
Multi-engine data stack v1
Ju Data Engineering Weekly - Ep 56

I built the v0 of a "multi-engine data stack" last November.

At that time, I combined Snowflake with DuckDB, using a common data layer consisting of Parquet files in S3.
In the meantime, PyIceberg has released the capability to write to Iceberg from Python.
This post presents the ideal opportunity to update my previous stack by integrating Iceberg as a storage layer.

Multi-engine Stack
Here's the setup I built for this article:
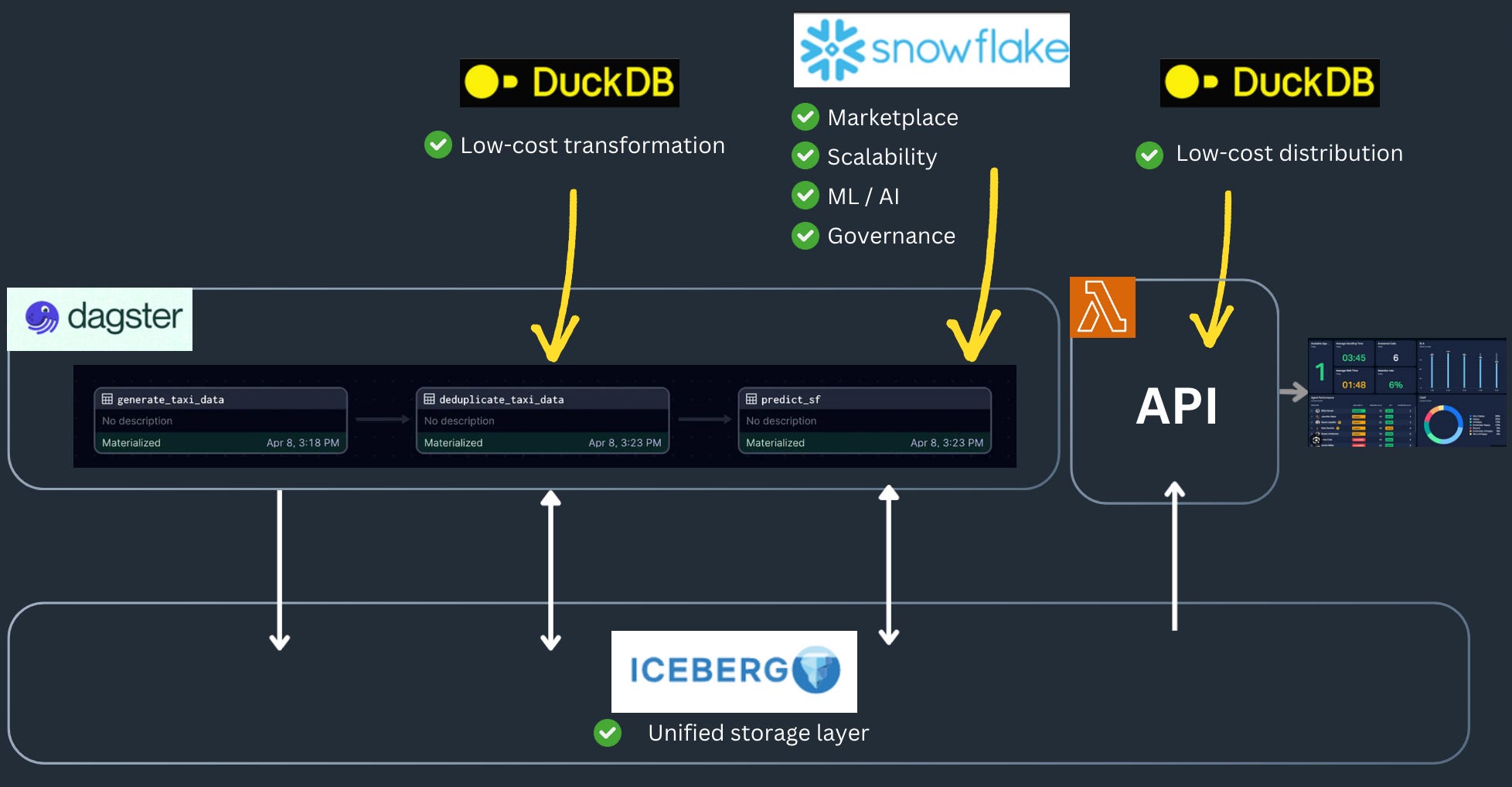
The idea is to explore how Apache Iceberg can be integrated with various engines and serve as a unified storage layer across the stack.
In this example, I wanted to mix Snowflake and DuckDB because they complement each other well:
DuckDB: lightweight, cost-effective, but lacks governance
Snowflake: marketplace, scalability, AI/ML, corporate-grade governance but expensive
Combining them in a single stack opens up several possibilities:
Reduce Snowflake costs by offloading some transformation workflows to DuckDB.
Reduce data distribution costs by exposing tables via an API embedding DuckDB in a Lambda function.
Reduce ELT costs by integrating datasets via the Snowflake Marketplace.
Leverage Snowflake features around ML (Snowflake forecast) and AI (Snowflake Cortex).
Apache Iceberg
Iceberg is an abstraction layer on data files stored in a data lake.
It defines a standard method for storing statistics about these files.
Engines then use these statistics to access data efficiently.
File Structure
Iceberg tables are stored in separate S3 paths.

