
Using Snowflake as a supercharged Lambda
Ju Data Engineering Weekly - Ep 58

I got triggered by Randy's post last week about adding Lambda-like functionalities in Snowflake via Snowpark.
I had never connected the dots before, but I find this analogy very powerful.
Randy's vision is to include Lambda-like functionalities inside Snowflake.
But what if we take it one step further?
What if we used Snowflake as a lambda-like serverless service gravitating around a data lake?
It's quite a shift from the usual lake+warehouse setup.
Let's explore it in this post!

Lake+Warehouse Infra
Most current data platforms are divided into two systems: a data lake and a data warehouse.

Initially, data is loaded into data lakes, where it often requires some preprocessing:
Converting data to a tabular format (e.g., Excel to Parquet).
Normalizing nested JSON files.
Validating data to ensure it's in the correct format.
Following the preprocessing in the data lake, an ETL loads the data into the warehouse.
In the warehouse, datasets undergo cleaning and merging before being distributed to downstream BI dashboards.
However, this design has two major limitations.
Lake → Warehouse ETL
Duplicating data in two systems causes several problems:
Cost
Storage costs are doubled due to data duplication, and ETL also incurs additional costs (Snowpipe pricing).
Delay
Each additional ETL step introduces a delay in the value chain.
Failure
The ETL process can fail, resulting in partial or incomplete data in the warehouse.
Desynchronization
When files are split, such as with JSON normalization, ingesting them separately might break their parent-child relationship.
More on this topic in this Databricks paper.
Data Processing in the Data Lake
One way to process data in the data lake is by leveraging AWS serverless services, such as Lambda or ECS Fargate.
Serverless services are great for developers: provide your code/container, and AWS handles everything else.
No time is spent on infrastructure setup, provisioning, or maintenance.
However, Lambda and Fargate were not designed for data manipulation:
They lack built-in SQL support
Developers need to handle this by embedding an in-memory DB such as DuckDB.
Lambda has hard limits
15-minute runtime and 10GB memory.
ECS Fargate breaks these limits but has a complicated interface making it hard to use.
Resource allocation is fixed.
Lambdas often end up duplicated in T-shirt-sized (X, L, XL) with various memory configurations to process datasets of different sizes.
More on this topic in this article.
What has changed?
Two recent innovations in the ecosystem are crucial for addressing these limitations.
Snowpark
Snowpark CLI makes the deployment of Python code in Snowflake super easy via stored procedures and functions.
Similar to developing a Lambda function, you define a Python handler:

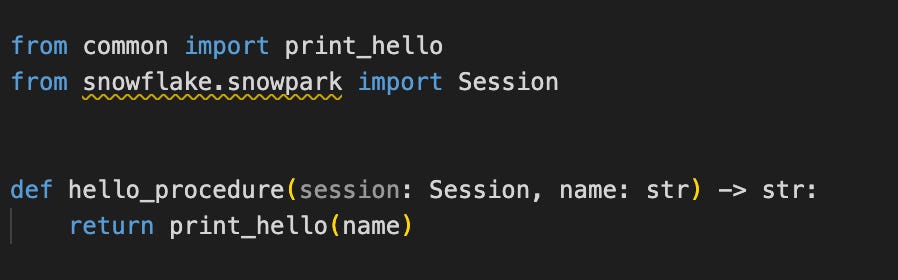
Which is referenced in the snowflake.yml file as the entry point for the store procedure:

And that can be deployed by the CLI in 2 commands:
snow snowpark build
snow snowpark deploy You can then trigger this store procedure either via the CLI:
snow snowpark execute procedure 'hello_procedure()'Or via SQL in the console:
CALL hello_procedure();Since a few months ago, these stored procedures can now connect to the internet.
This enables many use cases such as retrieving data from APIs or querying other AWS services.
Snowflake Iceberg Tables
Iceberg is pushing toward a new paradigm where data is stored as tables in the data lake, accessible for reading and writing from external engines.
Snowflake recently released Iceberg support, enabling it to:
read from an external Iceberg table without needing to copy the data
write directly to a data lake in the Iceberg format.
If you want to learn more, take a look at this example in a previous post:

Snowflake as a lambda
With Iceberg, companies now have two options:
Leverage it to easily centralize everything in Snowflake.
Leverage it to centralize everything in the data lake and only employ Snowflake when necessary.
Choosing one option likely depends on a company's sensitivity to vendor lock-in.
Since Iceberg makes data accessible to any other engine, why lock myself in and keep data in Snowflake?
Why not treat Snowflake as a stateless engine—taking Iceberg tables as input, performing transformations, and then writing its output back to the lake?
Viewing Snowflake as a supercharged Lambda resolves many of the limitations we listed above:
It supports SQL and Python.
No resource constraints or timeout limits.
It can leverage internal Snowflake tables as a cache to reduce read/write operations to the lake.
It scales to zero and is (almost) billed on usage: Each invocation starts a warehouse, which remains active for at least 60 seconds.
It can be triggered via events using Snowflake streams.
It can be scheduled via cron using Snowflake tasks.
In this setup, a pipeline would consist of a series of Snowflake transformations, materializing Iceberg tables.
Each transformation could be either Python or SQL-based, leveraging data from the marketplace or Snowflake's ML capabilities.

To be honest, the ecosystem is still very young, and I'm not sure about the feasibility of such an idea.
I mostly followed my intuition in writing this blog post.
However, the promises of interoperability will certainly shift the center of gravity of the stack upstream towards the data lake.
Will it be enough to consider cloud warehouses as interoperable Lambda functions?
I'm not sure, but I like the idea.
Thanks for reading,
-Ju

I would be grateful if you could help me to improve this newsletter. Don’t hesitate to share with me what you liked/disliked and the topic you would like to be tackled.
P.S. You can reply to this email; it will get to me.