
Multi-engine Stacks Deserve to be First Class
Ju Data Engineering Weekly - Ep 69


We,
and , have been imagining what’s possible with multiengine workflows for a while now (v0, v1).Our imaginations have deepened with the adrenaline rush of announcements from Snowflake about open-sourcing the Polaris Iceberg catalog and Databricks acquiring Tabular and the team that created the Iceberg.
An amazing Iceberg catalog experience is the next milestone in making this practical and, in turn, much more powerful.
But until then, we built and wrote a proof of concept to explore the easy stuff in setting up a multiengine workflow, the frustrating stuff worth tolerating, and the frictions that make it not worth pushing to production.
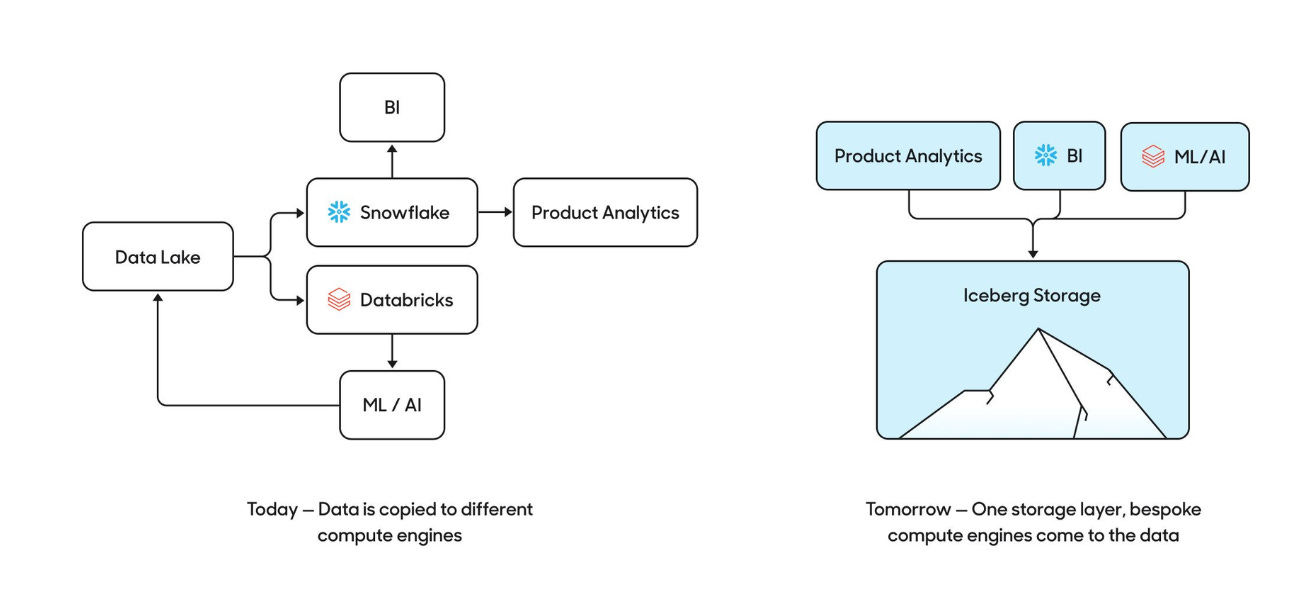
Like how multi-cloud is becoming more popular for scaling in the cloud, we see that same pattern cascading into our data workloads.
We’re excited to live in a world where anyone can upload their own data to any query engine, and “it just works.”
SQLMesh is the vehicle for understanding what’s possible.
Nothing here is best practice, so we have a bit more fun.
Note: All code presented is for research and exploration purposes. We do NOT recommend you leverage this code in production (pretty please). Disclaimers for limitations that contorted our code in a specific way are included throughout this post.
The Data Architecture
Let’s have a look at the stack we have built.
