I'm Julien, freelance data engineer based in Geneva 🇨🇭.
(Almost 🙃) every week, I research and share ideas about the data engineering craft.
Not subscribed yet?
👨🏽💻 echo {YOUR_INBOX} >>
While all eyes were on Snowflake, Tabular, and Databricks, GCP quietly rolled out its Iceberg table integration.
This integration is not new, as they already supported reading Iceberg tables since 2022.
Over the last month, many changes have brought BigQuery back to the Iceberg spotlight.
But with all these changes, things feel a little bit confusing…
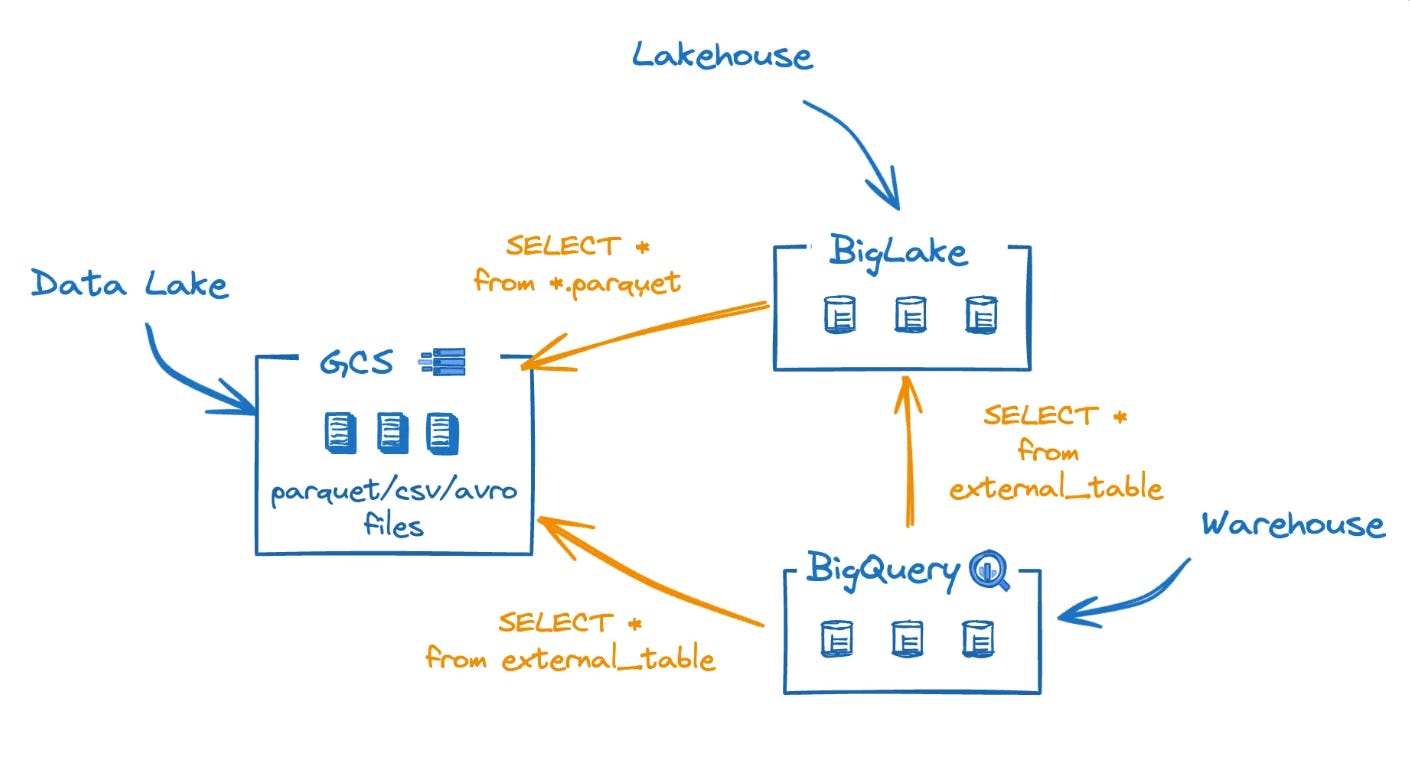
If you try to dive into the Iceberg implementation in GCP, you will find two flavors:
BigLake external tables for Apache Iceberg
BigQuery tables for Apache Iceberg, also known as BigLake Managed Tables
Together with Borja, we break it down in this blog post and explain BigLake, its connection to Iceberg and BigQuery, and how the related acronyms and products have evolved.
