


Code as Data & Data as Code
Ju Data Engineering Weekly - Ep 35

The data industry is establishing itself as an independent branch within the software industry.

[…]

Indeed, as data usage increases across industries, we are building more and more powerful data pipelines to meet growing challenges. Our data platforms need to process:
Large volumes of data
From multiple sources
At an increased speed (streaming)
A significant challenge in data applications is meeting these requirements while maintaining data quality.
Data quality is probably whats sets data engineering apart from traditional software engineering.
Many data engineers share a common concern when deploying new code: "breaking" something in the data pipeline.

Data quality is the top priority for data engineers, and it's a subject that isn't typically addressed by conventional software engineering practices and development processes.
In data engineering, it's essential to validate not only how your code works but also how it affects the data itself.
In this article, we'll explore how to integrate data quality prevention into a data engineering development process.
Dev data == Prod data
In contrast to software engineering environments, which are often isolated, data applications require minimizing data discrepancies between environments.
Testing your code on incomplete or outdated development data increases the risk of missing data quality issues.
Ideally, you want different versions of your code (Git branches) to run concurrently on the same production data.
Cloud warehouses simplify this with zero-copy clones between environments, but it can be more challenging on AWS, Azure, or BigQuery.
However, recent infrastructure-as-code frameworks allow you to isolate your code from data and run your development on production data in “ghost mode”.
More on the subject here:
Test in Prod !! Ghost Mode Development Process.

The development process is a crucial aspect of building and maintaining a successful data platform. It should enable developers to thoroughly and rapidly test new features before deploying them. Using multiple development environments is a standard practice in data engineering to isolate code testing from the production environment.
Manual Data Diff
Testing your code on production data is just the beginning.
When developing new features, it's crucial to ensure that your code doesn't unintentionally affect the data.
In software engineering, unit tests typically cover the logic within your code, usually enough to ensure it works in production.
However, in data engineering, engineers need to go a step further!
To avoid introducing regressions with code changes, a best practice is to calculate the data delta before and after a transformation.
Here are some examples of simple data diff operations:
compare columns:
with prod_column as ( select col from PROD_SCHEMA.table ), with dev_column as ( select col from DEV_SCHEMA.table ) [ - compare distinct value - compare mean / max / min ect... ]outer join to diff the rows
SELECT * FROM PROD_SCHEMA.table EXCEPT DISTINCT SELECT * FROM DEV_SCHEMA.table
This delta check can be done manually, but as your platform grows, writing these queries can become time-consuming to write.
Fortunately, some tools exist to automate this process.
Automatic Data Diff with DataFold
Among these tools, there's DataFold, designed to automate data testing for data engineers. It simplifies the data-diff process, making it easy to track how your code influences data.
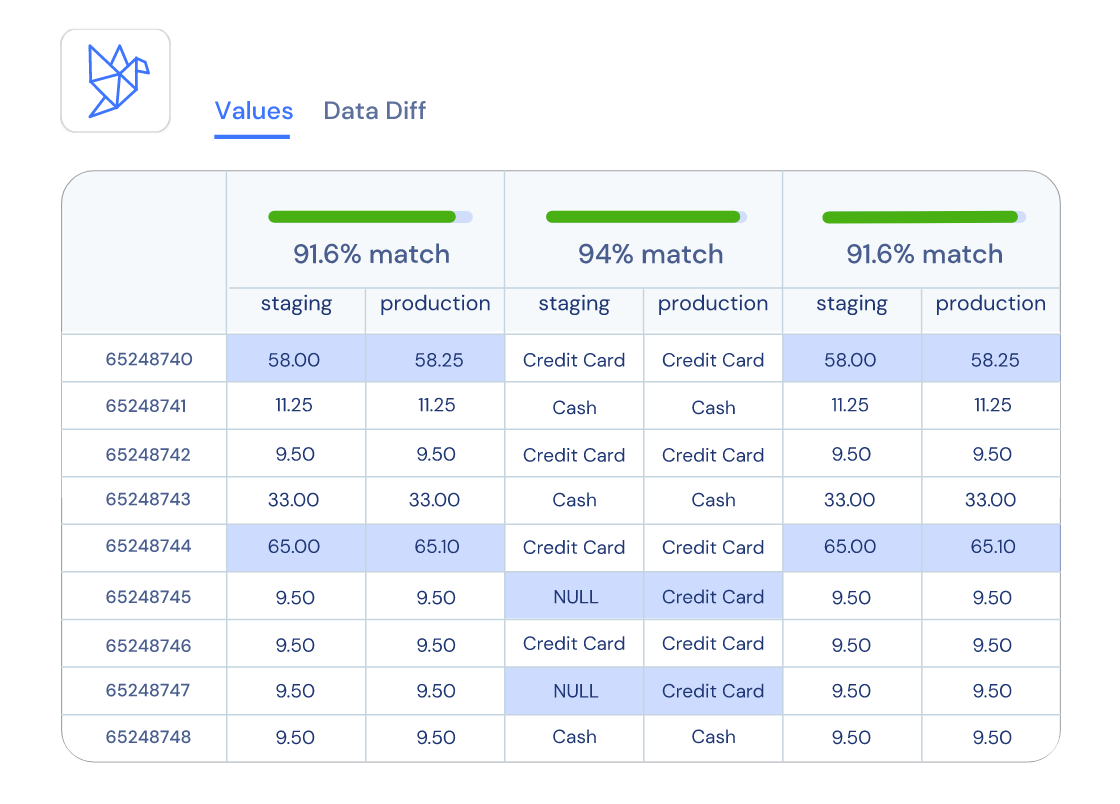
What I liked is its integration with DBT, which greatly streamlines the development process for data engineers:
dbt run --select <MODEL> && data-diff --dbtDatafold is triggered together with the DBT run command and calculates for you the data updates:

Their cloud version allows you to take it a step further:
dbt run --select <MODEL> && data-diff --dbt --cloudAfter running DBT, Datafold provides a link to a dashboard giving a more in-depth overview of all the updates.

I found the tool quite powerful, and its integration with DBT smooth and efficient.
Git semantic for Code & Data
I came across a intereseting paper from Bauplan Labs this week, discussing the architecture of their serverless data platform.
Their proposed development process involves versioning both code and data using:
Git for code versioning
Nessie for data versioning
Data versioning, in my opinion, represents the next level of maturity beyond automated data diff calculations.
Nessie is mainly oriented towards managing Iceberg tables but provides an interesting approach to handling data versioning.
They have adapted concepts from Git for the versioning of data:
Commit: A consistent snapshot of all tables at a particular point in time.
Branch: A human-friendly reference that a user can add commits to.
Tag: A human-friendly reference that points to a particular commit.
Hash: A hexadecimal string representation of a specific commit.
This enables workflows where users can create table versions, add or update records in a specific branch, and check deltas between table versions using git-like commands:

In the proposed data platform, the development workflow follows these steps:
A user creates a new code branch named for example “feat_1”.
Nessie automatically generates a corresponding data branch with the same name, “feat_1”
When the feature code is executed, Nessie creates against a new data branch for that specific run, enabling a check of the delta produced by the run.
If the run is successful, and the data changes meet validation criteria, the run branches are removed, and the data changes are committed to the data branch.
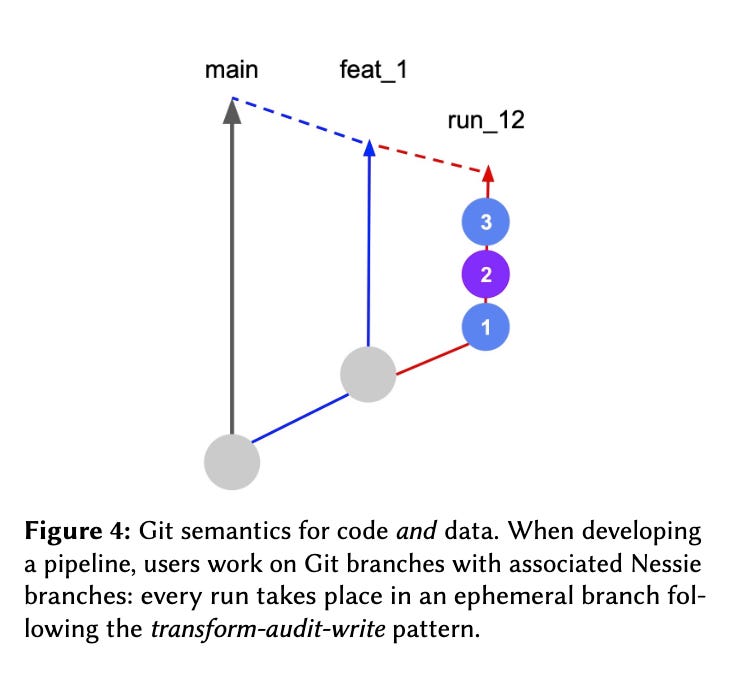
I find the Git semantics for data and code to be elegant because they enable tracking of all crucial information:
identifying which piece of code has modified specific data.
This level of auditing and tracing should be the standard our industry aims to achieve.
Thanks for reading,
-Ju
I would be grateful if you could help me to improve this newsletter. Don’t hesitate to share with me what you liked/disliked and the topic you would like to be tackled.
P.S. you can reply to this email; it will get to me.