For each table, two sub-folders are created: "data/" containing data Parquet files, and "metadata/".
Metadata consists of two types of files:

Catalog
Catalogs are not necessary to read tables; all the information needed is contained in the latest version of the metadata.json file.
However, writing inside an Iceberg table requires a catalog to resolve concurrent operations.
Several catalogs exist: Glue, DynamoDB, JDBC, Nessie, Snowflake, and REST (more details here).

If you want to dig deeper into how Iceberg write/read operations work, you can take a look at this article:

PyIceberg
PyIceberg is a Python implementation for accessing Iceberg tables.
It offers a simple Python API for creating, reading, and writing tables.

Snowflake
Snowflake recently introduced Iceberg tables.
I spoke with the Snowflake CTOs last year, and their goal with Iceberg is to onboard customers with large Iceberg datasets (>PB) without needing to copy data.
Snowflake Iceberg tables are stored inside your own bucket (external volume) and come in two forms:
Managed by the internal Snowflake catalog.
Write access: Snowflake ✅ - Other engines ⛔️
Read access: Snowflake ✅- Other engines ✅
Managed by an external catalog (e.g. Glue).
Write access: Snowflake ⛔️ - Other engines ✅
Read access: Snowflake ✅ - Other engines ✅
Data Pipeline
For this PoC, I implemented a straightforward pipeline in Dagster:

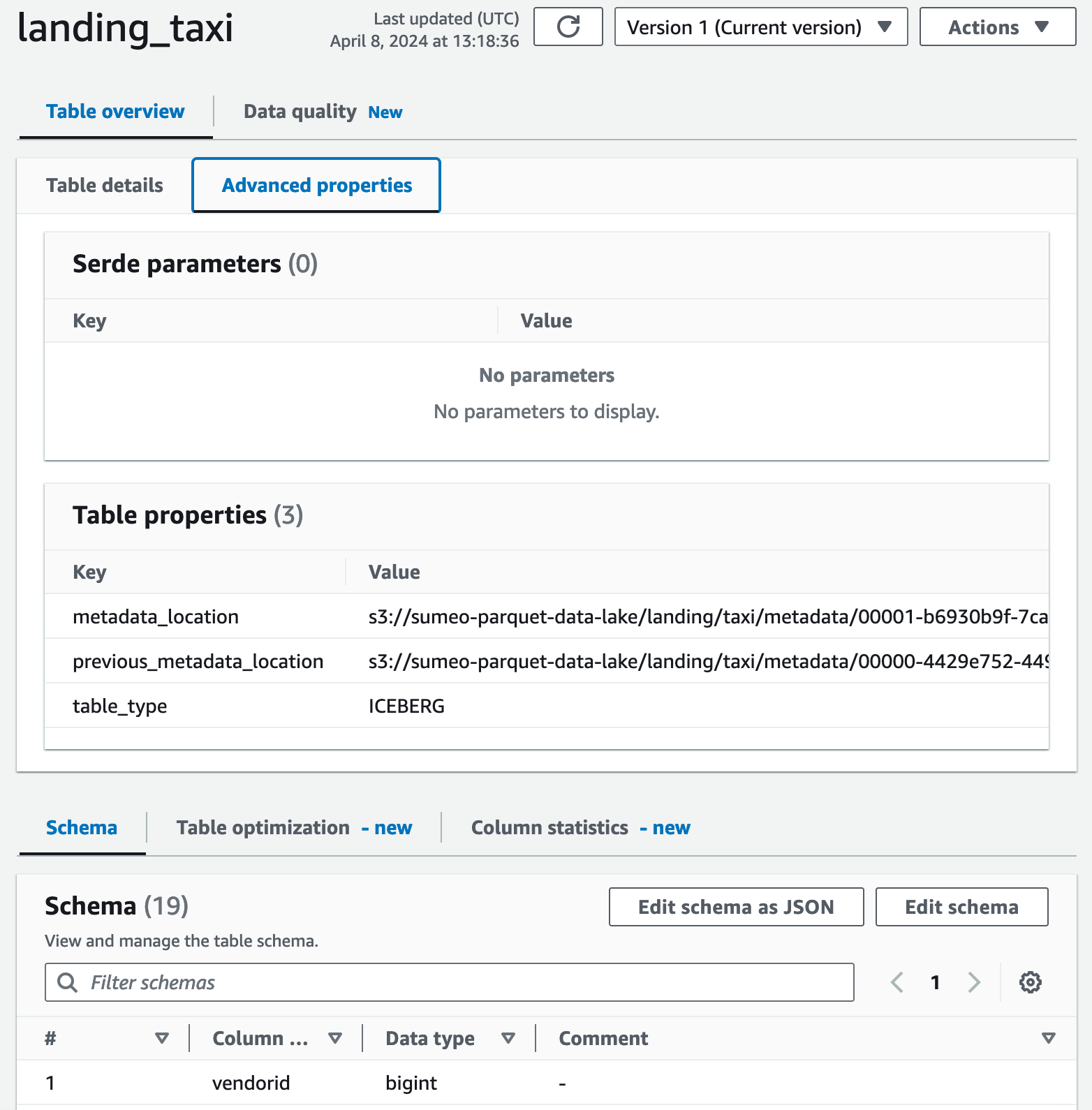
The first model writes raw data to an Iceberg landing table.
I created this Iceberg tables using PyIceberg and a Glue catalog.
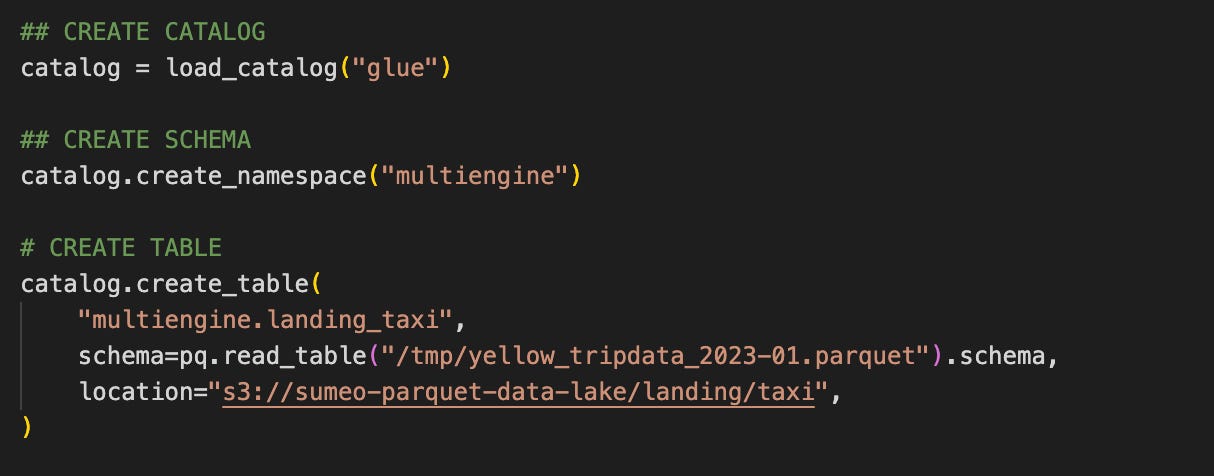
The Dagster asset then writes batches of 1000 rows to the Iceberg table.

Note that PyIceberg offers two writing modes: append and overwrite. However, upserts are not yet supported.
A second model deduplicates the landing table records using DuckDB.
The purpose of this model was to demonstrate how DuckDB can read from and write to Iceberg, showcasing its integration within the pipeline.

What's great is that the two tables we've created can be listed and queried directly within Snowflake without moving the data.
I just created two Snowflake Iceberg tables pointing to the Glue catalog I used for the write operations.

And I was able to view/query the 2 tables created previously in my Snowflake account.

