
Multi-engine data stack - v0 🚀
Ju Data Engineering Weekly - Ep 38

Over the past few weeks, I've been exploring several aspects of a rising concept in the data engineering world: the multi-engine data stack.
A quick recap of my recent articles:
The future of data stacks

Takeaway:
Teams are increasingly interested in combining different engines (Snowflake, Spark, DuckDB, BigQuery) to reduce cost, limit vendor lock-in and gain maximum flexibility.
Potential cost savings DuckDB vs Snowflake

Takeaway:
For 50% of the TPC-H benchmark queries, Duckdb achieves >50% cost reduction with a maximum 3x longer compute time (4$ SF credit price).
Development of a cross-engine query layer

Takeaway:
This field is expanding rapidly. It’s becoming easier for data teams to transpile their SQL or Dataframe code from one engine to another.
Dagster + DBT integration

Takeaway:
Dagster is well-suited to coordinate different engines in DBT as it makes possible to specify run configurations for each model.
Status of Apache Iceberg

Takeaway:
Once integrations with different engines are ready, teams will be able to use Iceberg as a unified storage layer across their entire stack.
After several weeks of exploration, I felt it was time to build a small Proof of Concept (PoC) using existing tools in the ecosystem.
I want to understand how easy it would be to mix different engines in one stack while meeting the following requirements:
Having only one interface to the code: DBT.
Having only one DAG orchestrating the materializations.
Combining 2 engines: Snowflake and DuckDB.
You can find the source code of this PoC here
Here is the stack that I have built:

File storage
Instead of using Apache Iceberg, whose integration in the ecosystem is not mature yet, I opted for Parquet.
Files are stored in S3 and accessed by both DuckDB and Snowflake.
Orchestrator
For this project, I used Dagster: it provides an excellent abstraction that simplifies the orchestration of different engines (→ profiles) inside a DBT project.
Engines
I wanted to combine two engines: DuckDB and Snowflake.
I picked DuckDB because of its growing significance in the analytics space, particularly for small to medium workloads that can run on a single node.
On the other hand, I chose Snowflake to represent the large cloud warehouse vendors.
This PoC could have been implemented with other providers such as Databricks or BigQuery as well.
Data Pipeline
I've implemented a very simple pipeline that takes raw data (orders, in this case) as input and produces a basic aggregation per month in a staging table.
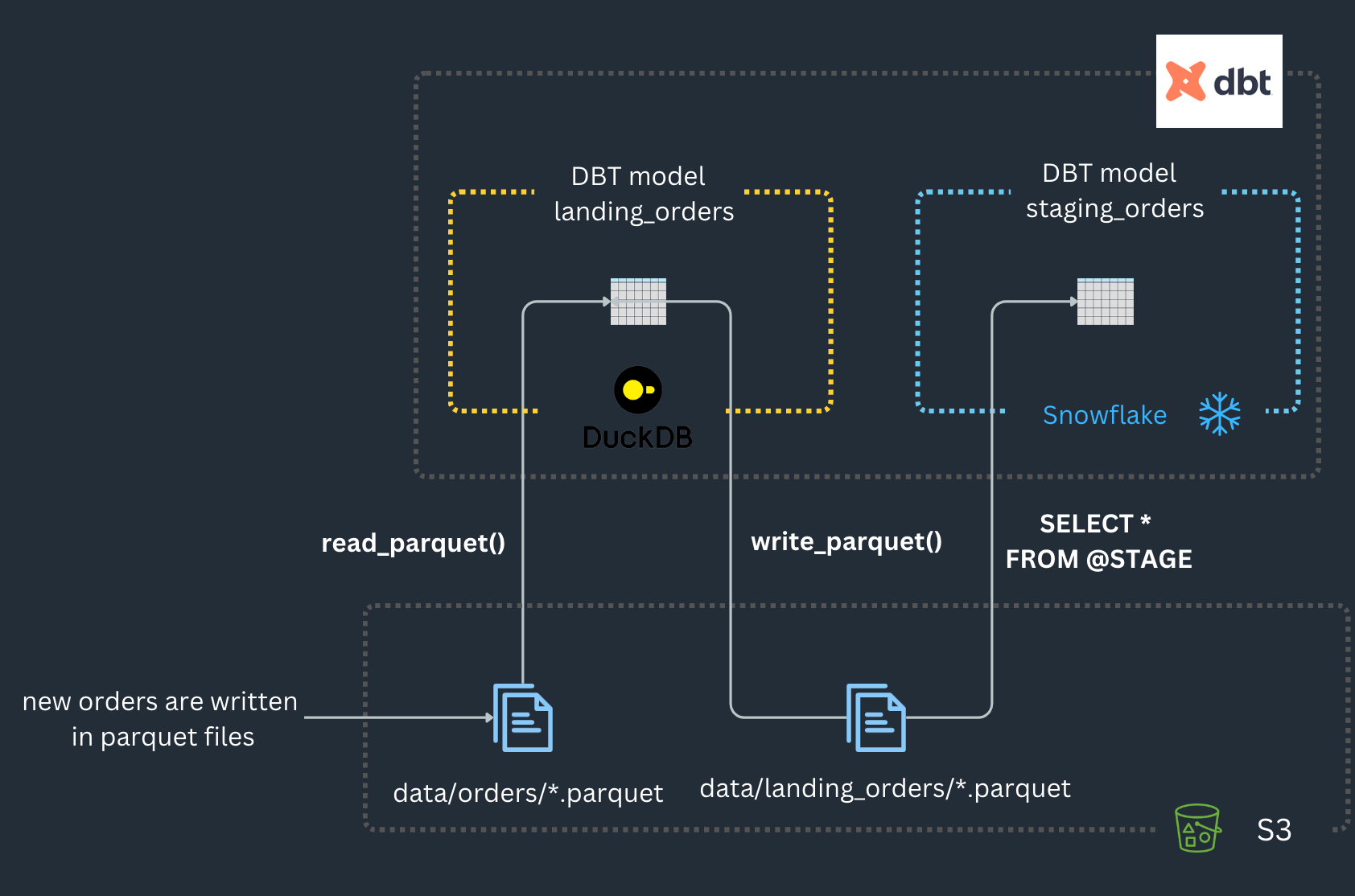
Workflow is quite simple (ELT pattern):
1- New data (orders) are written every 2 minutes to Parquet files inside an S3 bucket.
2- DBT model "landing_orders" loads all parquet files and deduplicate the records. This model is computed by DuckDB.
3-DBT model “staging_orders” aggregates the number of orders per month. This model is computed in Snowflake
Engine selection in DBT
I wanted the engine selection to be transparent to the user: therefore all DBT models live in the same project:
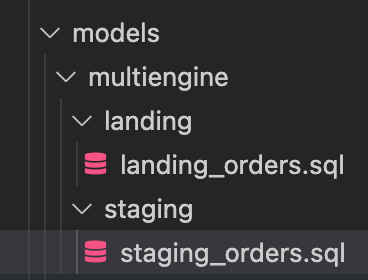
They are simply tagged according to their underlying engine:
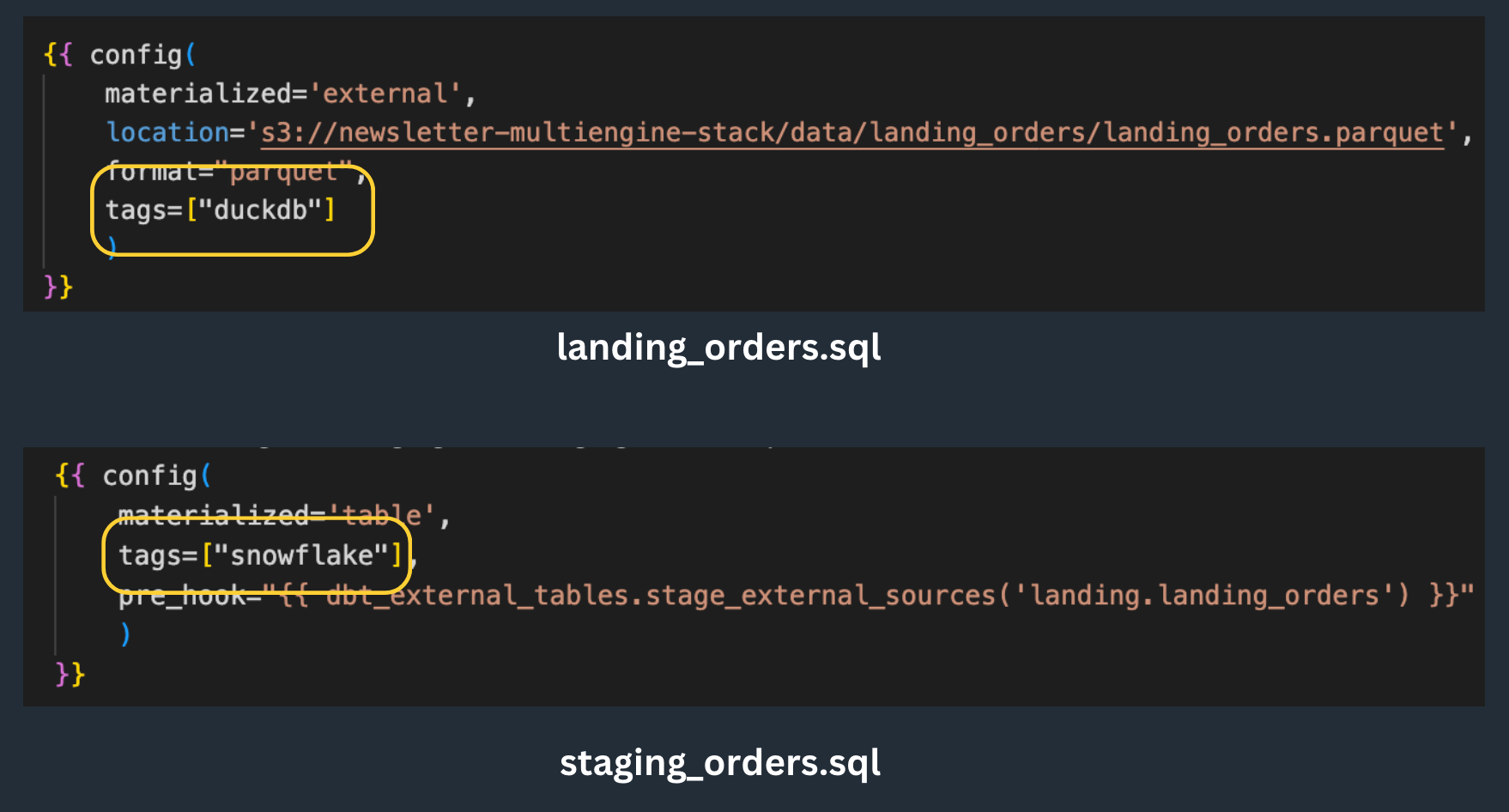
which have a separate profile in profiles.yml:

That way each of the models can be run by DBT using the following selector:
dbt run —profile engine_name —select tag:engine_name
I/O for each engine
DuckDB
I used the dbt-duckdb package to read/write data to S3 with DuckDB.
All I had to do was to:
define a source pointing to the S3 folder containing the data
set the "location" field in the model configuration to specify where DuckDB should save the data

Snowflake
I used the dbt-package external table to load data from S3 to a Snowflake table.
This package consists of a set of macros that automatically create and refresh external tables.
I needed therefore to:
create an external stage pointing to the s3 bucket
create a source pointing to the s3 folder where
landing_ordersmodel is savedadd a pre-hook in the
staging_ordersto refresh the external table automatically at each run

Note: In my simple use case, Snowflake is not writing back to Parquet.
This would have been possible with a post-hook operation and the following Snowflake query:
COPY INTO @stage/output_folder
FROM (SELECT * FROM ...) file_format = (type = 'parquet');Orchestration in Dagster
What's great about Dagster is the ability to specify the execution context for each of the models.
I created two groups of assets and specified the DBT profile to be used for each of them:

and I can then visualize my pipeline in one DAG.
Nice !!
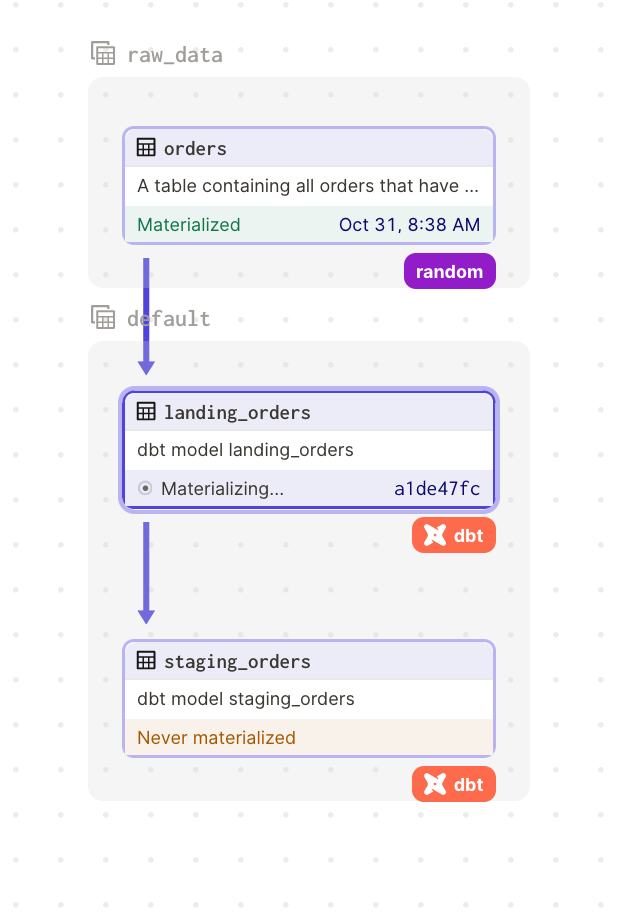
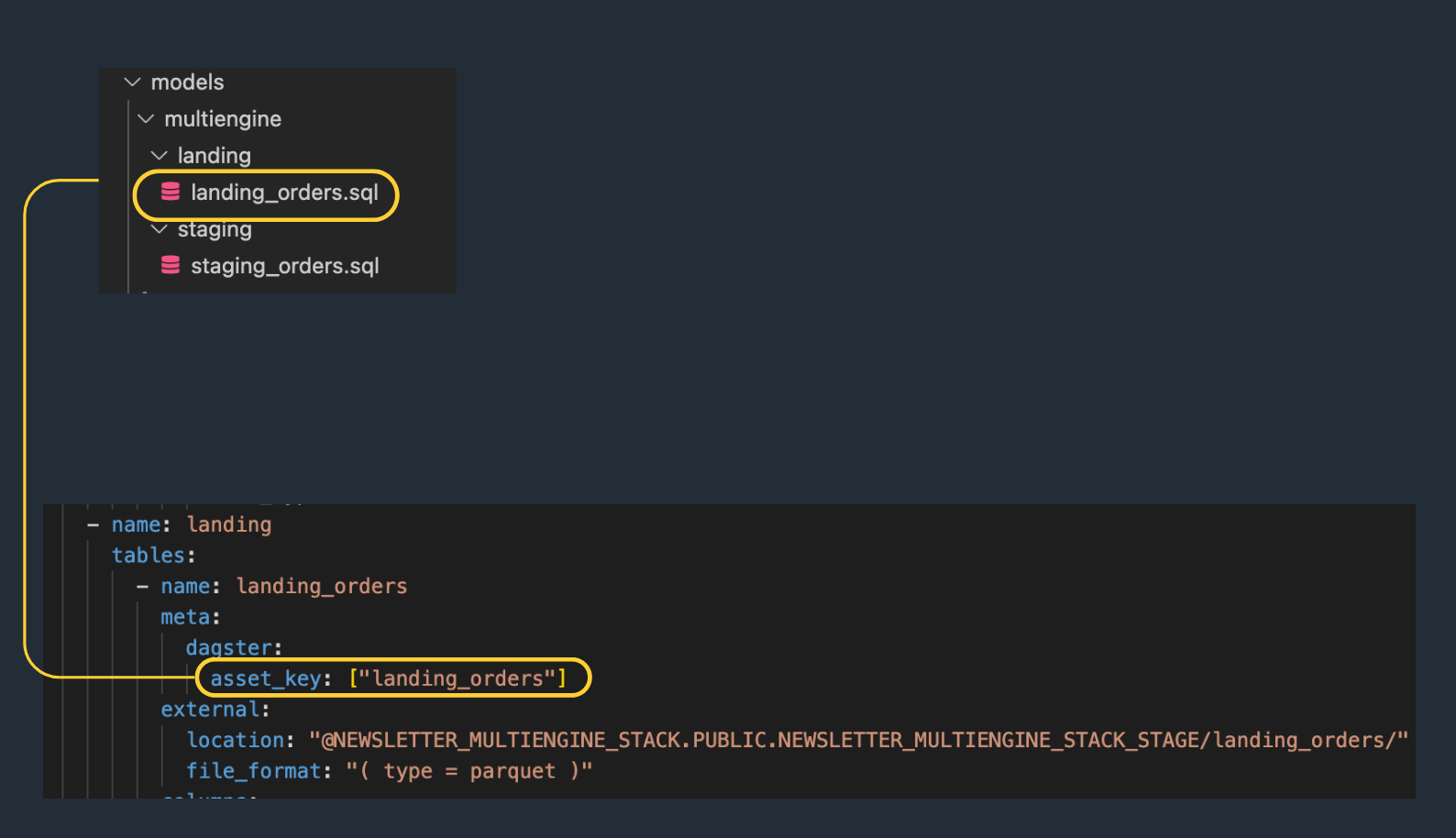
What's great with Dagster is the possibility of controlling up/downstream dependencies.
