Interface (would be it UI, Terraform, CLI, TUI, etc.) doesn't matter much and is up to the end user.
Agree, can't wait for that.In the meantime I'll try a yaml basen templets approach to generate dynamic tables on Snowflake