
Write-Audit-Publish (WAP) Pattern
Ju Data Engineering Weekly - Ep 57

Ensuring safe code releases is a constant challenge in software engineering.
One strategy is blue-green deployment, where two identical environments are set up.
The blue environment hosts the current application version, while the green one runs the new version.
Once testing has been completed on the green environment, live application traffic is directed to the green environment, and the blue environment is deprecated.
This setup allows for easy rollback if needed.
But what about data engineering?
In data engineering, our code, like SQL transformations, is closely tied to the underlying data it processes.
This is where the Write-Audit-Publish (WAP) pattern comes in: blue-green deployment for data engineering.
Write-Audit-Publish (WAP)
In many data engineering projects, materialization and testing occur sequentially.
First the data is materialized (e.g. dbt run)
Then, it undergoes testing (e.g. dbt test).
However, this workflow presents a problem: if an error is detected during testing, it's already too late—the corrupted data has already been released to downstream systems.
Although the concept of staging data for testing before production has existed in data warehousing for some time, the term "Write-Audit-Publish" (WAP) gained popularity after a talk by Netflix in 2017.
The goal of the WAP pattern is to stage data in a temporary environment for testing before releasing it to production:
1: Models are materialized in a temporary environment
2: Data quality tests are run there
3: If the data tests pass, the models are moved to the prod environment and made available to downstream consumers.
Despite its intuitive nature, this pattern isn't widely implemented:

Let's explore how to implement the WAP pattern using dbt or in a data lake environment with Iceberg and Nessie.
WAP with dbt
Option 1: Schema swap
Modern cloud warehouses offer features that make implementing the WAP pattern quite simple:
object swapping
The workflow is then as follows:
dbt run-operation clone_schemaThe
clone_shemamacro is a simple wrapper around the command:CREATE SCHEMA audit CLONE prod;Write + Audit :
dbt build --target auditPublish:
dbt run-operation swap_schemaThe
swap_schemais a simple wrapper around the command:ALTER SCHEMA prod SWAP WITH audit;
Option 2: dbt clone
dbt clone is a new command in dbt 1.6 that leverages native zero-copy clone functionality.
The dbt clone command clones selected nodes from a state to the target schema(s).
dbt released some recipes on how to implement WAP with this command:
clone prod schema to an audit schema
dbt clone —target audit —state manifest_prod.jsonrun and test the model in the audit schema:
dbt build --target auditclone objects from audit schema to prod schema:
dbt clone —target prod —state manifest_prod.json —full-refresh
Note: In both options, you will need to update the built-in generate_schema_name macro to select a schema or database based on the --target option.
WAP with Iceberg branches
Iceberg is an abstraction layer for data files stored in a data lake, providing a standardized method for storing file statistics.
The metadata of an Iceberg table maintains a snapshot log, capturing the changes made to the table over time.
These logs enable various functionalities, such as time travel, allowing users to revert to previous versions of the table.
Additionally, historical snapshots can be linked together.
Just as commits in Git are linked together to form branches, snapshots in Iceberg can be linked together to create branches within the table's history.
Branches are independent lineages of snapshots and point to the head of the lineage.
In this paradigm, similar to updating code in Git, changes made to data are grouped in a branch, each with its independent lifecycle.

First, a new branch is created:
ALTER TABLE db.table CREATE BRANCH `audit-branch` AS OF VERSION 3 RETAIN 7 DAYS;Changes are made to the table:
SET spark.wap.branch = audit-branch
INSERT INTO prod.db.table VALUES (3, 'c');Tests are run on this branch, and if they are successful, the user can merge them into the main branch.
CALL catalog_name.system.fast_forward('prod.db.table', 'main', 'audit-branch');When merging, the Iceberg catalog simply changes the snapshot associated with a table.
Currently, branching in Iceberg is at the table level. However, multi-table branching can be done with Nessie.
WAP with Nessie

Nessie provides an implementation of an Iceberg catalog that allows for multi-table transactions.
This makes it possible to run WAP over several models and check cross-table consistencies.
Nessie goes a step further in the git semantics and implements the following concepts:

Similar to PyIceberg for Iceberg, Nessie provides an API via the PyNessie library.
This makes it possible to implement a complete WAP workflow in Python.
Bauplan released a very good example last week of implementing a WAP workflow on top of PyIceberg, made possible by the recent release of write support in PyIceberg.
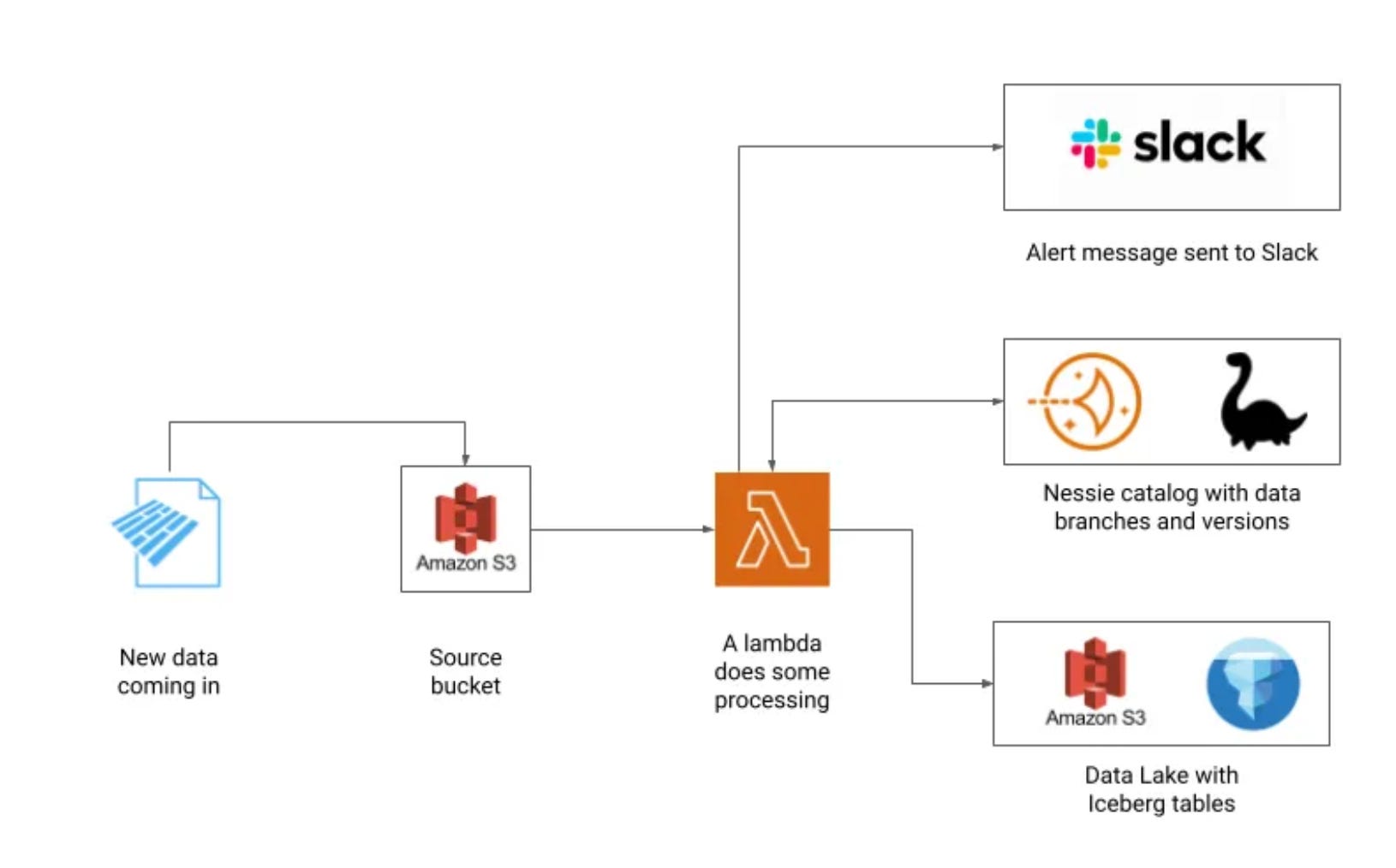
Their WAP workflow looks like the following and is 100% written in Python and hosted in a simple Lambda!

It's exciting to see more and more features like cloning, and time travel, usually reserved for the warehouse being possible with the data lake tables.
This makes the implementation of patterns like WAP much more accessible and straightforward throughout the stack.
Thanks for reading,
-Ju

I would be grateful if you could help me to improve this newsletter. Don’t hesitate to share with me what you liked/disliked and the topic you would like to be tackled.
P.S. You can reply to this email; it will get to me.
SQLMesh does thing similar by using views and then "pointing" the view to the underlying physical table you want to use for that environment.
Another approach we used at my old company was having multiple versions of our pipeline run in parallel (production + pre-release) but based off of the same input data source. Then we would have jobs compare the results of the two versions and if things aligned with our expectations we'd then push our code to production. We would only run the pre-release version when needed since it was an expensive process but worked well for our use case. It also worked well since the input data source we received didn't change much and we rarely needed to make changes to that step of the pipeline.
Thanks Julien for the explanation here! Definitely something to explore
Still, I'm wondering how complicated it is to implement in real life 🤔
As pointed out in the post you pointed out:
"And in fact, we cannot stress this enough, moving to a full Lakehouse architecture is a lot of work. Like a lot!"
Is this work really valuable when a lot of subjects like governance, GDPR, data culture, etc. are very late compared to data warehouse architecture and tooling around quite mature now (dbt, SQLMesh, etc.)
Don't get me wrong: lakehouse architectures are the future; but might be a bit early to move on now. WDYT?