
Moving from BI to Data Apps (Part 2/2)
Ju Data Engineering Weekly - Ep 43


In the last post, we covered the need for a data backend, to serve analytics data externally into data applications.
For this week, we set out to build the simplest possible data backend: sinking the output of a data pipeline (hybrid streaming/batch) to a Postgres application database, to feed a React dashboard.
Julien would play backend developer (aka data engineer), with David as frontend developer.
Problems we were aiming to solve for:
Developer experience: allow data engineers + analysts to work in their native tooling (dbt, dagster, RisingWave for streaming), and application developers to work in their native tooling (Postgres, React).
Cost reduction: both in metrics pre-aggregation (by substituting DuckDB as an analytics query engine for the warehouse) and live querying from the application (by caching metrics in Postgres vs querying directly from the warehouse).
Schema drift, by having end-to-end lineage in dbt (where contracts could be applied to terminal nodes/backend endpoints).
One could call it the “data backend in a box,” following the “MDS in a box” convention started by Jacob Matsen. Let’s dive into what we built, how it went, and where there’s room for improvement.
Note: We know that caching analytics data in Postgres is not a universally applicable solution, but we think it covers a wide range of real-world data application use cases. In future posts, we’ll also cover querying Parquet/Iceberg files in s3 directly (for larger datasets), or using a data backend (as Postgres replacement) suitable for very large datasets (like time-series).
Demo project
To be as meta as possible, we chose to build a consumption monitoring dashboard for a cloud data product.
On it, a user could view live usage, in terms of queries executed, compute runtime, data processed, and ultimately credits consumed out of a purchased package. Metrics are sink’d to Postgres via RisingWave, with changes in Postgres subscribed to by the frontend app for “streaming” updates.
If an account was at risk of churn (calculated via a batch ML model), a callout would appear on their dashboard offering assistance.
Catch a walkthrough here:
Backend Implementation
For the backend implementation, we chose to combine two types of data pipelines to support most business scenarios:
A streaming pipeline for real-time updates on user activity.
A batch pipeline for specific analytics tasks, such as churn prediction.
Both pipelines feed the PostgresSQL application DB (Supabase).

The goal was to ensure that all models and transformations were accessible via dbt, offering a complete overview of the workflows.
We aimed to have a single DAG encompassing the entire workflow: streaming pipeline, batch pipeline, and the caching layer.
Streaming pipeline
For the streaming pipeline, we simulated consumption messages streamed by ShadowTraffic generator.
These messages are sent to a Kafka stream and consumed in real-time by Risingwave, a streaming database.
Risingwave is open-source and greatly simplifies managing streaming pipelines with its SQL API. It enables easy joining, filtering, and aggregating of streams, tasks that are typically complex.
In our pipeline, it carries out basic computations and aggregates metrics before writing them to a table in PostgreSQL.

The SQL interface of Risingwave facilitates its integration into dbt:

Batch pipeline
For the batch pipeline, we aimed to simulate ad-hoc analytics workflows that are performed at regular intervals.
We developed a straightforward workflow to simulate churn prediction for each user, designed to run daily.

The batch and streaming pipelines are then combined into a view that determines whether a specific component should be displayed on the front end, based on:
The churn score of a user.
Their recent consumption.


Having the capability for real-time marketing actions is a significant advantage that many marketing teams aspire to achieve.
Orchestration
The entire backend is coded using dbt and SQL and orchestrated with dagster.
The widespread adoption of dbt in the industry makes it easier to build upon, as many tools offer integration capabilities.
We chose dagster because it allows for flexible parsing/fixing of the dbt DAG and enables the injection of variables at runtime.
Backend takeaways
Setting up multiple engines in the same dbt project is feasible but somewhat unconventional.
Indeed, dbt wasn't originally designed for this purpose for several reasons.
The first issue is engine interconnection. In dbt, loading external tables is done through a dbt source.
In our project, dbt models are therefore simultaneously a model and a source as illustrated below:

This necessitates duplicating the definition of a model in a source for use in downstream systems. This process is cumbersome and breaks the lineage in dbt.
However, we have found a solution by using model’s config, where you can supply dagster with the appropriate model asset key to get lineage across models properly.

