
Okta's Multi-Engine Data Stack
Ju Data Engineering Weekly - Ep 59

Datacoucil uploaded talk videos from the 2024 edition last week.
I was really looking forward to one presentation by Jake, an engineer at Okta: “Processing Trillions of Records at Okta with Mini Serverless Databases”
A few months back, he wrote about how using DuckDB helped save a lot of money on their warehouse expenses.

This talk is about how they implemented such a setup.
Let’s have a look !
Slides and video of the talk can be found here.
Okta’s stack
I've written a lot in the previous month about the multi-engine data stack.
I've tried some implementations (v0, v1), conducted cost analyses, and explored Iceberg (Ep 32, Ep 58) as a common storage layer.
One of the first use cases I saw for this kind of setup was to save on Snowflake pipeline costs.
Using Snowflake and its infinite scalability for processing and transforming small datasets does not feel very efficient, especially when the same job could be done on a small VM.
This is exactly the approach taken by Okta.
They initially used Snowflake as their go-to analytics platform, but the costs increased rapidly.
They chose to shift some data pre-processing tasks upstream of the warehouse.
They started with smaller, less frequent workloads that don't need many resources but must scale well as volumes can vary greatly.
This makes them ideal for a Lambda function supercharged by DuckDB, which is resource-limited (maximum 10 GB and 15 minutes runtime) but can scale quickly (up to 1000 concurrent instances).

No exact figures were given on the cost savings, but the Snowflake spending curve is quite explicit.

Last year, I conducted cost comparison tests between Snowflake and DuckDB on 21 different TPC-H benchmark queries :


Half of the queries cost at least 50% less with DuckDB while taking up to three times longer.
If slower processing times are acceptable, you can achieve significant savings.
What's particularly interesting about Okta's setup is the use of Lambda's limitless scalability.
The system adapts to changes in data volume automatically, without needing any adjustments to the infrastructure!
Look at the scale they achieved:
1 million DuckDB invocations per day in average.
Peaks of up to 250GB of data processed per minute !
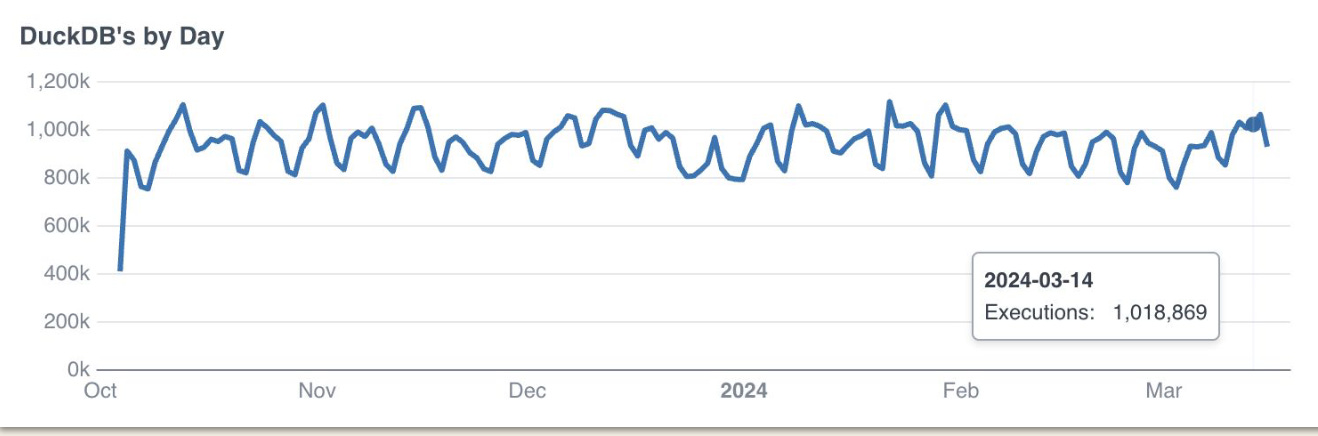
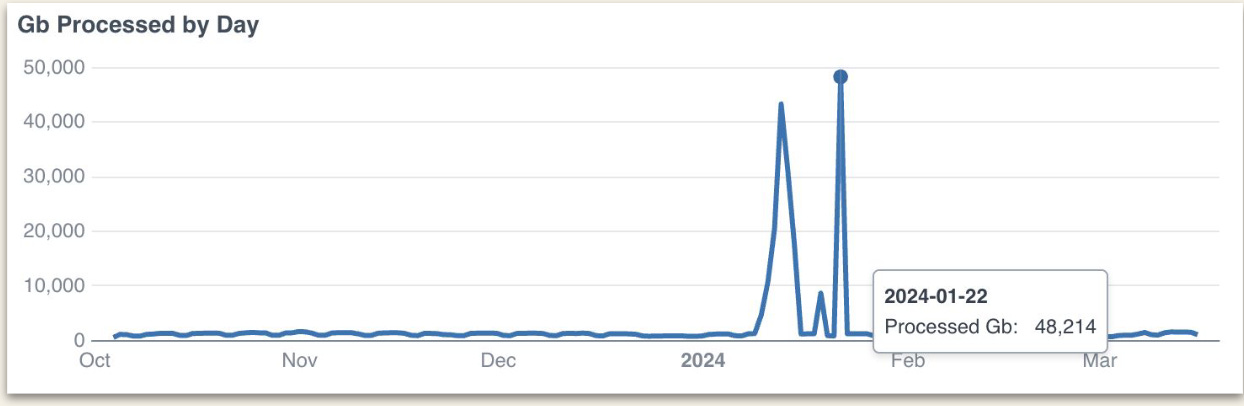
As Jake also noted, this scalability is particularly useful for backfilling.
Simply send the messages for reprocessing to the queues, and the system will scale and take care of the rest; no infra pre-provisioning.
AWS Pre-processing Insights
SQL computations
The ability to manipulate data with SQL capabilities in a Lambda via DuckDB greatly simplifies data manipulation (goodbye Pandas 🎊).
Okta simply mapped each dataset (S3 prefix?) with an SQL query, which is run directly by duckdb inside the lambda.
Most of their SQL operations are pretty standard: normalization, count(), md5(), deduplication, pivoting:

(with a bonus for the hashing of the column names to quickly spot schema changes)
Snowflake ingestion
Another interesting aspect is their usage of Lambda to load data into Snowflake. This Lambda is probably running a COPY INTO statement for each file.
This is interesting because Snowflake has a managed service called Snowpipe for automatic ingestion from S3.
I'm curious about this choice, but from my experience, using Snowpipe for auto-ingestion while normalizing data in AWS can add some complexity.
If for example an input file is normalized and split into various files, each file will be ingested independently into Snowflake.
This means the ingestion process could break the parent-child relationship, possibly leading to incomplete data materialization in the warehouse between two DAG runs.
Using Lambda to control which file is ingested can simplify this process, provided that a state of the transformation is maintained somewhere in AWS.
Limitations
It's interesting to see feedback on using Lambda as a serverless data transformation engine converging.
Bauplan wrote an interesting paper on this topic a couple of months ago:
“ It is clear than Lambda is not suited for this task
[…] resource allocation is done at deployment time, not invocation time;
[…] data passing require manual copies to durable storage”
Lambda Resource Allocation
Setting up Lambda is challenging because you have to set a fixed memory amount at creation, but the memory needs can change depending on the incoming data.
The challenge is therefore to avoid allocating too much memory while still handling various file sizes.

Various approaches are possible:
Deploy multiple Lambdas with different memory configurations and route each event to the appropriate Lambda based on the file size.
Deploy multiple Lambdas with different memory configurations and start processing with the smallest Lambda. If an OOM occurs, automatically redrive the events from the DLQ to the next biggest Lambda.
Implement a mechanism to automatically scale the Lambda up when an OOM occurs, redrive the DLQ, and scale the Lambda back down once processing is complete.
All these solutions work but feel somehow a bit hacky.
Hybrid Storage & Data Passing
Bauplan and Jake both mention the need for a storage layer between Lambda and S3.
Bauplan for data passing
In scenarios where multiple Lambdas are used sequentially on a dataset, it's best to avoid network transfers to and from S3, and instead pass data directly between VMs for efficiency.

Jake for low latency data access
An additional caching layer may be necessary to serve embedded analytics globally with sufficiently low latency.

Despite these limitations, combining DuckDB with managed AWS services seems to be a super effective solution for reducing the credit consumption of a warehouse.
The savings can be so substantial that it's an excellent initial step to gain buy-in for starting to build multi-engine data stacks.
Thanks, Jake, for the insightful presentation.
It's great to see real-life implementations of a multi-engine stack with the successes mentioned above.
Thanks for reading,
-Ju

I would be grateful if you could help me to improve this newsletter. Don’t hesitate to share with me what you liked/disliked and the topic you would like to be tackled.
P.S. You can reply to this email; it will get to me.
Great post! I love the idea behind DuckDB + Lambda but also want to see if anyone has used it for more complex cases. I'm thinking more about joins of high cardinality datasets and whether you can orchestrate that somehow. If you know the join key and the cardinality of the data you can do a sort of split at the high level (split dataset using something like "JOIN_ID % 10") and then kick off a variety of parallel tasks.
Excellent post as always. Do you think it'll evolve into the multi-engine stack v1 or similar?