
Benchmarking DuckDB in Lambda for data distribution
Ju Data Engineering Weekly - Ep 51

After my posts about building data backends, Dan, the founder of Boiling Data, reached out to me.
We had an interesting conversation about combining DuckDB with Lambda functions.
Dan has built from scratch an analytics engine called Boiling Data on top of AWS Lambda and DuckDB.

He proposed to support one of my posts, which I gladly accepted, as I've been eager to benchmark this combination of DuckDB and Lambda for some time.
Note: While this post is sponsored, there have been no changes to the content or influence on the editorial direction.
Lambda and DuckDB are incredibly complementary in my view: you combine the scalability of Lambda with the speed and flexibility of a portable query engine.
Initially, when I began my explorations, I envisioned combining them to offload some pipeline workloads from the warehouse.

However, after more discussions and reflection, I realized that the other end of the data stack (distribution layer) is a really good fit for this combo.
Indeed, data distribution is becoming increasingly complex.
Teams are aiming to serve more intricate use cases, such as embedded analytics.
Contrary to BI dashboards, where latency and scale are not as critical, you need to be able to handle numerous similar requests from a large number of users with low latency.
We explored this topic with David in a series of posts in December and used Postgres to expose the data.

In this post, I wanted to delve deeper into alternative solutions for this distribution layer.
I took one dataset (TPCH-1), and one query, and compared various engines:
Lambda querying Snowflake
Cube.dev on top of Snowflake
Lambda + DuckDB querying a Parquet file in S3
BoilingData querying a Parquet file in S3
The query is as follows:
SELECT
--Query01
l_returnflag,
l_linestatus,
SUM(l_quantity) AS sum_qty,
SUM(l_extendedprice) AS sum_base_price,
SUM(l_extendedprice * (1 - l_discount)) AS sum_disc_price,
SUM(l_extendedprice * (1 - l_discount) * (1 + l_tax)) AS sum_charge,
AVG(l_quantity) AS avg_qty,
AVG(l_extendedprice) AS avg_price,
AVG(l_discount) AS avg_disc,
COUNT(*) AS count_order
FROM
snowflake_sample_data.tpch_sf1.lineitem
WHERE
l_shipdate <= CAST('1998-09-02' AS date)
GROUP BY
l_returnflag,
l_linestatus
ORDER BY
l_returnflag,
l_linestatus;The lineitem table has 6,001,215 rows.
For each of these setups, which I will detail below, I used Postman to simulate a performance load with 25 virtual users and a ramp-up load for a total of ~1100 calls over 3 minutes:

Setup 1: Lambda querying Snowflake
For this setup, I simply used the Snowflake Python library to query Snowflake directly from a Lambda:
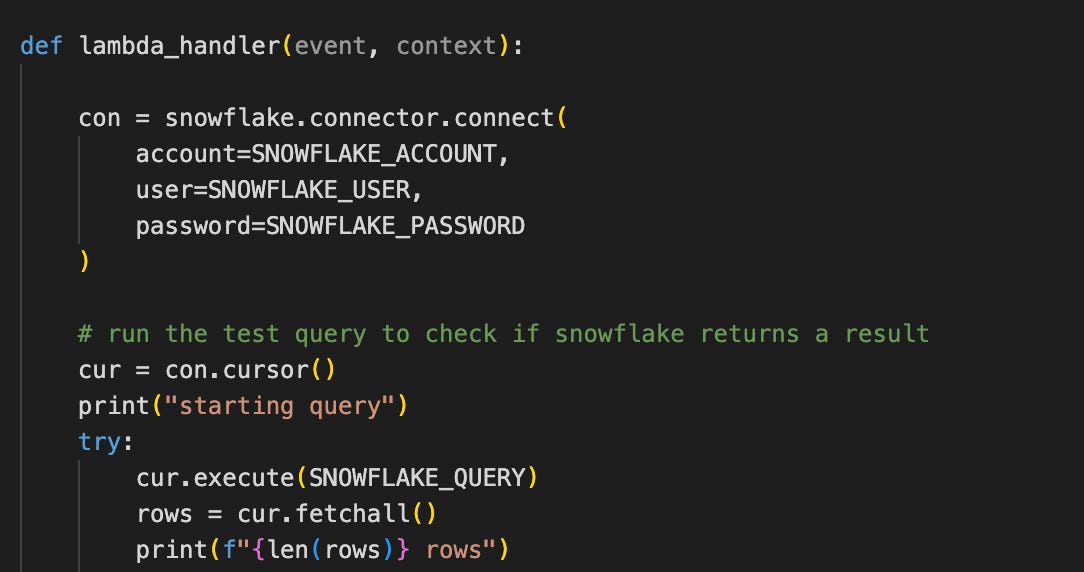
The average response time is 490ms/call and has the following profile:

The higher response time is due to the cold start of the Lambda.
The cost for this setup was:
Lambda: 0.02$ compute
Snowflake: 0.105$ compute (0.021 credits, 5$ per credit)
Total = 0.125$
Setup 2: Cube.dev
SaaS products have been built around this data distribution use case with Cube.dev being one of them.
You can plug Cube on top of Snowflake, and it will serve as a cache layer between your app and the warehouse.