It works but it’s tedious.
Additionally, the external table feature is not fully implemented across all providers.
While there is a dbt package called dbt_exteranal_tables, it doesn't cover all engines and necessitates refreshing the external table at each run using a pre_hook.
This can make the experience challenging, as developers are required to reimplement engine-specific creation or updating of external tables.
While it's technically feasible to implement a multi-engine stack, it requires a lot of manual configuration and tweaking.
Ideally, we would like a tool/setup that offers:
Cross-engine lineage, similar to dbt-core, but with a single run
An abstraction layer over storage systems to facilitate seamless dump and load of tables across different systems.
The freshness-based materialization features of Dagster/Snowflake dynamic table.
Frontend implementation

Building a “streaming” dashboard in React
On the frontend, we set out to build a basic dashboard that’d read metrics (credits consumed, compute runtime, data processed) written to Postgres.
The frontend responds to updates from the backend in ~real-time (using WebSockets), to follow the data-freshness-maximizing convention of cloud consumption monitoring dashboards like AWS, GCP et al.
Outside of typical application work (auth, routes, etc), building this embedded dashboard required work across 3 elements to build the application, which are all standard practice for any application developer:
REST endpoints to deliver data in the proper shape
Visualization components to display data
Subscriptions to respond to updates from the backend
Building analytics REST endpoints
As we saw earlier, dbt runs landed tables + views in our Postgres application db.
To make life easier on the frontend, we then turned those tables + views into endpoints, which produce a dataset with a specific grain. This removes the requirement for frontend devs to write raw SQL.
Supabase (the hosted Postgres version we used) leverages PostgREST to expose a REST API on top of your database. We used it to create + consume analytics endpoints in two ways:
If no further aggregation was required (ie dbt just landed it in the format that we’ll display it in the app), we do a very simple direct table read:
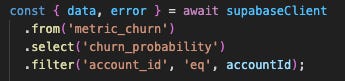
If aggregation was required for visualization, we’d write a view + parameterized database function in Postgres that referenced that view, and call it via `rpc` query:
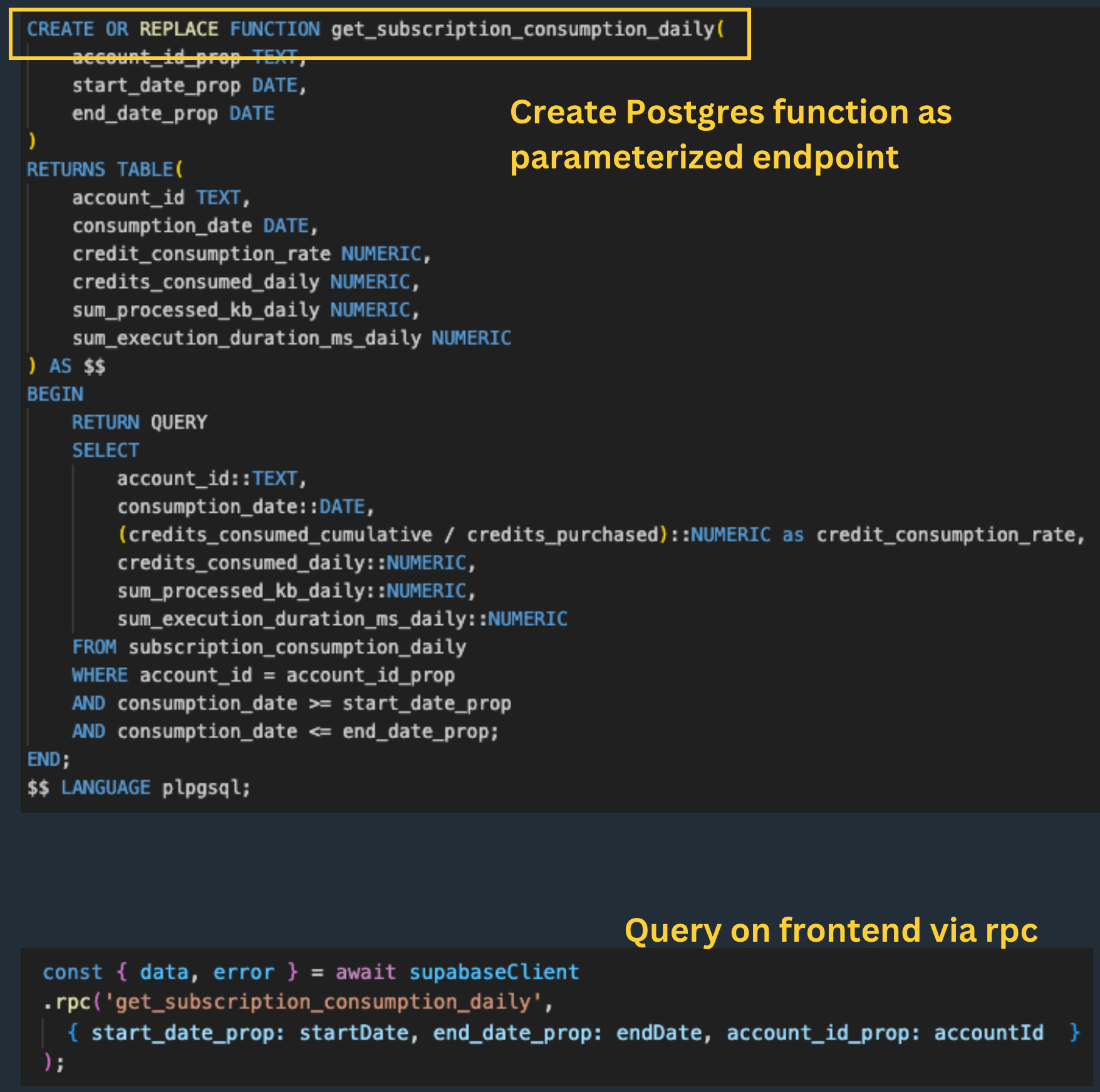
Creating aggregation functions was an unfortunate additional step (we wish postgREST would support aggregations in simple SELECTs), but as it’s plain-old-SQL it could be moved upstream into dbt.
However, there was something beautiful about leaving this final aggregation step up the frontend dev—David was free to play around with the props (query parameters) that he’d pass to the function, the fields it returned, etc, without any coordination with Julien as the backend engineer.
Generating dashboard components
For charting, we used Tremor, the wonderful open-source React data visualization library, which we used on the recommendation of the Tinybird team’s blog post on it.
We were able to easily customize components to work within the structure of the application (in terms of how we were passing props + data around from page to component):

