
Parquet & AI = 🙅♂️⛔️?
Ju Data Engineering Weekly - Ep 65

In every data engineer's mind, storing data = Parquet.
I want to build a data lake 👉 Parquet
I want to dump data from a database 👉 Parquet
I want to load data into my warehouse 👉Parquet
I want a new design for my living room 👉 … 🫣
Parquet is the standard storage format for tabular data in analytics workflows.
However, one day, your data scientist colleague might come to you with a question like this:
"We have this new AI project. I have gathered videos, images, and raw text that I want to store in a data lake: 👉 Parquet ?? "
Let's explore how Parquet works under the hood and whether it can accommodate this kind of use case.
How does Parquet work?
Parquet is a hybrid file format combining row-based and column-based data storage aspects.
What exactly does that mean?
A row-based format (like CSV) stores records consecutively, one row after another.
The file is a sequence of bytes, with each record following the previous one.
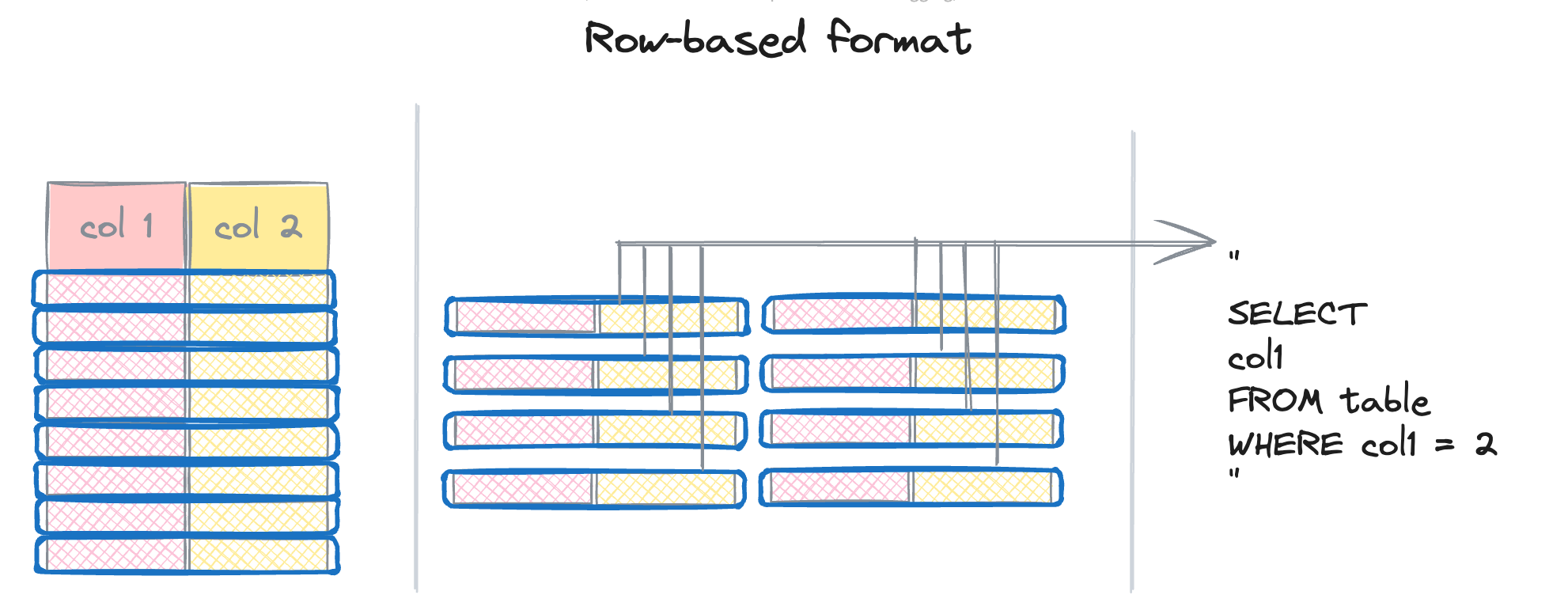
The main issue with row-based formats is that you frequently need to read entire rows, even if you only require data from a few columns.
In the query on the image, only col1 is used, but the engine must read all the columns.
On the other hand, in a column-based format, data are stored in columns rather than in rows.