It’s a storage engine that enables querying storage objects: Avro, Parquet, CSV, and recently Iceberg.
These formats were already queryable from BigQuery using external tables.
BigLake, however, adds governance, multi-engine support, and cross-cloud capabilities.
GCP & Iceberg - v0: BigLake Metastore
Initially, to support Iceberg in BigLake, a new metastore entered the game: BigLake Metastore or BLMS for short.
It acts as a drop-in replacement for Hive and an Iceberg Catalog.
But this catalog/metastore was VERY custom and opaque from the users.
The only way to interact with it—essentially to create a table—was through Spark and Dataproc stored procedures.
This left almost no control via BigQuery, aside from creating a table that points directly to the latest manifest file.
Until recently, this was the only way to interact with Iceberg tables through BigQuery, but things have drastically changed in the past few months.
GCP & Iceberg - v1: BigLake Managed Tables (BLMT)
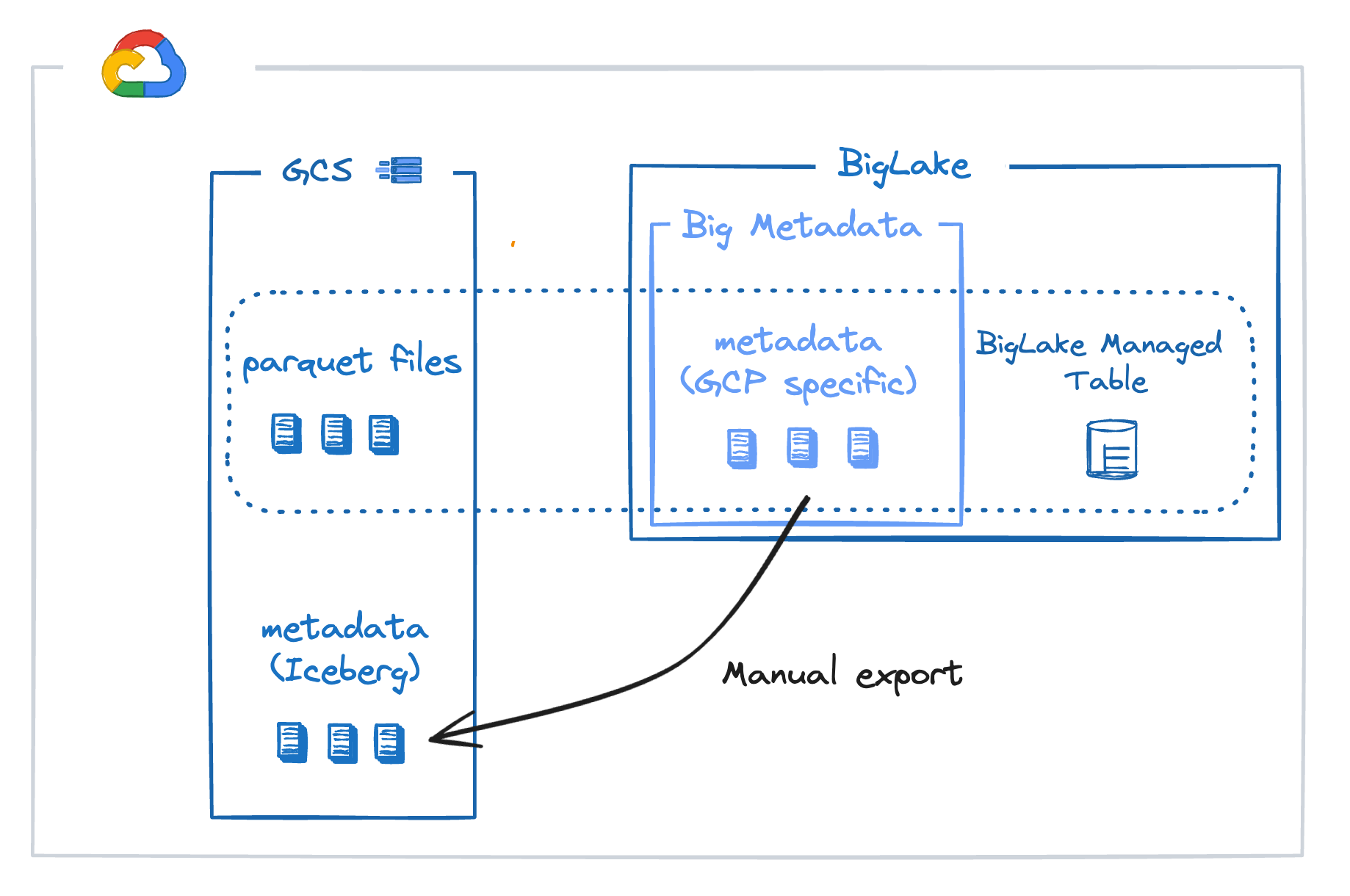
Last summer (2024), GCP released BigLake Managed Tables (among other BigLake features) and enabled mutable BigQuery tables for Iceberg.