Magic!
Since the table is managed by an external catalog, after an update, Snowflake does not point to the correct version of the data but to the previous snapshot.
For that reason, I needed to execute ALTER ICEBERG TABLE REFRESH in the Dagster asset to ensure that Snowflake points to the latest snapshot.
This could be easily automated via Snowflake S3 event notifications and Snowflake tasks, as described here.
A third model in Snowflake generates a prediction (dummy here but serves as a placeholder for ML/AI SQL functions) and stores the result in a new Iceberg table.
The code for this model is pretty straightforward as it simply creates a new Iceberg table on top of the staging one with "Snowflake” as a catalog.
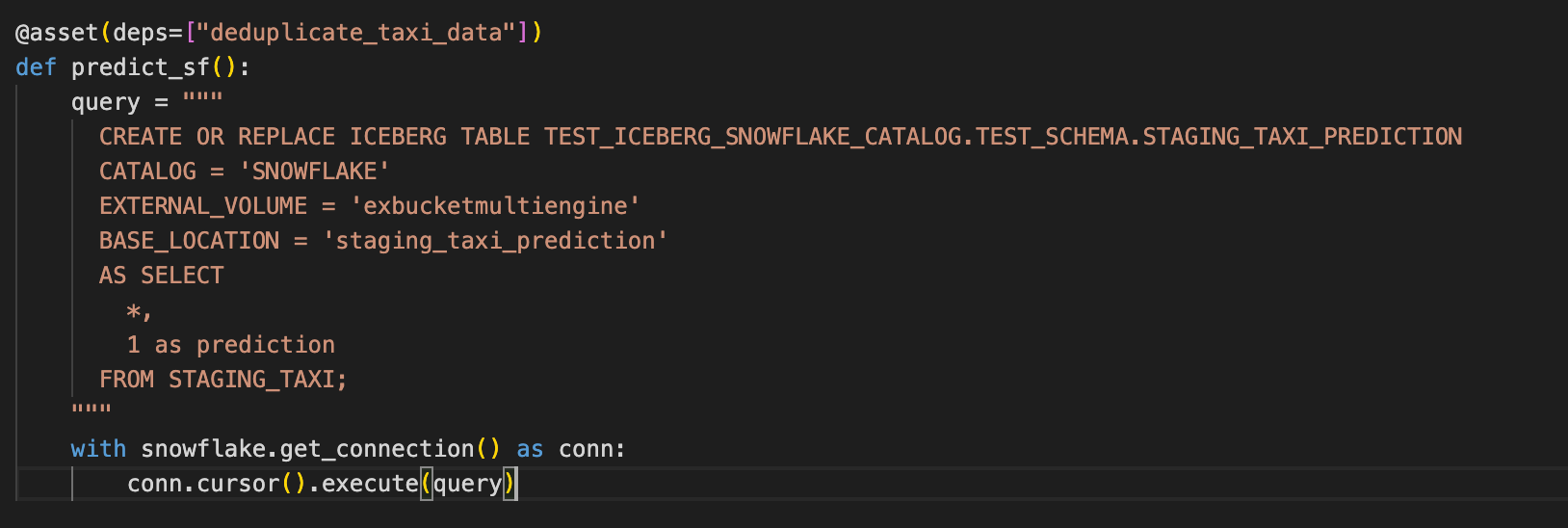
Having a look at the S3 bucket, we can find the corresponding files:

This created table can now be read by any other engine, such as DuckDB.

This DuckDB SQL query can then be embedded, for example, in a Lambda function and accessed via an API, allowing consumers to access the Iceberg table at a low cost.

Limitations
One important missing block of this stack is dbt.
Currently, dbt does not support Snowflake Iceberg Table as a model type.
For this reason, I decided to implement directly Dagster assets instead.
Additionally, scalability might be a problem if you run this setup in production.
I have no idea how well PyIceberg can read/write large data but I will test it in a future post!
Iceberg is still in its early stages, but enabling interoperability among different engines opens up so many possibilities:

If you want to get more details on this setup and/or get access to the code, don’t hesitate to reach out to me!
Thanks for reading,
-Ju
I would be grateful if you could help me to improve this newsletter. Don’t hesitate to share with me what you liked/disliked and the topic you would like to be tackled.
P.S. You can reply to this email; it will get to me.
Very very excited that you're building content on multi-engine data stacks. Keep it up! Gets me 🧃 up
Is this still possible now that Snowflake discontinued version-hint.txt?