
🦆 vs ❄️ ... 💸 ?
Ju Data Engineering Weekly - Ep 34

In today's post, I wanted to continue with the topic I've had in mind for the past few weeks: how to optimize compute costs in your data warehouse (WH) by using multiple compute engines.
I started 3 weeks ago with the following post, explaining how Iceberg could open the path to a unified storage layer consumed by different compute engines.

These engines could be a combination of commercial WH like Snowflake, Redshift, and BigQuery, as well as open-source lightweight engines like the emerging DuckDB project.
My vision is to build this kind of stack:

Indeed, modern WH management tools make it possible to combine multiple engines while maintaining a unified interface to the data, such as DBT, as mentioned at the end of this post:

In this week's newsletter, I wanted to investigate the potential cost saving of such strategy.
TPC-H Benchmarkt
My starting point is the following benchmark that I discovered through a really good (french-speaking) podcast that I recommend for all data practitioners.
The author ran the 22 queries from the TPCH-100 benchmark (base table of ~ 600 million rows) on various engines. He aggregated the compute times of each of these runs to calculate a performance score:

First, it is interesting to notice these gaps between vendors, with a 3x difference between Snowflake and Bigquery, for example.
Even if Snowflake over-optimized performance for this benchmark, other vendors would be stupid not to do it as well …

