
I watched 10 hours of Data Council videos so you don’t have to.

Here are 10 ideas that were presented and that I found super insightful:
How to improve data productivity?
Iaroslav Zeigerman - Tokibo data
Impedance mismatch in data.
Pete Hunt- Dagster
Multi-engine data stack: why now and how?
Wes McKinney - Posit
Multi-engine data stacks combining DuckDB and Snowflake.
Michael Eastham, Chief Architect, Tecton
Jake Thomas, Manager - Data Foundations, Okta (ex- Shopify, Cargurus)
Composable stack for AI.
Chang She, Co-founder & CEO, LanceDB
Will open table formats converge or diverge?
Kyle Weller, Head of Product, OneHouse (ex- Azure Databricks)
How to build a new database in 2024?
Andrew Lamb, Staff Engineer, InfluxData
How to prepare web-crawl data to train an LLM?
Jonathan Talmi, Manager of Technical Staff, Cohere
A/B testing for data professionals.
Timothy Chan, Head of Data, Statsig (ex- Facebook)
How to prioritize for maximum impact as a data team?
Abhi Sivasailam, Founder & CEO, Levers Labs
1 - How to improve data productivity?
Speaker: Iaroslav Zeigerman, Co-Founder/Chief Architect, Tobiko Data (ex- Apple, Netflix)
Iarsolav proposes three ways to enhance productivity when working with data:
Data versioning: Tracking historical snapshots of data models.
Virtual Data Environments: Establishing virtual pointers to the physical layer.
Automatic Data Contracts: Automatically detecting if a change is breaking or not.

The talk is packed with many excellent ideas that lay the foundation of SQLMesh.
SQLMesh has been on my to-do list for a few weeks, and it's definitely a tool I want to explore further, especially in the context of a multi-engine data stack.
2- Impedance mismatch in data
Speaker: Pete Hunt, CEO at Dagster.
Pete explains why workflow-based orchestrators like Airflow and Prefect add complexity to debugging and maintaining a data stack.
He argues that orchestrators should be built around the concept of data assets instead.

3- Multi-engine data stack: why now and how?
Speaker: Wes McKinney, Principal Architect, Posit PBC (co-founder of Voltron Data)
This is one of my top 3 videos from the summit, by Wes, who has inspired many of my content in the past.
He describes why composability is the next step in the evolution of our data infrastructure.
He introduces as well the tools and projects that provide the building blocks to make it possible.



4- Multi-engine data stacks combining DuckDB and Snowflake
In line with Wes's previous video, these are two talks that actually implement such a multi-engine data stack by combining DuckDB and Snowflake.
Speaker: Michael Eastham, Chief Architect, Tecton
In the first one, Michael presents the design of the data stack at Tecton, where they use DuckDB to perform aggregation and distribution of data downstream of Snowflake.

This resonates a lot with Jake Thomas's presentation where he exposed how they use DuckDB to run pre-computation upstream of Snowflake.
Speaker: Jake Thomas, Manager - Data Foundations, Okta (ex- Shopify, Cargurus)
I dedicated a complete article to this talk a couple of weeks ago:

5. Composable stack for AI
Speaker: Chang She, Co-founder & CEO, LanceDB (previously TubiTV, 2nd major contributor to Pandas)
You've grasped it: composability is a recurring theme in many talks.
Chang approaches composability from the AI perspective.
Indeed, AI stacks are quite specific: they primarily store unstructured data and distribute them to various workloads with different requirements: training, querying, and serving.
The challenge lies in storing these unstructured data in a manner that allows them to be exposed to various engines without duplicating them.