I simply created a view in Snowflake with the query mentioned above and loaded this model into Cube.
During the benchmark, Cube queried Snowflake twice and served the other calls via the cache.
The average response time is 206ms for 1146 queries.

The cost for this setup was 0.001 $ = 4 credit/hour * 0.4$/credit * 1,146 calls * 3ms.
I'm not 100% sure about the total cost of this solution as their pricing model is a bit tricky to understand.
Setup 3: DuckDB + Lambda
For this setup, I simply embedded DuckDB in a Docker container and ran it on Lambda.
I dumped the lineitem table into a Parquet file in S3.
When calling the lambda, DuckDB loads the complete file into memory and executes the query.
No caching system is used.
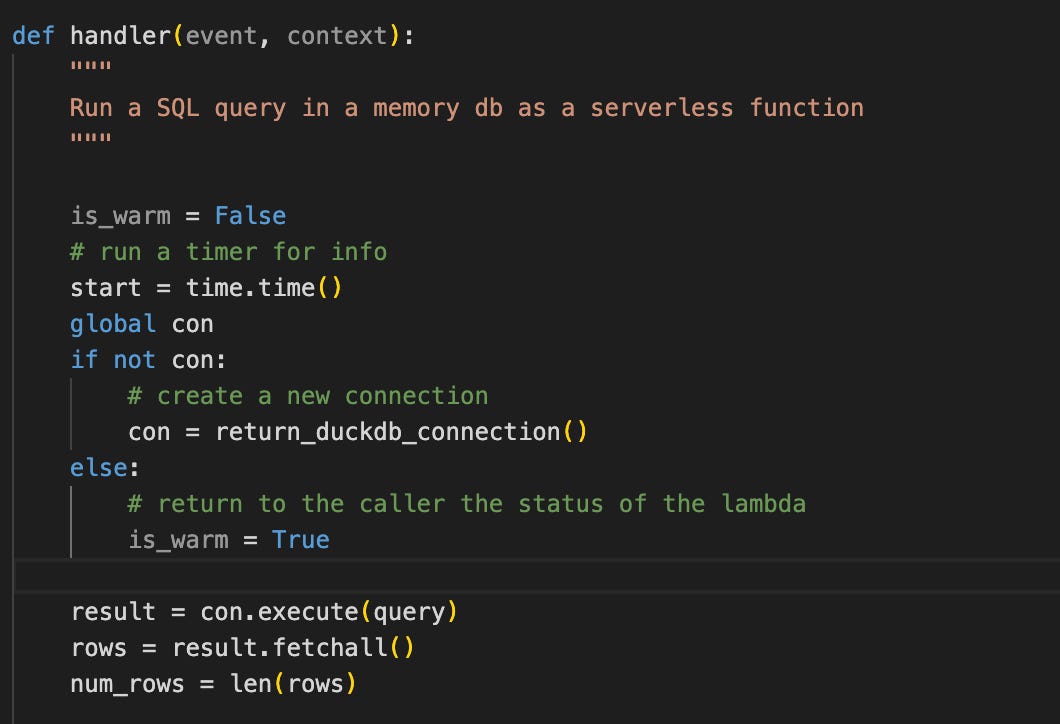
The average response time is 3753 ms.

The total cost for this setup is 0.21$.
Setup 4: BoilingData
Dan's engine is an advanced version of the previous setup:
The queries are first parsed by a lambda and then sent to other lambdas embedding duckDBs to parallelize executions. The first lambda aggregates the results and sends the output.
Queries are cached in memory
The engine was exposed by Dan via an API that I was able to call directly from Postman.
The average response time was 206ms for 1,146 calls.

Boiling pricing is 0.000001$ per ms, and each request requires an average of 80ms, which results in a total cost of 0.09$.
As for the other setups, the first queries are always slower due to the Lambda cold start.
Wrap-up
We have the following response time and cost for the 4 setups.


For this use case where cached data needs to be accessed with low latency, Cube seems to be a very interesting alternative.
Boiling Data has shown interesting results as the caching mechanism worked properly. However, the engine may fully unleash its potential when querying larger volumes of data and with more dynamic queries.
Additionally, the query I used involved a GROUP BY function, which limited the parallelization possible by the Boiling Data query engine.
This is just the first exploration I conducted in this area, which is new to me.
In future steps, I would like to try various queries with dynamic parameters, joins, and other aggregation functions to see how these engines react to more dynamic requests.
Thanks for reading and thanks Dan for the support,
-Ju

I would be grateful if you could help me to improve this newsletter. Don’t hesitate to share with me what you liked/disliked and the topic you would like to be tackled.
P.S. you can reply to this email; it will get to me.
Great benchmark!
Made me think about recent discussions I had with Kestra users which are using Kubernetes + DuckDB (and a bit of Kestra) to manage such problem.
Not the serverless way indeed, but same idea of using DuckDB as the query engine for low latency requests ✅
Hum, the duckdb + lambda benchmark seems to very slow with python. From my (limited) experience using Rust with Duckdb is quite fast and a lot cheaper.