One advantage of this approach is that the engine only needs to access the specific bytes of a column to perform operations on it.
However, when writing data, to add a new column, the engine must first store the entire column in memory before it can write it out.
Parquet addresses this by combining column-based and row-based formats.
Data is stored in a column-based format, but records are grouped into so-called row-groups.
Row groups bundle chunks of columns together.
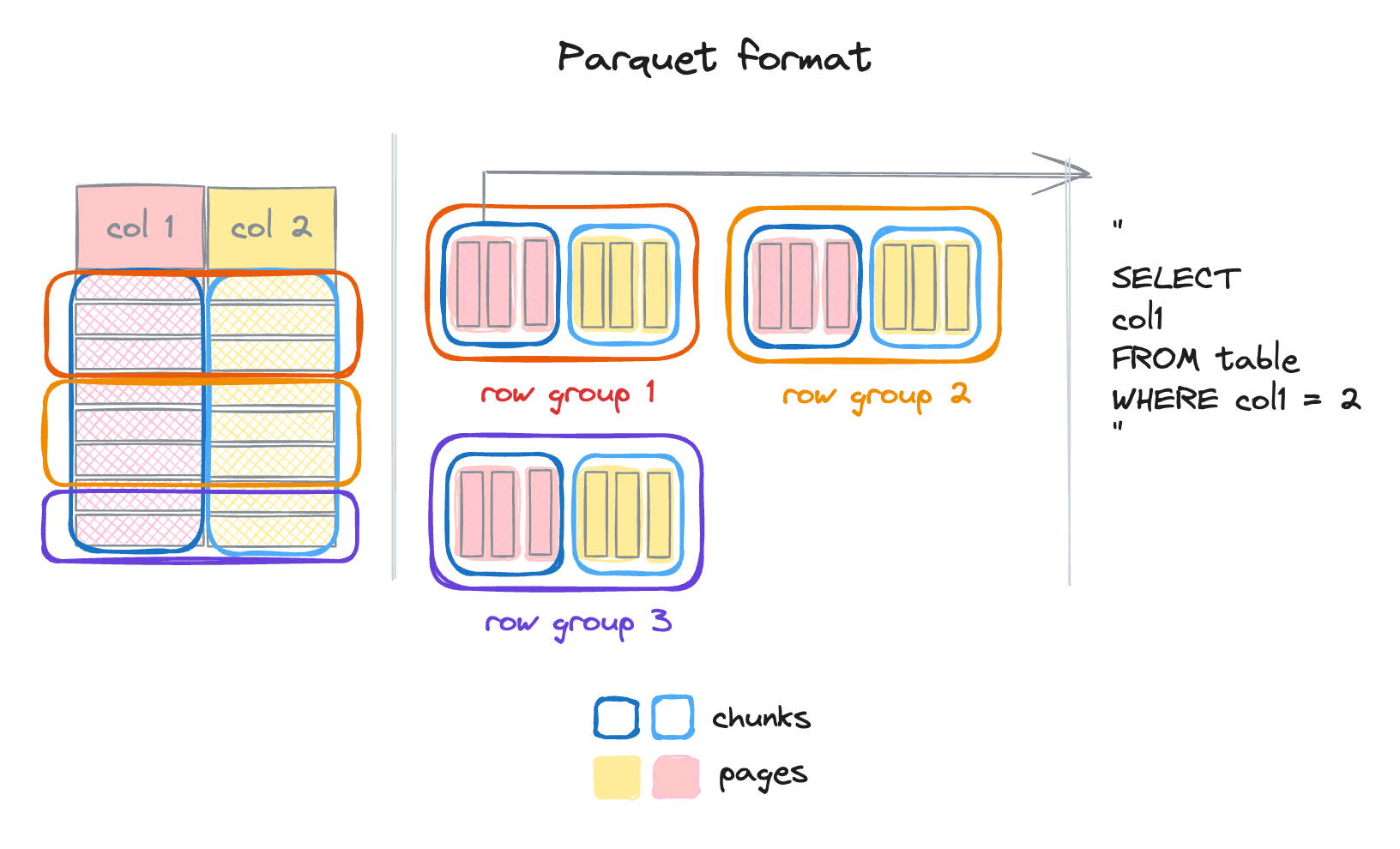
Row groups and chunks contain statistics (e.g. min max values) about the underlying data.
The engine uses these statistics to skip parts of the file, thereby reducing the amount of data it needs to scan to perform a query.
Chunks are further divided into units called pages, which are the base for encoding and compression.
Parquet can compress data using GZIP, Snappy, and LZO formats.
It also supports encoding techniques that minimize the size of the stored data, such as dictionary encoding and run-length encoding (RLE).

