


Enabling a Data Engineering AI Agent to Learn New Frameworks
Data Eng Weekly - Ep 21

Over the past week, I've been working on enriching the capabilities of the Data Engineering Autonomous Agent (DEnGPT), which I initially introduced in a previous post.
This agent is designed with an ambitious long-term goal - to autonomously generate, manage, and maintain data pipelines at scale.

In an effort to promote transparency and allow others to delve into the workings of this cutting-edge tool, I've decided to release the source code of this initial agent.
You can find it in this repository: https://github.com/hachej/dengpt.
I'm eager to hear your insights and welcome all constructive feedback.
Why does the agent need to learn?
One of the major limitations of the agent is the restricted data on which the underlying large language model (LLM) has been trained on.
ChatGPT, including this current version, has been trained on data since September 2021. As a result, it won't be aware of any frameworks or tools that emerged after that time.
Let’s have an example: Terraform Snowflake provider.
I wanted to use Terraform in order to create and manage various Snowflake objects:
Accounts
Users
Roles
Tables
ect
However, the Terraform snowflake provider was barely existing in 2021 and has evolved a lot these last months.
For that reason, when you ask Chat-GPT to create a new Snowflake account with Terraform you get this answer:
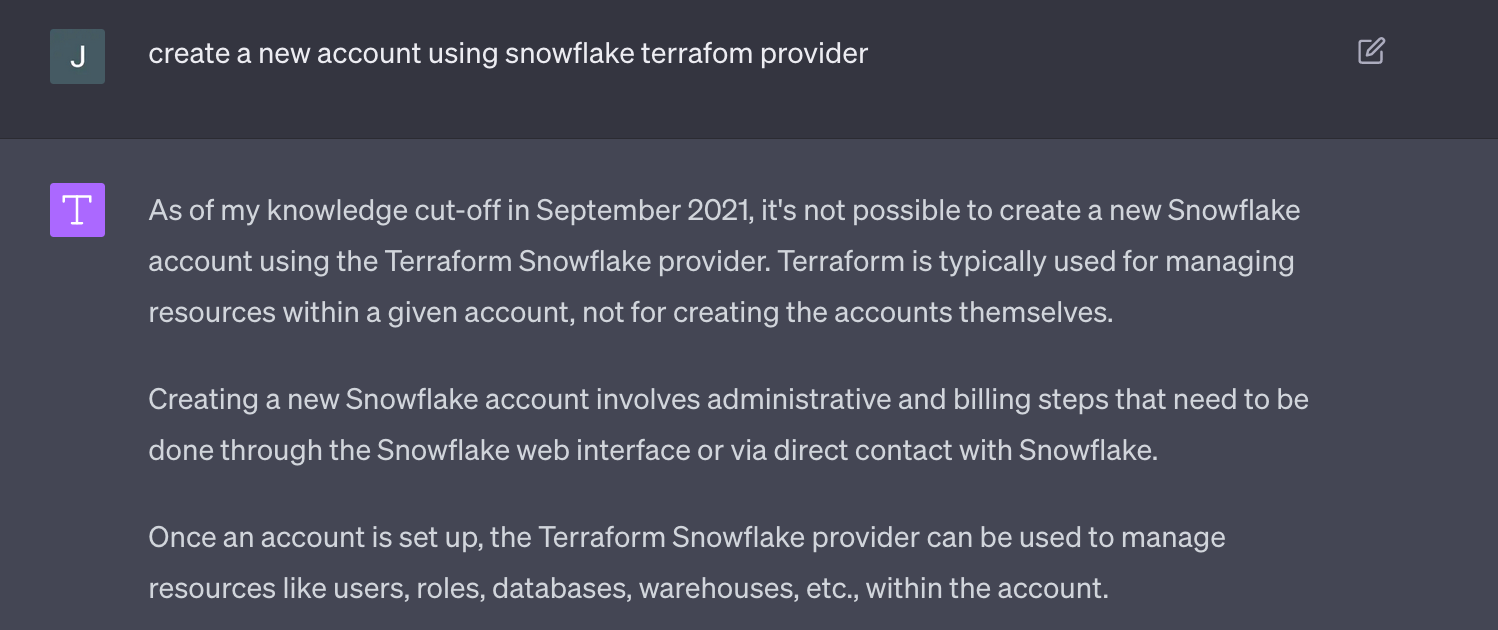
…. even if a corresponding resource exists in the Terraform documentation.
Provide a corpus of documents to the agent
The Terraform Snowflake provider documentation is too long to fit within a single prompt, which is limited to approximately 500 words.
Consequently, we need to establish a method to pre-select a set of documents from the documentation that will be supplied to GPT along with the specific user prompt.
To overcome this limitation, we operate in three steps:
step 1: load each Terraform Snowflake Provider documentation page in a vector database