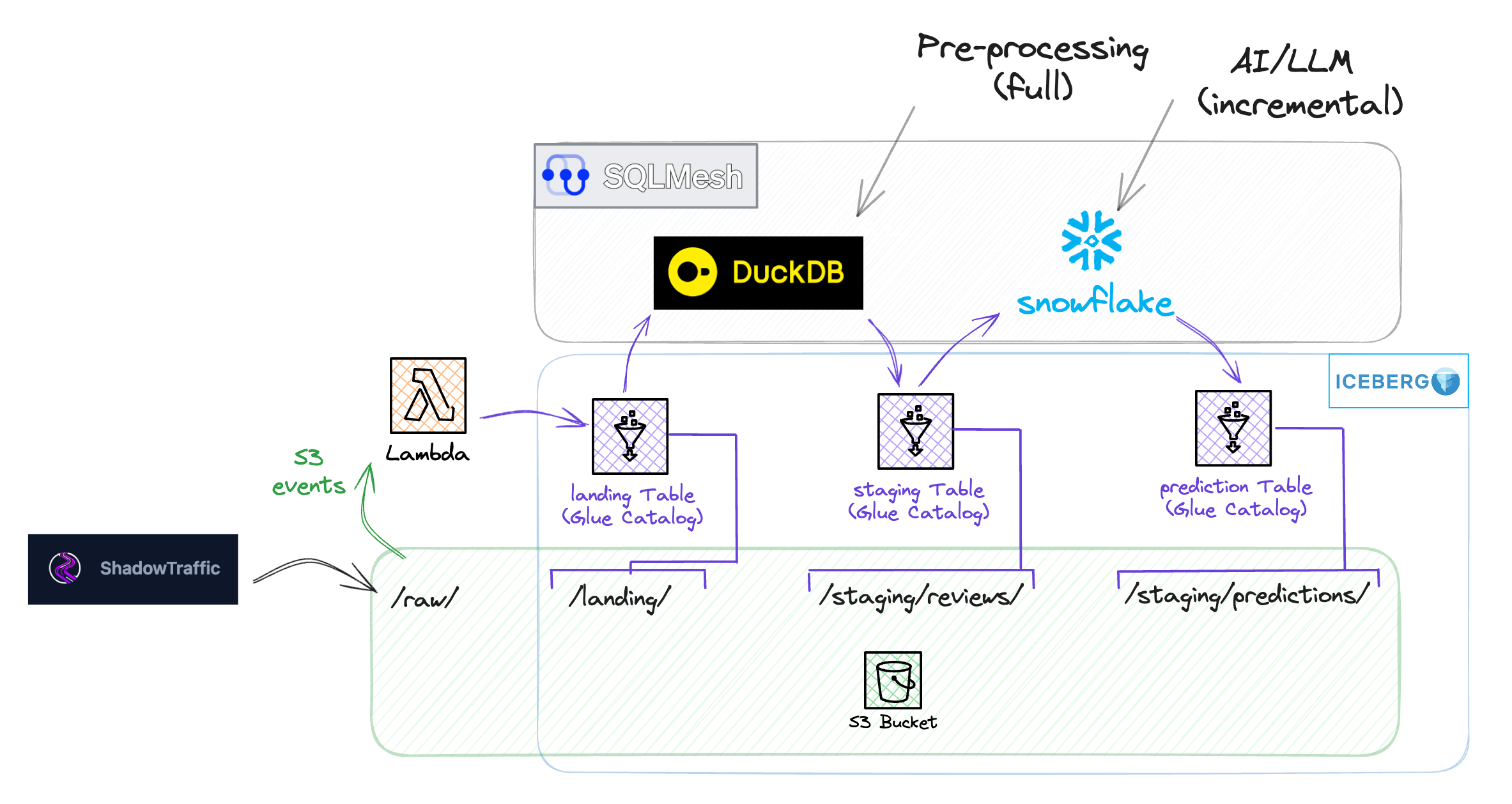
Compute: DuckDB + Snowflake
In this PoC, we want to mix running a transformation pipeline with DuckDB and Snowflake. Why?
Because they are highly complementary:
DuckDB is part of the in-memory OLAP family (along with DataFusion and Polars). It is the cheapest and easiest way to transform a dataset, provided it fits in the machine’s memory. We want to use it for all SQL operations on reasonably sized datasets.