Data is now stored in Parquet in external GCS buckets, with metadata managed by two new components: BigLake Managed Tables and Big Metadata.
BigLake Managed Tables = Big Metadata + parquet files in GCS.
Additionally, users can export an Iceberg metadata snapshot to cloud storage, allowing any Iceberg-compatible engine to query the data.
For now, these exports have to be triggered manually, although they will eventually be part of the table commit process.
YATF: Yet Another Table Format
Yes, you heard read that right, BigLake Managed Tables and Big Metadata.
Google relies on an internal table format that can export iceberg metadata but doesn’t implement the Iceberg Rest API internally.
In other words, BigLake/BigQuery supports Iceberg, but it is a by-product of their internal table format BigLake Managed Tables+Big Metadata.
Yes, again, you are right; this means that there’s a new player in the game: BigLake Managed Tables, Iceberg, Delta, and Hudi...
While Big Metadata and BigLake Managed Tables remain confined to GCP, it’s another concept to consider.
But understandably, with this architecture, GCP retains control over governance, security, and metadata management through BigLake and its Storage API read/write capabilities.
Let’s now look at the integration of Managed Iceberg Tables (BLMT) with external engines outside of GCP.
GCP Iceberg → Outside world
Read BLMT from outside GCP
There are two options to interact with BigLake Managed Tables in Iceberg format:
Through the Storage API. This means the engines must support the API implementation (and the actual read still relies on a GCP product).
Using the version-hint.txt to point to the latest manifest file. For now, the manual export of the iceberg metadata includes a version-hint file that can be used to keep other engines pointing to the latest metadata.
Write BLMT from outside GCP
The only way to write to a BigLake/Bigquery table is through the Storage API.
This is because, technically, we won’t be writing into Iceberg but into the custom Big Metadata, which can be exported as Iceberg metadata.
There’s no Iceberg REST API to connect to.
An engine that writes into BigQuery Iceberg tables must implement the Storage API specification.
Big players like Spark, Flink, or PubSub already support this connection.
However, other tools like PyIceberg are not compatible 😢.