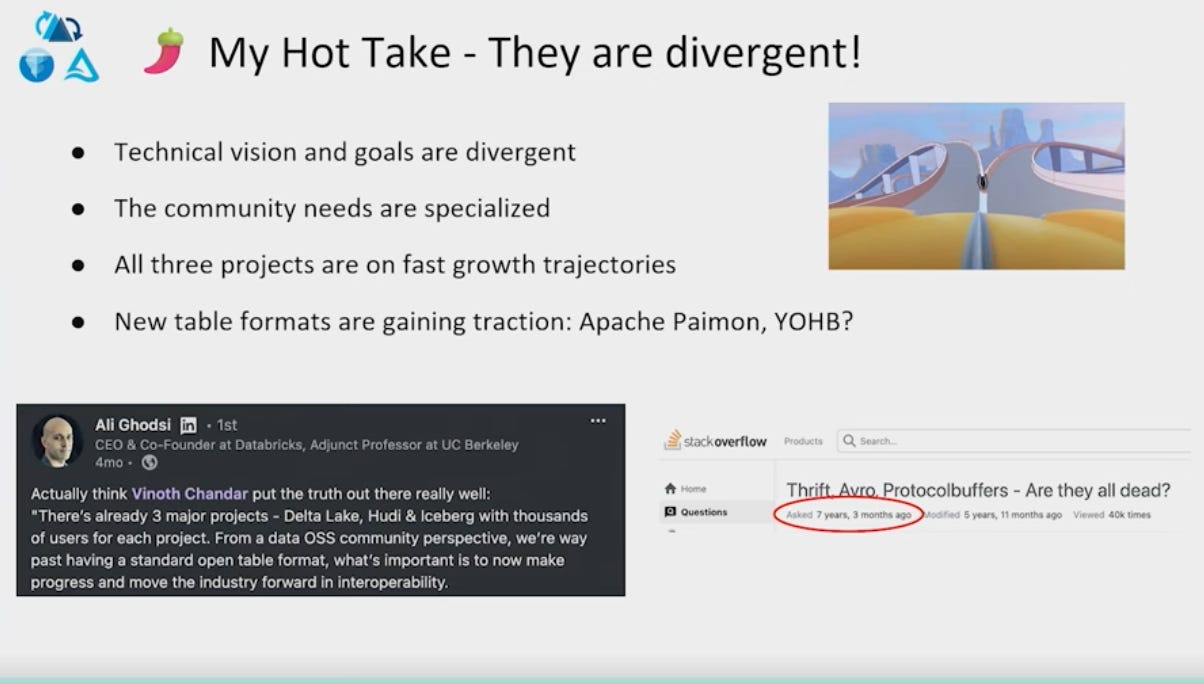
6 - Will open table formats converge or diverge?
Speaker: Kyle Weller, Head of Product, OneHouse (ex- Azure Databricks)
We've discussed interoperability, and naturally, the conversation shifts to open table formats: Iceberg, Delta, and Hudi.
I've always been curious about the differences between them.
Kile explains why these 3 leading open table formats have divergent foundations and won't converge.
For these reasons, an additional layer may be needed to combine them together, which is the rationale behind Onehouse.
7 - How to build a new database in 2024?
Speaker: Andrew Lamb, Staff Engineer, InfluxData
The talk is quite technical and explains the design of influxdb a time series database.
I found particularly insightful how people are building new databases in 2024, especially relying on open-source projects like Parquet and Arrow for data formats, and engines like Datafusion for processing.

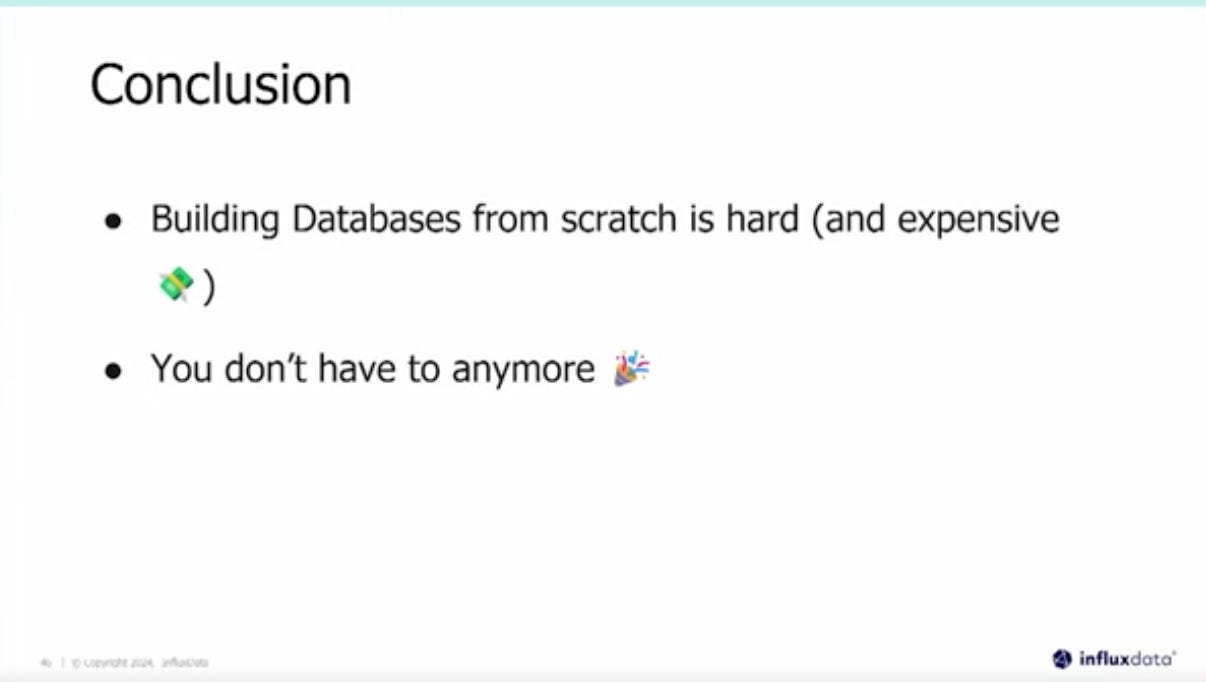
Leveraging these building blocks significantly accelerates the development of data infrastructure tools and is likely to fuel many innovations in the next years.
8 - How to prepare web-crawl data to train an LLM?
Speaker: Jonathan Talmi, Manager of Technical Staff, Cohere
Since the advent of LLM, I've always been curious about the data engineering behind them, especially how the training sets are built.
Jonathan explains why the quality of data has a significant impact on the model's quality and how they filter out low-value content in their data preparation process.
They construct various data quality signals computed in the data pipelines, which are then used to prune the dataset.