In DBT, the lineage is broken because the staging_orders model does not reference ({{ ref() }}) the landing_orders model explicitely.
However, in Dagster, you can specify an upstream dependency manually in the meta properties of a model:
And finally, we can query the staging model in Snowflake directly:

Mission accomplished.
Wrap-up
It’s interesting to see how far we can go with existing tools of the modern data stack.
However, it still requires a lot of tweaking that takes a lot of time to set up:
external source listing
pointing to the correct S3 path
lineage fixing through the orchestrator
etc.
All these operations need to be manually done and would require important investment for a real-world use case.
On top of it, in the current setup, I simply run Dagster and Duckdb locally. In a production environment, Dagster would be deployed in a separate environment, and DuckDB would run in a serverless container like AWS Fargate. And this would need additional setup.
Multi-engine stacks have a huge potential especially now that companies are trying to reduce their cost.
However, a new set of tools needs to emerge to make the experience smoother for data engineers.
If you are interested in building this kind of PoC for your current stack, don’t hesitate to reach out.
I would be happy to guide you through the process and co-design with you this kind of data stacks on real-world use-cases !
Thanks for reading,
-Ju
I would be grateful if you could help me to improve this newsletter. Don’t hesitate to share with me what you liked/disliked and the topic you would like to be tackled.
P.S. You can reply to this email; it will get to me.