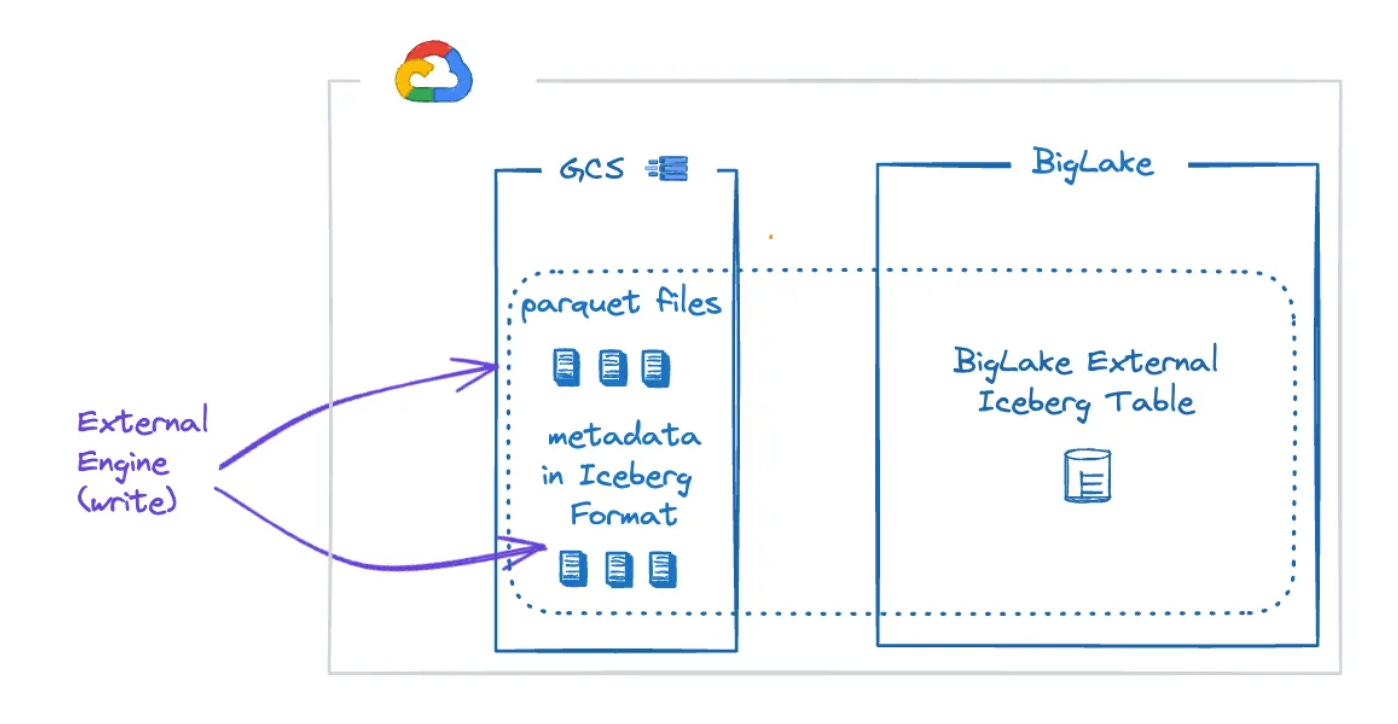
Outside world → GCP Iceberg: External Iceberg Table
GCP created a new table type to consume Iceberg tables written by other engines: the BigLake External Iceberg Table.
This table points directly to an existing Iceberg table's data and metadata files, whether stored in GCP, Amazon S3, or Azure Blob storage.
There is no external catalog or version-hint integration, so you must recreate the table when the manifest file is updated.
Note: Technically, you can create a read-only AWS Glue federated dataset, but this would run through BigQuery Omni. It is a different product with its own limitations, pricing, and other technical aspects, so it is not an out-of-the-box integration for BigQuery.
Unfortunately, BigLake cannot write to an Iceberg table managed by a different catalog.
What about BigQuery?
After all this, there are two ways to interact with Iceberg through BigQuery/BigLake:
• BigLake Managed Tables
• BigLake External Tables for Apache Iceberg
BigQuery can then interact directly with both types of tables: it can read and write to Managed Tables but only read from External Tables.
This kind of setup is actually quite similar to Snowflake:
BigLake External Tables = Snowflake Iceberg table managed by an external catalog
They have the same read/write integration: Snowflake can only read from an external catalog, and an external catalog can only read from a Snowflake catalog.
Read Performance
We decided to run a few queries against a 1TB table in all three formats (BigQuery managed, BigLake managed, and external Iceberg tables) on an on-demand project with up to 2000 slots.
These results are very, very promising!
However, this is by no means an in-depth and significant benchmark.
A fair comparison would involve measuring multiple variables, such as the type of sorting used in the parquet files, clusterings/partitioning, types of queries used, and the number of slots available…
So many factors are involved that a benchmark would require an entirely different blog post.