In this step, we convert each document from the documentation into a format suitable for vector storage.
Transforming a document into a vector (called embedding) enables us to employ vector computation techniques to calculate the distance between texts in a corpus ( law distance = high similarity).
The transformation into a vector is done using an OpenAI service that can be invoked through one of their API endpoints.
Step 2: Select the most relevant document based on the user prompt

When a user provides a prompt, it's necessary to determine which document(s) from our vector database are most relevant to the prompt.
This involves encoding the prompt into the same vector space and then searching the database for the closest matches.
Once the vector representation of the prompt is computed, we can identify the most pertinent document in the documentation that aligns with the user's request.
Step 3: Pass the selected document with the prompt to Chat-GPT

Once the relevant document is selected, we can append it (or a summarized version of it, if it's too long) to the user's prompt. This extended prompt is then fed into Chat-GPT, enabling the model to generate a response that takes into account both the user's original question and the additional context from the pertinent documentation.
And that's it!
Implementation
As for the code implementation, we can use the Langchain framework to leverage existing components that integrate this logic.
Langchain provides "loaders" and “index” objects that you can use to get documents into the vector database:
loader = GitLoader(
clone_url="https://github.com/Snowflake-Labs/terraform-provider-snowflake",
repo_path=local_path,
branch="master",
)
loader.load()
loader = DirectoryLoader(local_path + "docs/", glob="**/*.md", show_progress=True)
index = VectorstoreIndexCreator().from_loaders([loader])and then you can simply query the index module to get a response to a prompt:
response = index.query(query)Let’s have a look at the previous Snowflake example.
We provide the following prompt
I want to create a snowflake account for user a@b.com and password 123123 using terraform
list all the terraforms ressourses required.
Write the terrafom module for each of these ressourcesand now we get the following answer:
You would need to use the snowflake_account resource to create the account. The example usage provided in the context shows the syntax for creating a snowflake_account resource. You would need to replace the values in the example with the values for your account, such as the name, admin_name, admin_password, email, first_name, last_name, edition, comment, and region.
Example Usage:
```terraform
provider "snowflake" {
role = "ORGADMIN"
alias = "orgadmin"
}
resource "snowflake_account" "ac1" {
provider = snowflake.orgadmin
name = "SNOWFLAKE_TEST_ACCOUNT"
admin_name = "a@b.com"
admin_password = "123123"
email = "a@b.com"
first_name = ""
last_name = ""
must_change_password = true
edition = "STANDARD"
comment = ""
region = ""
}With this approach, our data engineering agent can now learn any framework or tool that best fits the pipelines that need to be built.
The possibilities are indeed endless: we can supply the agent with any framework documentation or even any data source documentation - including APIs, data sources, data models, etc. - and the agent will be capable of interacting with them.
Thanks for reading,
-Ju
I would be grateful if you could help me to improve this newsletter. Don’t hesitate to share with me what you liked/disliked and the topic you would like to be tackled.
P.S. you can reply to this email; it will get to me.