Getting data into the right shape of data was less fun, though. As Tremor is a standalone charting library (doesn’t contain any embedded cache/transformation layer), we had to do a reasonable amount of component-level, last-mile transformation work within some components:

We were intimately familiar with the dataset (as we built it :), but can imagine this work being quite tedious for a frontend dev who’s less familiar.
For the future, we’d like to implement tighter coupling between analytics endpoints + visualizations (see ideas in “next steps”), to require less disjointed transformation work across the stack.
Subscribing to updates
New data was ingested into the backend every ~minute.
To refresh the frontend appropriately, we used Supabase’s real-time updates feature (which creates a WebSocket connection to Postgres):

This is wonderful for a demo, but in production for a cloud monitoring dashboard like this, we’d likely implement something more subtle, like a webhook to notify the frontend that fresh data was available for fetching.
The full power of a WebSocket connection is only critical for operational dashboards in finance, manufacturing etc where moment-by-moment decisions are being made.
Frontend takeaways
There were 2 aspects of the app developer experience that left us wanting more:
Disjointed transformations between backend and frontend
Getting from raw events to a React visualization component required 3 layers of transformation:
Backend pre-aggregation: Raw -> metrics (s3 -> Postgres in our case), which occurred in dbt-duckdb in dagster
At query time: Metrics -> correct grain for visualization (via Postgres views / functions)
In-component: Correct grain -> visualization-ready format (via Javascript)
This required a lot of forethought + coordination between frontend and backend, to decide on the optimal point of division for pre-aggregation. This isn’t a bad thing! An hour of UX thinking saves 10 hours of development time.
Step 2 (delivering data from server to client at correct grain) is the typical promise of a “semantic layer,” or a package interface like dpm. But—once data lands on the client side of the application, it’s basically a hearty handshake and good luck to the frontend dev to be able to use it correctly in components.
We’d love to see tighter coupling between cached metrics and visualization component libraries (steps 2 and 3), to reduce Random Acts of Transformation in data apps. Cube (w/ “export to React” in their schema explorer) + Propel Data (w/ their own component library) are solving this at a platform level, and we look forward to the work Malloy is doing on an embedded chart renderer for an open-source solution.
The need for data contracts
We started with a spreadsheet that contained draft schemas for each table/view, but as happens for any project, our ending schemas drifted a bit from the initial target.
This highlighted the need for data contracts, particularly on the terminal nodes of the dbt DAG (which were queried in Postgres to produce analytics endpoints). If we were starting over, we’d probably write these dbt terminal nodes + data contracts first (unblocking Postgres + frontend development), and then build up to them left-to-right in the DAG.
Next steps
So, how’d we do? Let’s grade ourselves on the 3 goals from the intro:
Developer experience: B+
Totally feasible to implement, and we were both able to work in data eng/frontend dev native tooling, but both required some hacks (see next steps below).
Cost reduction: TBD
Haven’t had time to count yet, but the signs are looking good.
Schema drift: F
Didn’t yet implement contracts on terminal nodes/backend endpoints, but definitely could’ve used them!
--
As a next step, we’re interested in exploring paths to take the hacks built into this data backend and officially extend (via plugin/extension/package/script etc) tools like dagster + dbt to make this type of data backend (blending data from Snowflake, s3, streaming, etc) easy to build + maintain. If you’re interested in exploring that path, get in touch!
On the frontend, we’re interested in exploring a tighter integration between data fetching + chart rendering (via Malloy, Propel or Cube), and may cover that piece in future posts.
Get in touch!
If you’ve built a data backend to serve embedded analytics or another customer-facing use case, we’d love to hear from you.
What was hard? What was easier than you thought it’d be? What’d we miss?
Thanks for reading,
David & Julien
 | A guest post by
|