9.A/B testing for data professionals
Speaker: Timothy Chan, Head of Data, Statsig (ex- Facebook)
Super interesting session on how to build experimentation.
I think it’s super powerful to have a basic understanding of how to test and prove causality when working with data.
It can help a lot when supporting businesses to run experimentation and validate hypotheses.
This is probably one aspect of the success of Facebook as stated by Zuckerberg:
“There’s no magic in the group we’ve built here that other people can’t replicate. It’s just about being very rigorous with data and investing in data infrastructure so that you can process different experiments and learn from what customer behavior is telling you.”
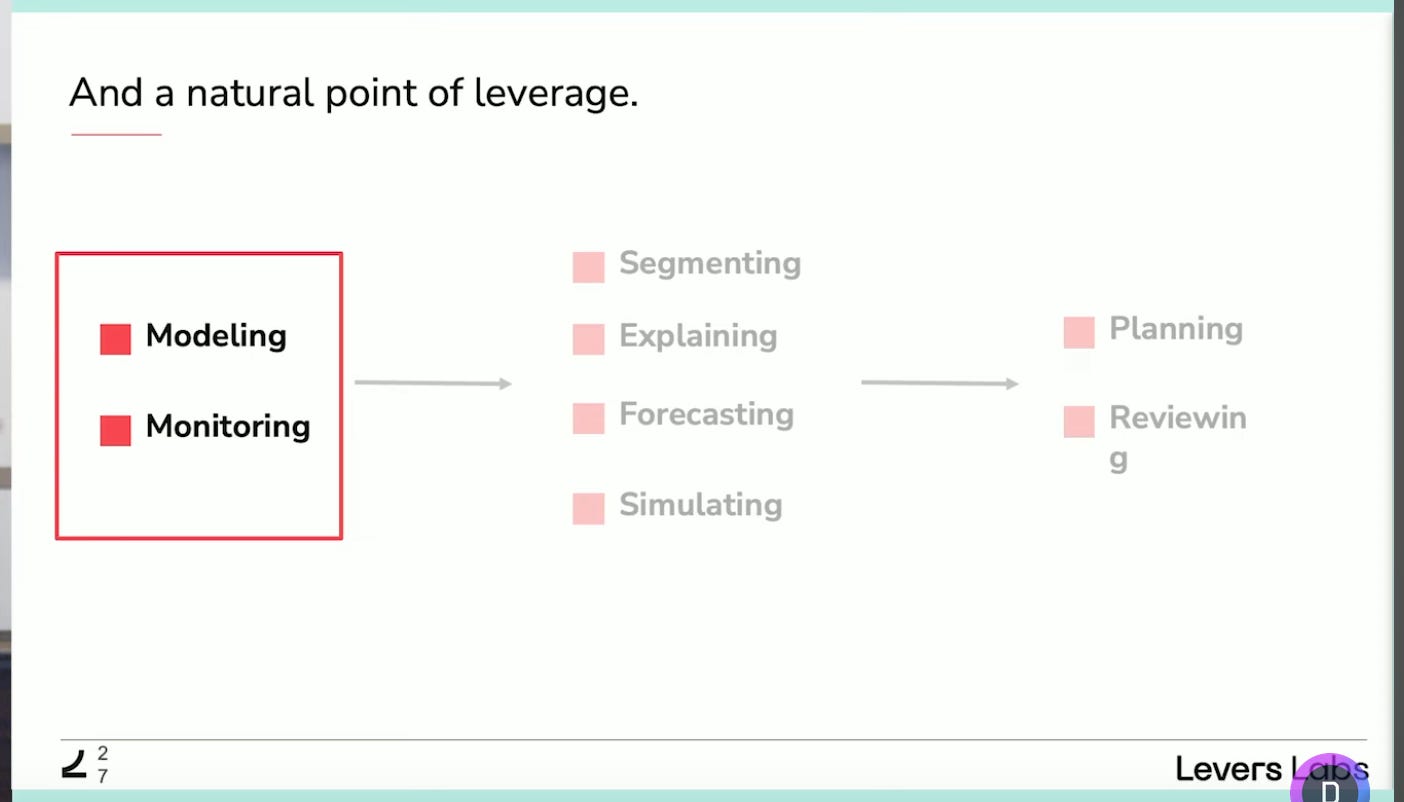
10 - How to prioritize for maximum impact as a data team?
Speaker: Abhi Sivasailam, Founder & CEO, Levers Labs
This talk is less technical but addresses a problem many of us encounter when starting a data initiative in a company: how should we start?
I particularly liked how Abhi mapped the various data jobs that exist, how they are sequenced, and therefore where you should start to gain more leverage.

Data Council is an endless source of powerful insights and ideas !
We're working on something special with Blef on curating that lake of content.
It will be announced in the next few days.
Stay tuned!
Thanks for reading,
-Ju

I would be grateful if you could help me to improve this newsletter. Don’t hesitate to share with me what you liked/disliked and the topic you would like to be tackled.
P.S. You can reply to this email; it will get to me.