
Master Data Management: the missing piece of the Modern Data Stack ?
Ju Data Engineering Weekly - Ep 55

dbt has made data quality errors easily detectable.
But how do we remedy them?
This week, I came across an interesting topic: Master Data Management (MDM).
MDM may sound like something only big companies use, but it solves a common problem: keeping accurate gold records of customers, clients, or products.
This implies two things: being able to detect data quality deviations and being able to remediate them.
While the first one is straightforward, the second one is where the problem gets interesting.
In this week's post, I'll explore this MDM segment and examine how it can be integrated with other tools in the modern data stack.
1- What’s MDM?
The main purpose of Master Data Management (MDM) is to have a single reliable source of data.
This is especially useful when various systems are creating information about the same things, such as customers, businesses, and products.
Each system usually operates within its context, resulting in the generation of duplicate records.
For example, customer records in order entry, shipping, and customer service systems may vary because of differences in names, addresses, and other details.
MDM tackles this issue by establishing procedures (both manual and automatic) to fix wrong or duplicated records.
MDM systems fall into two main categories:
Analytical MDM: feeds data warehouses and other analytics systems.
Operational MDM: synchronizes master data across core business systems.
In this article, I specifically concentrate on analytical MDM.
2- MDM landscape
If you google MDM, you will get pages filled with vendors offering solutions.
This field has been around for a while and has expanded along with the data warehouse industry.
As a result, many solutions available in the market are large-scale software offerings designed for corporate use, including Informatica, SAP, IBM, and others.

While traditional MDM tools can be powerful, I haven't encountered any that seamlessly integrate with modern data tools like dbt.
The nearest category in today's data landscape that I found is "Data Quality & Observability."
However, these vendors mainly focus on detecting data quality issues, not on how to fix them.

3- MDM and the Modern Data Stack
An integrated reconciliation system would include the following modules:
Identifying data quality errors
Automatically correcting some errors/duplicates
Enabling manual correction of the remaining one through an interface
Tools like dbt or SQLMesh provide a strong foundation for the initial phase: they make it easy to add a data testing layer to your SQL models.
Moreover, you can integrate tools like Elementary or dbt expectations to write more advanced tests.