AI & Parquet
AI algorithms mainly rely on unstructured data such as text, images, videos, and sounds, which are typically stored in large blobs.
However, Parquet's design presents challenges for handling this type of data.
In a pure column-based format, each column operates independently of the others.
If one column contains a large amount of data, it shouldn't affect the performance or storage of the other columns.
But the parquet has row groups…
Point Lookups
A point lookup is a query that accesses a small subset of rows.
In AI, you often run this kind of operation when searching documents for example (semantic search).
In Parquet, reading data means opening an entire page and, thus, several rows.
If one column is large, you must open and process a lot of data just to retrieve a few rows.
Wide Columns
Designing an appropriate row group size can be challenging if a column is large.
If the size is too small, a single-row group will contain only a few rows, which makes read operations inefficient.
On the other hand, if the size is too large, writing becomes memory intensive. When a row group is written, the entire row group needs to be stored in memory.
More about this here.
AI optimized format: Lance
One traditional option for handling large files is to store only the pointer to this file in the dataset.
This works well but can get cumbersome to manage and limit write/read performance. What if we could manage images, metadata, and annotations everything in one place?
Lance v2 is a format created by LanceDB, a database designed for AI workloads.
It’s column-based and eliminates the row groups concept from Parquet.
It consists solely of data pages and column metadata.
The pages are written continuously: when a column writer has accumulated enough data, it writes it.
Column metadata stores statistics about each page, which the engine uses to select only the relevant pages.

By eliminating row groups, each column exists independently of the others:
The page size is specific to each column. Depending on the column's format, various page sizes can be defined.
Column metadata are independent: reading a single column without accessing any metadata from other columns is possible.
Encoding is specific to each individual page: you can pick the best one depending on the data format.
This removes Parquet's main issue, which is that large columns impact others through row groups during writing and reading operations.
However, there is no free lunch; this approach risks storing data non-sequentially, which could increase the number of read operations (more on this topic here).
Lance’s CEO gave an interesting talk at the last data council, exposing his vision for Lance.
They want to replace Parquet and become the defacto format for powering:
the complete AI lifecycle—from training to serving
various query engines (multi-engine data stack)
multi-modal dataset

Meta has recently introduced as well a new file format called Nimble that serves the same purpose:
Nimble (formerly known as “Alpha”) is a new columnar file format for large datasets created by Meta. Nimble is meant to be a replacement for file formats such as Apache Parquet and ORC.
These formats are still in their early days and have much of their roadmap.
As a data engineer, monitoring this area closely is worthwhile, as we will likely encounter more and more of these types of multi-modal use cases in the future.
-Ju

I would be grateful if you could help me to improve this newsletter. Don’t hesitate to share with me what you liked/disliked and the topic you would like to be tackled.
P.S. You can reply to this email; it will get to me.
Hi Julien super read!
May i know which tool you use for the designs
I am myself a blogger, will be grateful !
Do you mention nimble and lance for AI use case in general or because your use case is primary indexing video/audio/image content for a wider AI project (but it could have been something else) ?
I’m not very clear on this, could you precise ?