On the other hand, Snowflake represents large-scale engines that offer unlimited scalability and platform integration with many utilities. We want to use it for large-scale processing, advanced transformations (with LLMs), and platform features like their Marketplace.
The possibility of mixing them is highly compelling for several reasons:
Cost reduction
Avoid vendor lock-in
Mix and match engine-specific features for parts of the data pipeline
Storage: Iceberg
Iceberg provides a standard method for storing data and serves as a common storage layer across various engines.
We have chosen AWS Glue as our catalog due to its seamless integration with the AWS ecosystem, ability to work with Snowflake as an external catalog, and compatibility with PyIceberg.
Check out this article if you want a recap of how Iceberg works:

In this PoC, we will use PyIceberg to read and write data to Iceberg, as it offers a much smoother user experience than the historically used Spark.
Transformation: SQLMesh
Having models split across multiple engines can quickly become a mess.
Fortunately, we have transformation frameworks specifically designed to bind models together in a proper DAG.
These frameworks, whether dbt or SQLMesh, are primarily designed for a single query engine.
Let's stress test one of them in a multi-engine setup: SQLMesh.
Demo code
Here’s a Github repo with all the relevant code.
These are the basic things needed to set it up.
For full details on setup, look at the README within the repo.
Let’s run it!
Bringing data in
For this project, we use ShadowTraffic to generate data (random quotes) to S3.

Each time a new file is written, a lambda function is triggered, and this data is copied to a landing Iceberg table using PyIceberg.
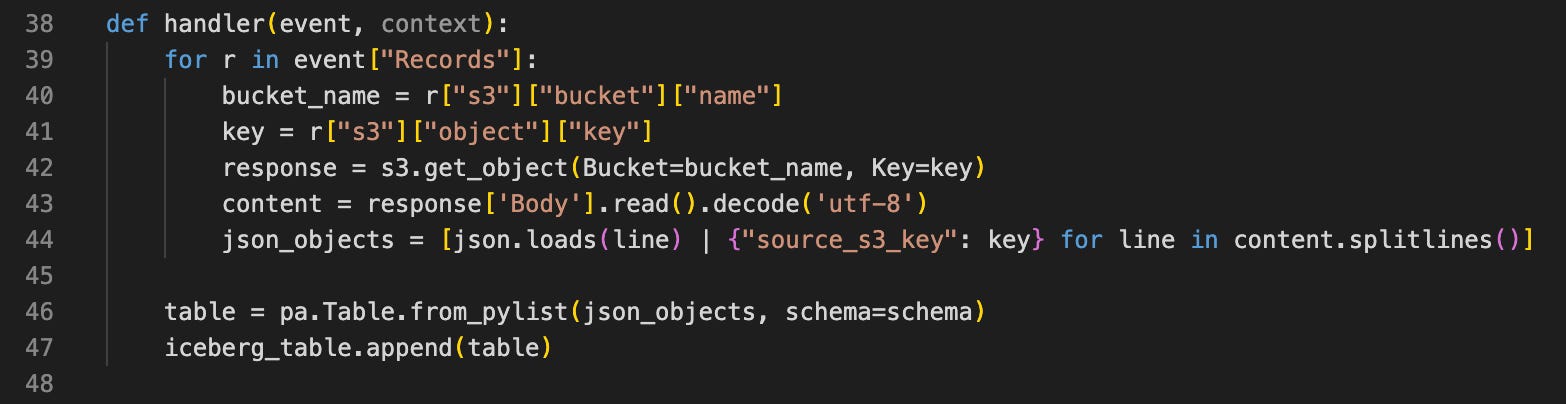
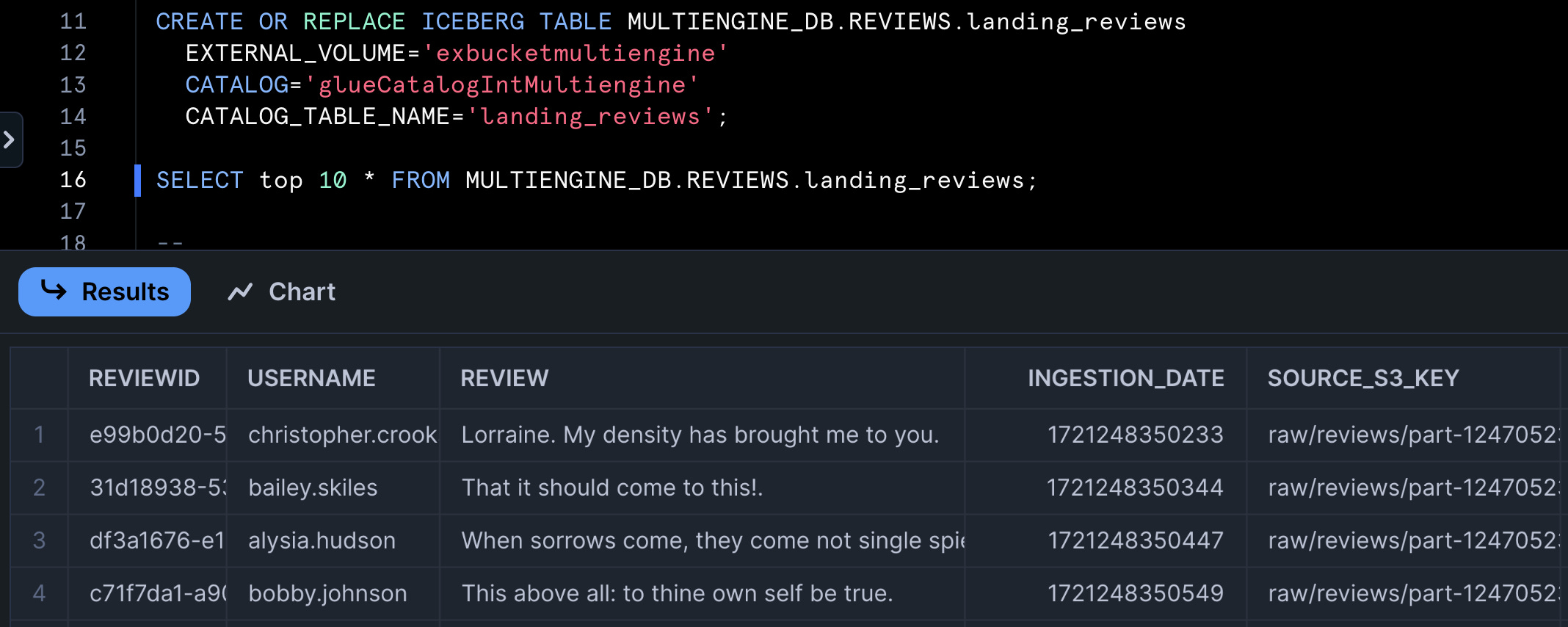
We can query this newly created Iceberg table directly with AWS Athena to verify it works as expected:

After setting up the Glue catalog integration into Snowflake, we can also query the same data directly from Snowflake (without an additional copy).
Limitations
This setup does not support schema evolution as we manually define the schema of the landing table in PyIceberg.

If the source column changes for any reason, the ingestion will be broken.
One interesting alternative would be to set up a Glue crawler that automatically scans new files written to S3 and handles the schema evolution for us.
Model 1: Clean the data with DuckDB
This first step aims to simulate some data cleaning operations using our local machine to save money.
In that case, we want to:
Deduplicate records based on
REVIEWIDTransform
INGESTION_DATEcolumn fromINTtoTimestamp.
The model will operate in FULL materialization as we want to deduplicate the complete history.

