
Airflow vs Dagster vs Kestra
Ju Data Engineering Weekly - Ep 53
After the successful collaboration with Benoit Pimpaud, Emmanuel, CEO of Kestra, reached out to me.
We had an interesting conversation about the state of orchestrators and the features important for Data engineers in their day-to-day projects.
He proposed to support one of my posts, which I gladly accepted, as I've been eager to benchmark various orchestrators for a long time.
I focused on three open-source orchestrators: Airflow, Dagster, and Kestra.
Airflow was chosen as the established orchestrator with the biggest market presence. Dagster is selected for its emphasis on data engineering tasks, and Kestra as the newcomer with its YAML-based declarative orchestration.
This post doesn't aim to choose the best tool, but rather to explore their differences in the data engineering context.
Note: While this post is sponsored, there have been no influence on the editorial direction.
Brief Intro & Semantic
Let's quickly dive into each tool to gain a high-level understanding of their concepts.
Airflow operates as an orchestrator, executing DAGs composed of individual tasks.

DAGs and tasks are defined using Python and can be built using a library of predefined operators.

Kestra is also a task-based orchestrator.

In Kestra, DAGs are referred to as "Flows" and consist of a sequence of tasks defined in YAML files and provided either by Kestra core or via plugins.

Dagster approaches orchestration differently.
Instead of viewing the orchestration job as a graph of tasks to execute, Dagster considers it as a graph of “software assets”:
An asset is an object in persistent storage, such as a table, file, or persisted machine learning model.
A software-defined asset is a description, in code, of an asset that should exist and how to produce and update that asset.
Each node of a Dagster dag corresponds to a data object and not to a task.
As for Airflow, Dagster DAGs are defined in Python:

Connectors
It's usually not recommended to run data transformations directly inside the orchestrator.
Instead, the orchestrator should mainly trigger external services like Lambda, ECS Tasks, and Step Functions, which embed the business logic.
In this context, Airflow's history and large community support are hard to beat in terms of the number of connectors supported (at least for now).
For example, consider the list of AWS services supported:

Kestra and Dagster implement only some of them but offer the possibility to fall back to boto3 (Dagster) or AWS CLI (Kestra) if needed.
Kestra distinguishes itself on this topic by providing pipeline blueprints. These blueprints simplify the process of starting new workflows by requiring only the copying and pasting of a YAML file.

Automation
All three platforms can schedule tasks regularly with CRON triggers. However, they offer different advanced automation tools.
Sensors
Sensors are tasks designed to stop the workflow until something specific happens outside the system: waiting for a queue to empty or a file to appear in a storage service.
Dagster proposes simple Python function decorators where the developer is free to implement his own sensor logic.

Airflow and Kestra go a step further by providing pre-built sensors.
Example of Airflow sensors:

Here's an example of the Kestra S3 Sensor (among others):
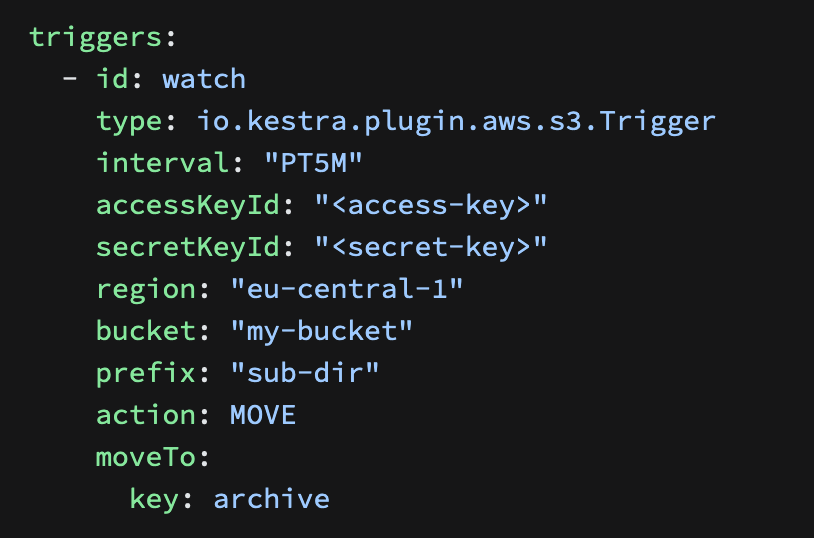
with a special mention for the HTTP sensor:

Auto-Materialization
Dagster provides a unique feature that automatically materializes assets.
As projects get bigger and workflows get more complicated, it can be difficult to keep track of when a specific dataset will be updated.
Dagster's allows users to define asset-specific auto materialization rules that are reflected to the upstream dependencies automatically.
This can be great for the orchestration of big dbt projects with lots of dependencies and enables rules such as:
“The events table should always have data from at most 1 hour ago.”
“By 9 AM, the signups table should contain all of yesterday’s data.”