Spotting errors is crucial, but just finding them isn't enough; they also need to be resolved.
A good initial step might be to make use of dbt's features:
fix data quality errors via SQL models
inject missing mappings via dbt seeds
However, this approach will hardly scale for more complex use cases.
Automatic Entity Resolution
One of these more complex use cases is entity resolution which aims to identify duplicate data records across multiple sources.
This is a longstanding problem with numerous software solutions available.
One interesting tool that I found is Zingg.
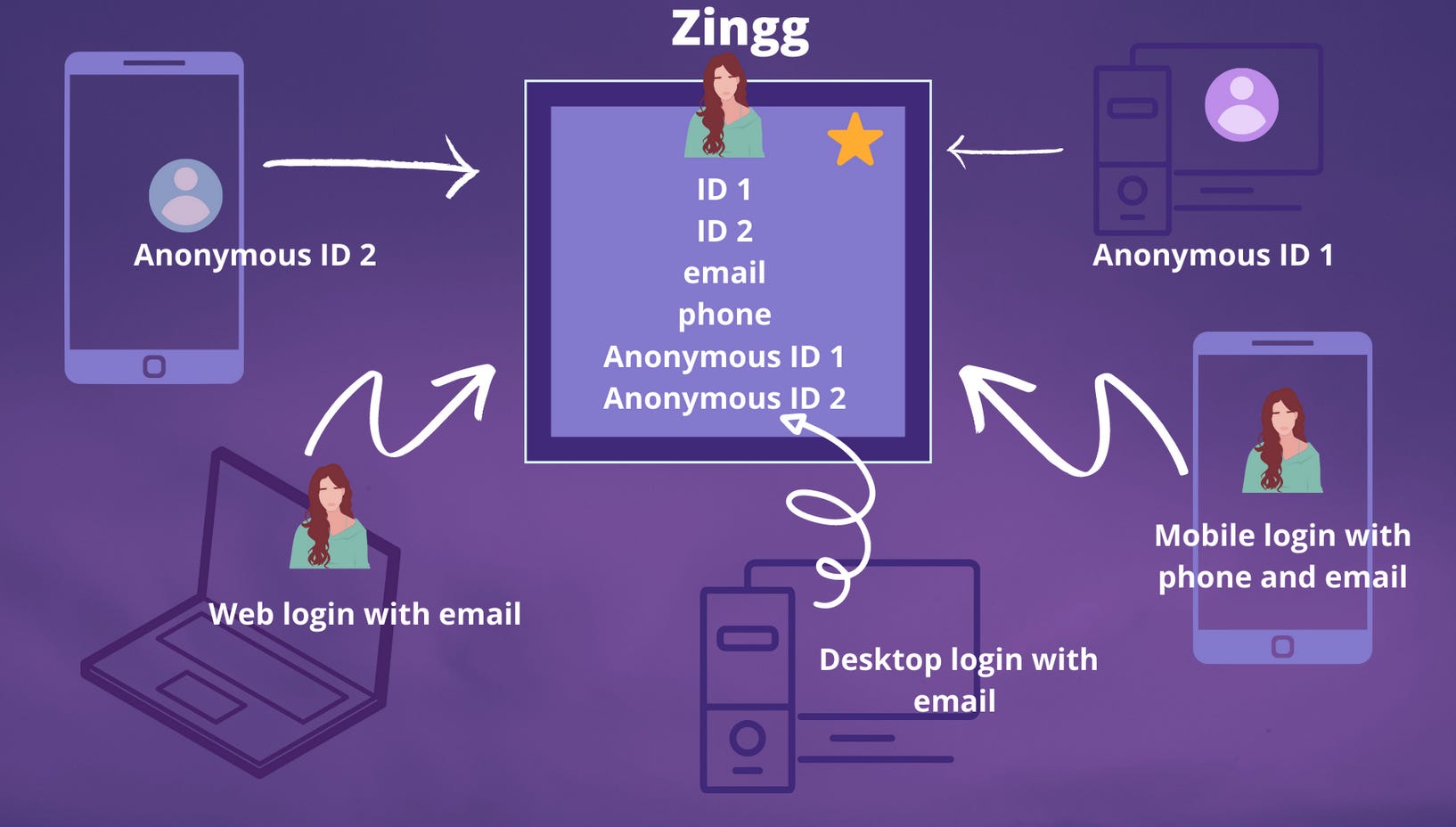
They tackle the issue by segmenting records into blocks and comparing them through fuzzy matching techniques.
They also allow for the fine-tuning of ML models with manually labeled records.
Remarkably, it's open-source and can be installed via pip, facilitating its integration into a DAG using Python models.
Manual Resolutions
In addition to automatic error resolution using various tools, human intervention is likely necessary in many cases.
Data quality fixes often demand a deep understanding of business operations, which engineers may lack.
For that reason, they should be carried out by less technical users, or "data stewards," within a secure and user-friendly environment.

That's why I believe the crucial component missing in today's data tool landscape is a CRUD interface for warehouse tables.
This interface should enable:
Editing, merging, and deleting records
Viewing previous versions of records
with an integrated audit trail and proper user management.
Nothing rocket science but cumbersome to build if you have to DIY.
Snowflake and its marketplace offer a good platform for distributing such a product.

I actually found some apps in the marketplace but they are all very limited and only offer basic editing based on Streamlit Dataframe Editor.


I'm surprised by the lack of easy and readily available solutions for this data quality resolution issue.
Just as every category in the data stack has experienced a "modern" transformation, I expected this area to undergo a similar evolution.
I'm really interested in how people are addressing this issue currently.
Please feel free to share your experiences and solutions by leaving a comment on this post!
Thanks for reading,
-Ju

I would be grateful if you could help me to improve this newsletter. Don’t hesitate to share with me what you liked/disliked and the topic you would like to be tackled.
P.S. You can reply to this email; it will get to me.
Thanks so much for sharing!