We used a Python model in SQLMesh composed of the following steps:
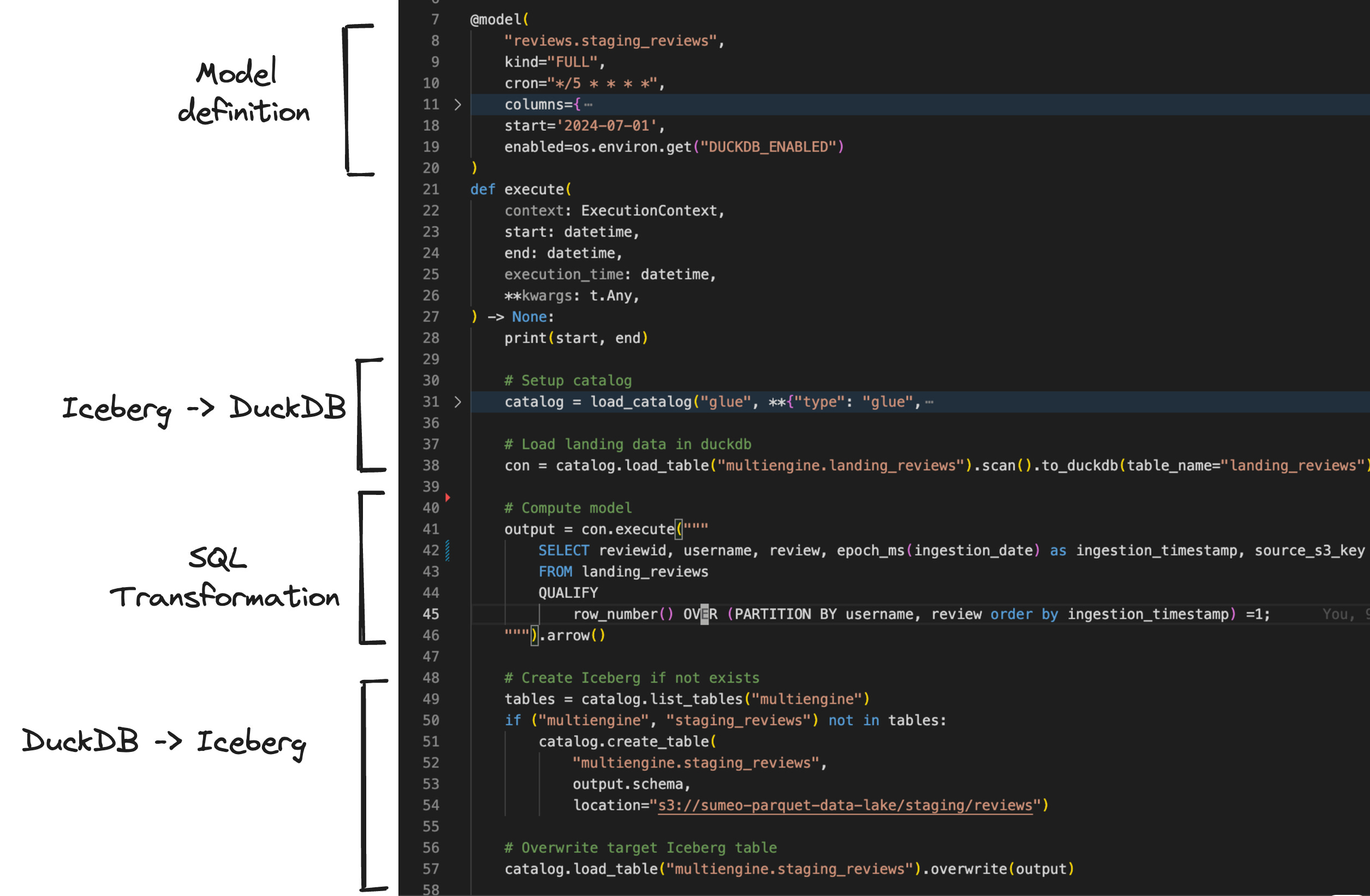
Unfortunately, we cannot use a SQL model directly in SQLMesh (trust me, we tried using a clunky post-hook written in python, and it still didn’t make sense).
We have to use a Python model to manage the interfaces to Iceberg:
Read from Iceberg
Glue Iceberg tables do not maintain aversion-hint.txtfile pointing to the latest snapshot. Therefore, if we want to use the DuckDB Iceberg extension, we first need to request the Glue API to get the key of the currentmetadata.jsonfile. In our case, we used PyIceberg to handle this task.Write to Iceberg
DuckDB does not support writing natively, so we need to use Arrow and PyIceberg.