Scalability
When selecting an orchestrator, its performance under heavy loads is often overlooked during testing.
For instance, in a project I worked on, we encountered an issue where workers in AWS MWAA (managed Airflow) were lost at a specific scale.
I ran a little test by setting up each orchestrator on my Mac M3 using Docker.
I then executed 100, 500, and 1000 tasks at the same time in each orchestrator and recorded how long the entire process took.
For Airflow, I created a main DAG that triggered sub-DAGs. Each sub-DAG ran tasks using the PythonOperator to print messages.
Deployment doc.
For Dagster, I used the
@op(out=DynamicOut())feature to run multiple tasks in parallel, each just printing a message.Deployment example.
In Kestra, I used
io.kestra.core.tasks.flows.ForEachItemfor initiating sub-flows, where each sub-flow executes a single print task.Deployment doc.
It's crucial to note that I did not fine-tune the setup of each tool; I followed the get-started guide.
The results are as follows:
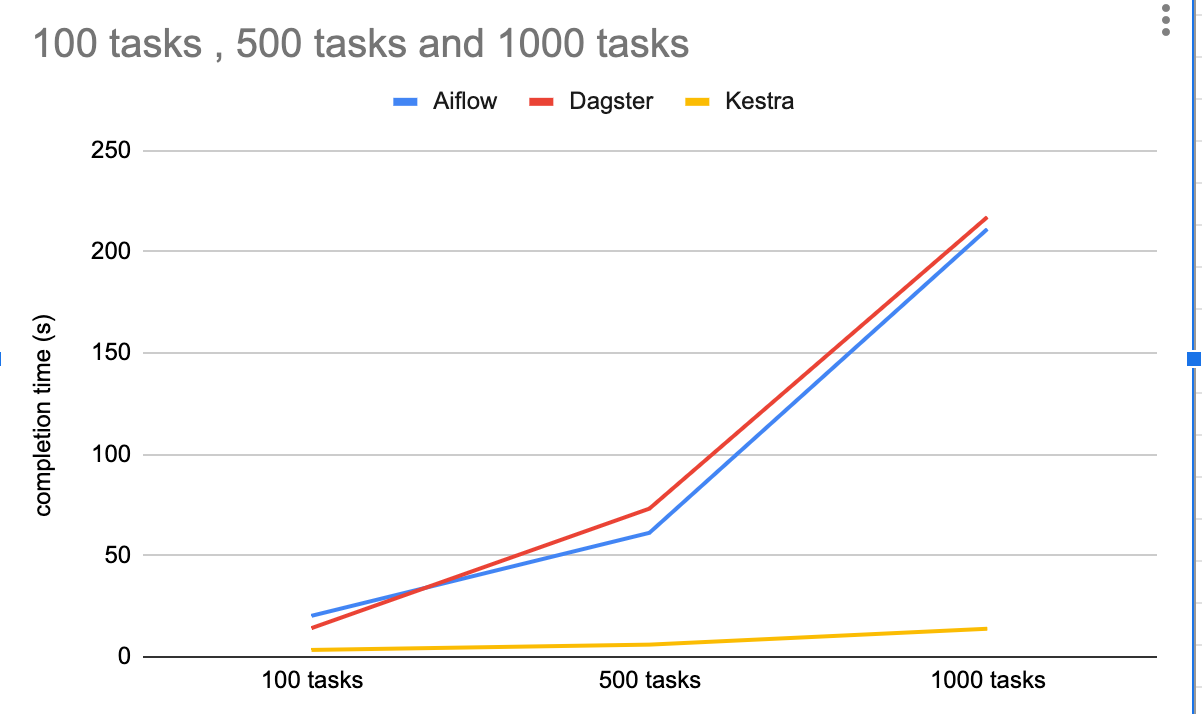
I was surprised by the performance gap.
The difference may arise from Airflow and Dagster being written in Python, while Kestra is developed in Java.
Kestra seems to have greatly optimized its executor, which is useful in data engineering where processing is handled by external workers and not handled inside the orchestrator.
Dev Experience
Each of these tools approaches the dev experience differently.
Indeed, Airflow and Dagster both offer high-level Python constructs that developers can directly mix with custom Python code. This approach provides a significant amount of freedom, enabling easy customization according to specific project requirements.
However, the risk lies in this flexibility; without strong best practices, projects can become challenging to maintain.
Kestra adopts a different approach by using YAML as the primary user interface and not a scripting language.
While this may make building dynamic behaviors more complex, once you understand how the blocks/plugins are constructed, creating new flows becomes very fast: you are just configuring blocks vs coding / maintaining Python files.
In conclusion, the choice among these three tools depends on what factors weigh more heavily in your decision matrix, as each tool has distinct strengths and focal points:
Airflow is recognized for its stability and solid community support.
Dagster is great at handling complex data engineering tasks: freshness-based materialization, dbt DAG parsing and backfilling.
Kestra distinguishes itself with its YAML approach, which speeds up the development process, and its good scheduling performance.
Thanks for reading and special thanks to the Kestra team for the collaboration,
-Ju

I would be grateful if you could help me to improve this newsletter. Don’t hesitate to share with me what you liked/disliked and the topic you would like to be tackled.
P.S. You can reply to this email; it will get to me.
Excellent as usual! One of the key advantages from Dagster is the fact it is possible to capture metadata from external services (not actually managed via Dagster) and still represent the full picture. For example, using a daily Fivetran sync to ingest some data.
Also, it is possible to implement a fix and retry a "flow" from the point it failed - without needing to restart from scratch.
I would be curious to learn if Kestra supports such functionalities.
Great write up!