However, what has truly surprised me is DuckDB's position: this open-source project has not yet reached version 1.0, but it is surprisingly competitive with other vendors.
My intuition is as follows:
Cloud WH are excellent for:
Data governance: role-based access control (RBAC), row-level security (RLS), and role management.
Handling massive workloads that need to be processed in a short amount of time:
Large materializations.
Backfilling complete historical data.
Data Marketplaces
However, in my opinion, they are over-engineered for small to medium workloads with low time delivery constraints: in such cases, you can afford to sacrifice some speed in favor of cost reduction.
Estimation of potential $ savings
I want to estimate the potential cost saving by running a small experiment derived from this benchmark.
I ran the 22 benchmark queries five times each on:
Snowflake (TPC-H data provided by default in any Snowflake account).
Duck DB on AWS EC2 on-demand instance (r4.2xlarge, 16 vCPU, 61 GiB RAM ), $0.5928/h in eu-west-1
For each of these queries, I added up the 5 compute times and calculated time and cost ratios between SF and DuckDB.
The results are as follows:
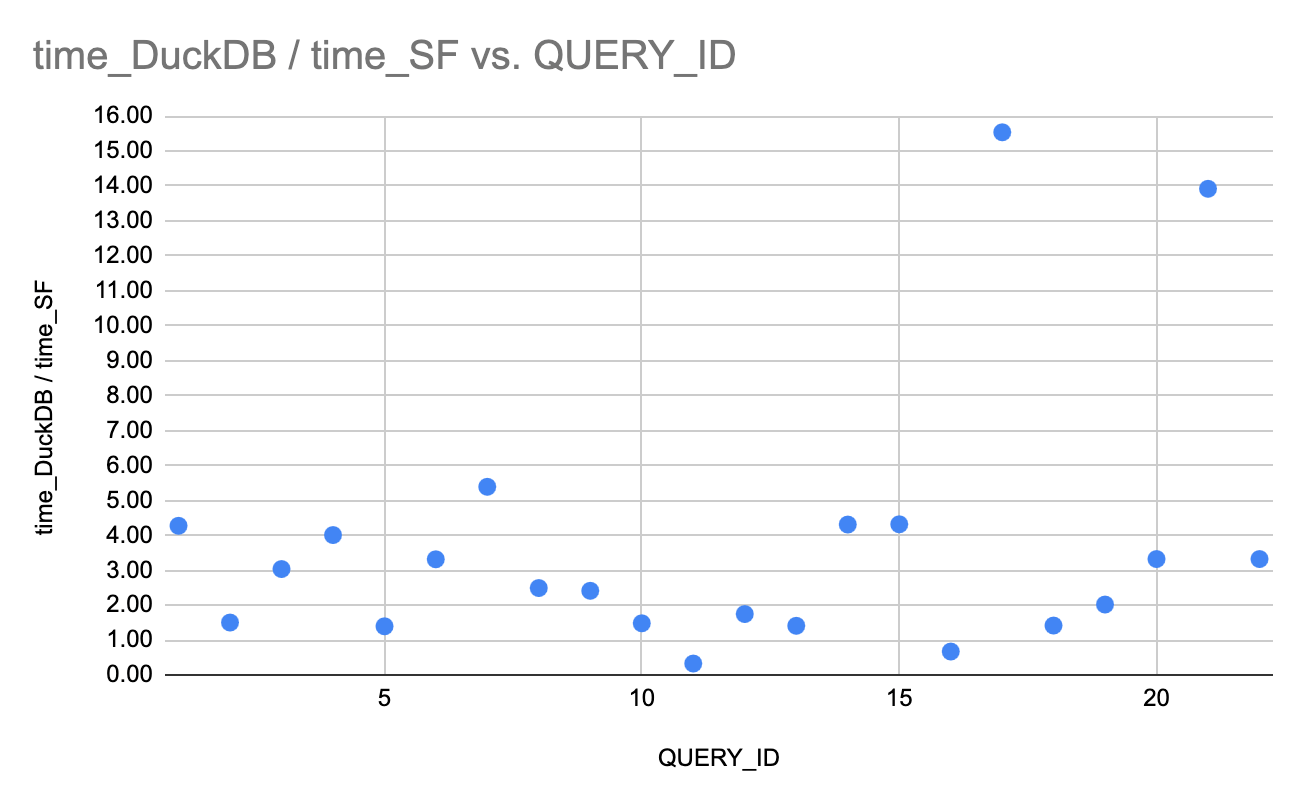
With a 2$ Snowflake credit (Standard edition):
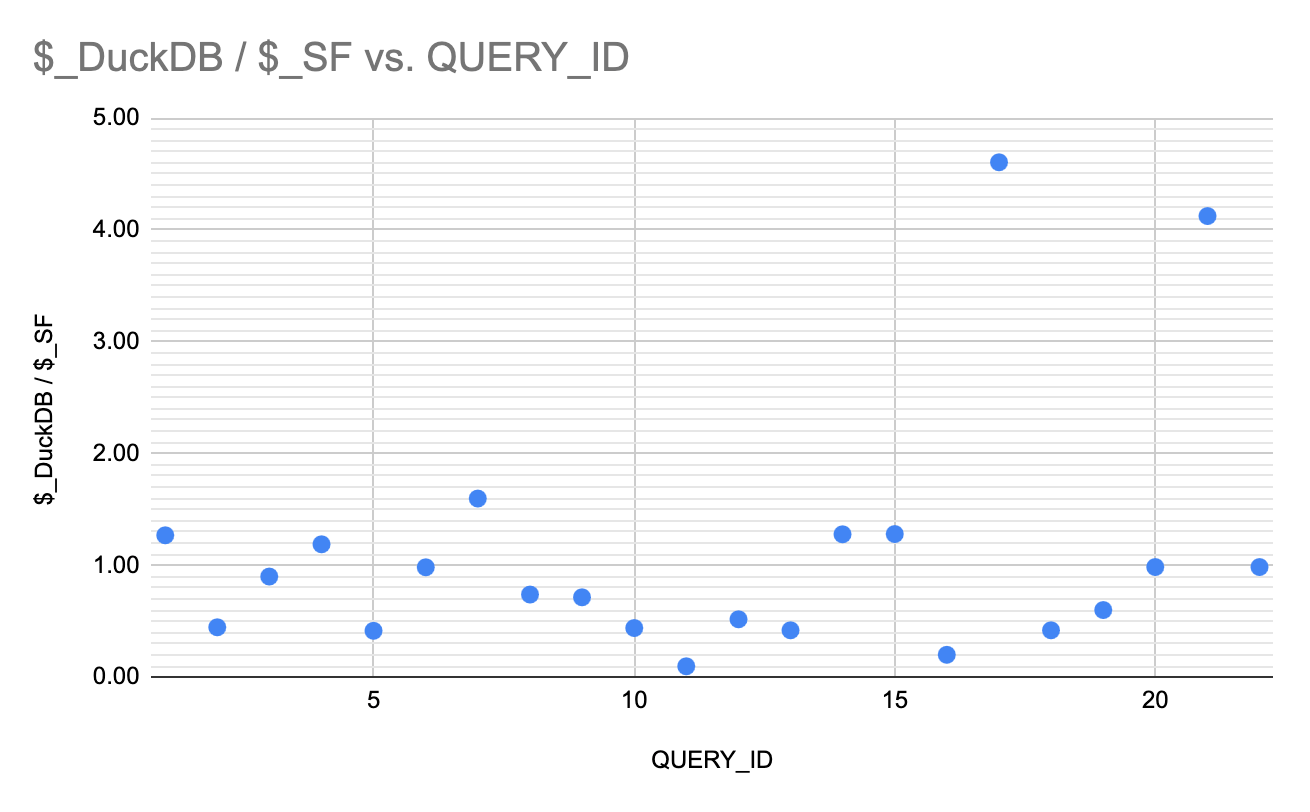
and a 4$ credit price (Business Critical edition):

These numbers should be interpreted with some caution since we haven't factored in:
data loading costs (Snowflake's Iceberg tables are in private preview, and DuckDB's Iceberg integration was just released this week with some limitations)
significant R&D expenses (which would be substantial for this type of stack)
potential business time constraints on certain queries
However, we can get a first estimate of the trade-off between compute time and cost savings:
For how many queries do we have more than 50% cost reduction with max 3* longer compute time ?
With a 2$ Snowflake credit: 30% of queries
With a 4$ Snowflake credit: 50% of queries
This gives an order of magnitude of the impact that a multi-compute engine could have on compute cost in vendor data WH.

The challenge will be to integrate and combine them efficiently...
Thanks for reading,
I would be grateful if you could help me to improve this newsletter. Don’t hesitate to share with me what you liked/disliked and the topic you would like to be tackled.
P.S. you can reply to this email; it will get to me.