If you think this could easily be run as a vanilla python function outside of SQLMesh: You’re right!
But what’s nice about SQLMesh is that you can add audits to run built-in data tests based on the pandas dataframe this returns.
This feature isn’t enough to proudly ship this into production, but it is nice to have tests automatically written and run on your behalf.


Limitations
Duckdb has Iceberg write limitations within the Iceberg extension and is also limited by the AWS glue catalog. This already makes Duckdb + Iceberg unfit to run in production in its current state within SQLMesh.
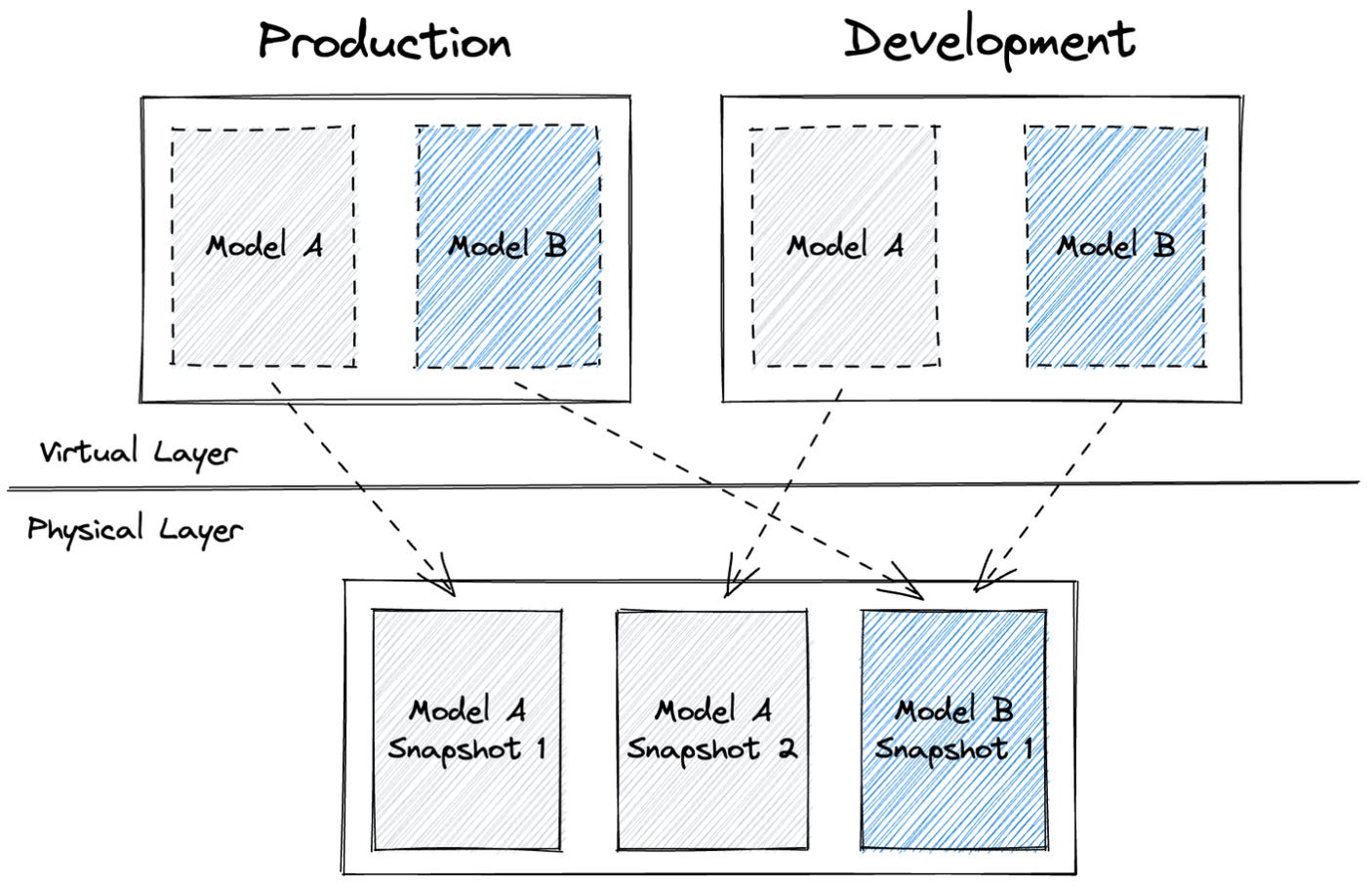
PyIceberg does not support
MERGEstatements: onlyAPPENDandOVERWRITE.Because of how we hacked together the DuckDB python model, it won’t work well with SQLMesh’s native virtual data environments. It grinds against the mechanism in that it won’t version the correct Iceberg table but, instead, the pandas dataframe that’s returned at the end of the function call. You can learn more here.