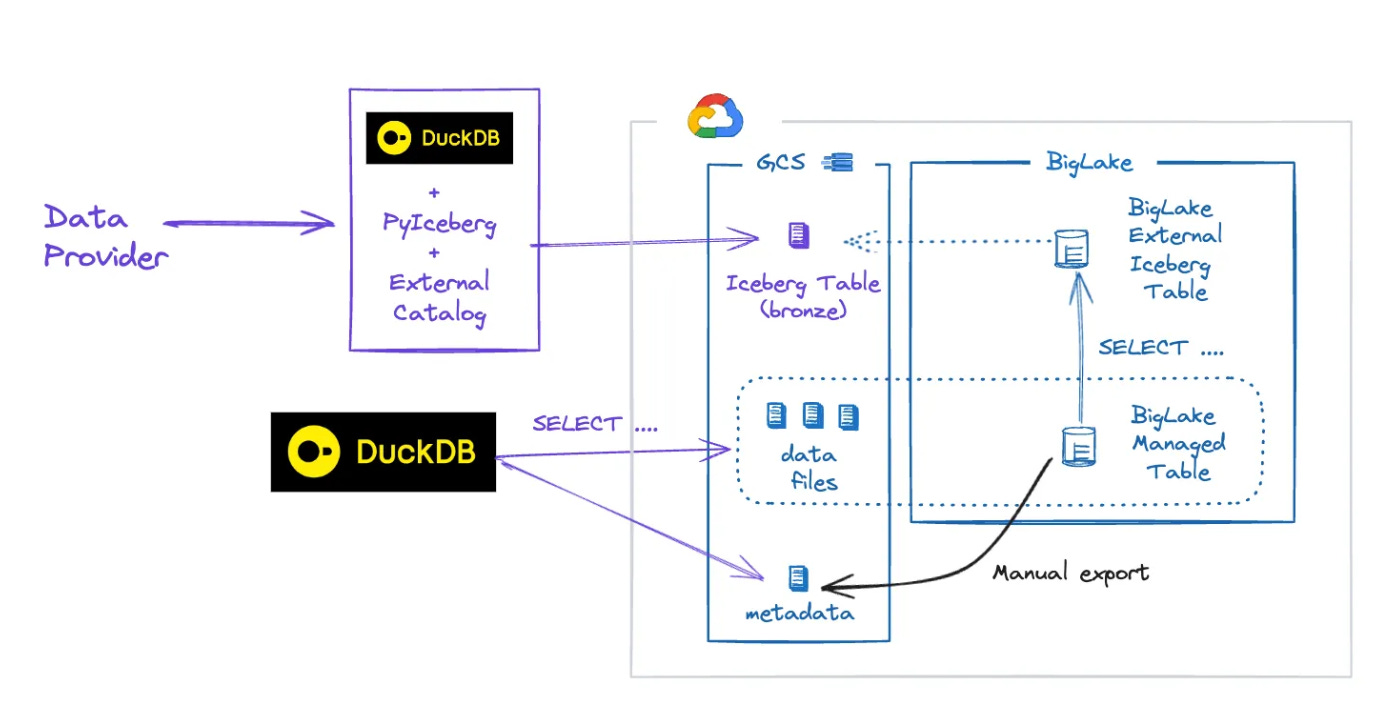
Multi-engine pipeline
One of the cool benefits of the Iceberg is the ability to mix engines.
We’ve explored with Borja this topic extensively over the past few months:
Given all the explanations above, here’s a design that could be used to build a multi-engine stack in GCP, mixing BigLake/BigQuery and DuckDB.
We may build a proper implementation in the coming months to provide more concrete feedback on this design.
Stay tuned!
Thanks for reading
Borja & Ju
Building a data stack is hard—too many moving pieces, too little time.
That’s where Boring Data comes in.
I’ve created a data stack onboarding package that combines ready-to-use templates with hand-on workshops, empowering your team to quickly and confidently build your stack.
Interested?
Check out boringdata.io or reply to this email—I’d be happy to walk you through our templates and workshops.











Would love to see more benchmarks between iceberg and bigquery tables
Nice read! Thanks for sharing.