Our current DuckDB python model will not work in this mechanism because we hacked too much.
Improvements
Many improvements can not happen until engines improve Iceberg compatibility (read/write support for DuckDB and MERGE by PyIceberg).
Native SQLMesh support for Iceberg integration (create table, schema evolution).
Processing power is limited by the size of the SQLMesh machine (remote DuckDB exec is possible in Lambda/ECS, or we guess there’s Motherduck?).
Model 2: LLM transformation with Snowflake
Now that we have clean data in the staging table, the second model in our SQLMesh project will take this data and apply LLMs to the quotes to run sentiment analysis and automatically extract the author of these quotes with a simple prompt.
Snowflake provides access to LLMs via their SQL functions:COMPLETE, SENTIMENT, SUMMARIZE, etc.
Here’s what the model output looks like:

Since SQLMesh SQL models don’t support ICEBERG TABLES out-of-the-box, we need to use a Python model here again and add pre- and post-hooks.
The first pre-hook refreshes the ICEBERG table we created manually. This is because Snowflake is not aware of any new snapshots that may have appeared. This process could be automated using S3 events to trigger the S3 REFRESH command automatically, but we did not invest time in it.
We can then transform the data via SQL or, in this case, the Snowpark DataFrame API. All the commands are executed inside Snowflake; no data is exported:

If you want to know more about Snowflake AI functions, check this post:

Once the AI models have run, the next step is to write the results back to Iceberg.
Unfortunately, Snowflake does not currently support writing to an external catalog.

We had two options:
Use the Snowflake catalog to write back to Iceberg; therefore, have two catalogs.
Export the data to memory and write to the Glue catalog via PyIceberg.
SQLMesh handles incremental loads nicely, so we chose the second option: run the model only for the latest partition and export the data from Snowflake to the machine’s memory before writing it to Iceberg.
While this approach may not scale well, it should suffice for reasonable workloads, especially with an incremental load.
The solution is quite interesting because no data is persisted in Snowflake; all materialization is done in Iceberg on S3. It makes it very easy to switch to another engine if a better provider becomes available, offering improved models or lower costs.
In such a case, you would only need to rewrite your model to fit the new provider's syntax, and that's it.
Limitations
SQLMesh integration with Snowflake Iceberg tables: SQLMesh works in a first-class way with only iceberg and spark for now
No catalog can support full read/write from different engines.
Multi-engine model manipulation
We now have a mix of DuckDB and Snowflake models in our project.
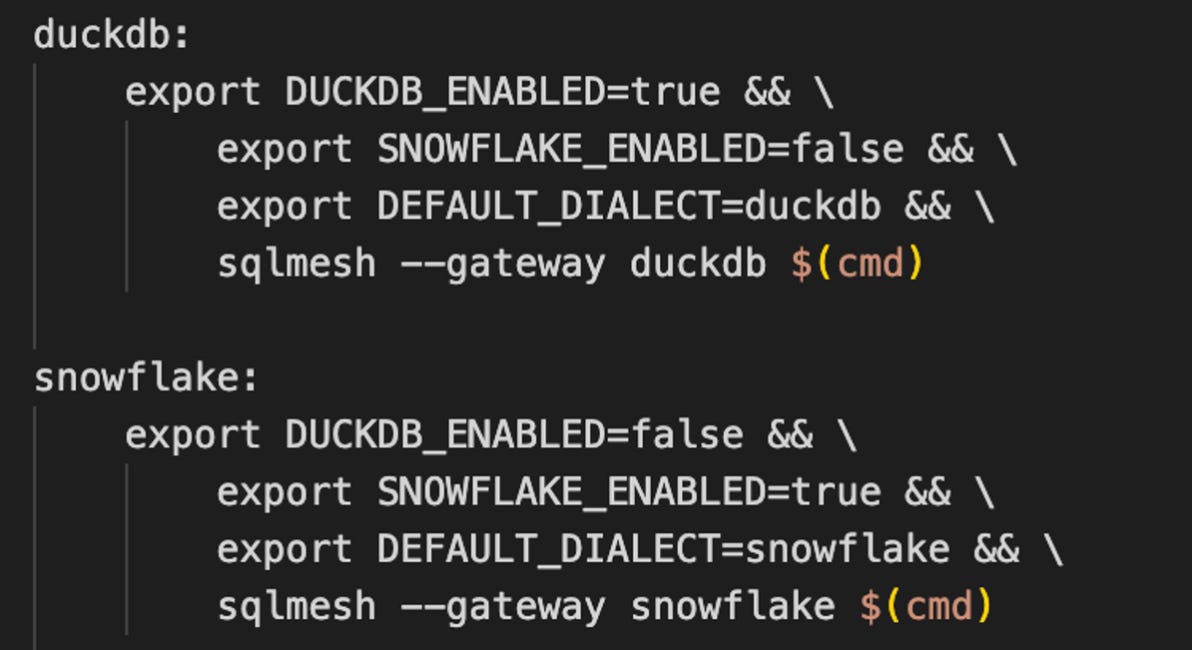
Ideally, we would like to runsqlmesh runand have it automatically determine which profile to use and where to run each model.
Unfortunately, this is not currently possible. The current solution is to leverage theenabledproperty for a model, which allows us to select only the relevant models depending on the chosen profile. For example, thesqlmesh —gateway duckdb runcommand would only run all the DuckDB models in our project.
To achieve this, we need to use a macro that dynamically setsenabledto true or false, depending on the gateway. However, SQLMesh Python models do not support macros for theenabledproperty.
Therefore, we had to use environment variablesSNOWFLAKE_ENABLEDorDUCKDB_ENABLEDto alternately activate each side of the pipeline. We even create a Makefile to automate this process.
When you start building a wrapper above a wrapper… ^^ This approach works well for two models but becomes unmanageable for real-life projects where the number of models easily exceeds 100.
Moreover, what happens if we have a workflow that alternates between engines, such as DuckDB → Snowflake → DuckDB? In that case, would we need to create selectors like duckdb1 duckdb2?
Lineage
A crucial aspect of a multi-engine stack is preserving lineage across engines.
This was not possible in dbt. But with SQLMesh and its Python models, it appears to manage it effectively.

The only piece of the lineage missing is the ingestion lambda. As a transformation tool, it is not possible to reference this type of remote execution model with the current version of SQLMesh.
Wrap-up
When we completed this exercise, it finally clicked for us why multiengine workflows are still a theory rather than a production reality.
As you read above, there’s too much friction and clunkiness.
Multiengine workflows should feel like elegant baton passes.
Right now, they feel like playing volcanic hot potato.
But we hope in all this that we accomplished a couple of things:
We now know specifically what’s holding multiengine workflows back from their full potential, and we hope you saved precious hours from researching this on your own.
The Iceberg catalog ecosystem still needs to mature a lot more.
SQL transformation frameworks need to support models that operate natively across various systems, SQLMesh, DBT, or whoever.
We had a lot of fun together (I guess that’s something just for us.)
Sung & Ju

I would be grateful if you could help me to improve this newsletter. Don’t hesitate to share with me what you liked/disliked and the topic you would like to be tackled.
P.S. You can reply to this email; it will get to me.
 | A guest post by
|
I am seeing this a lot - great feedback
As of today this remains too much to save a few bucks. I’ve found a better use of duckdb in sqlmesh is to leverage it for fast local development, but leave production work to your main engine.