

Streaming databases: Use Cases and Benefits
Streaming databases: Use Cases and Benefits
Ju Data Engineering Weekly - Ep 49

Yingjun, the CEO of Risingwave, contacted me in December after reading a blog post I published on developing data backends for embedded analytics.

During our conversation, we discussed the current trends in the data industry, his experiences at AWS working on Redshift, and the insights he's gained from creating data infrastructure products. After our talk, he offered to support my content very generously.
I've wanted to write for a long time about streaming databases, and this sponsorship provides the perfect opportunity to do so.
This post is designed to introduce streaming databases from the perspective of data platform design.
It will discuss the appropriate scenarios for their use and explain how they can be integrated into a data stack.
Note: While this post is sponsored, there have been no changes to the content or influence on the editorial direction.
Streaming Databases
In the past, streaming technologies were split into two categories: stateful stream processors and streaming databases.
Stateful stream processors are made to handle complex data transformations, whereas streaming databases are designed for ad-hoc data requests.
Now, new platforms like Materialize, RisingWave, DeltaStream are emerging.
They combine stream processing and streaming databases into cloud-native solutions with an SQL interface.
Sources and Sinks
These databases can connect to various sources:
Event streams (e.g., Kafka, AWS Kinesis, Repandas)
Database Change Data Capture (CDC)
Batch files
and transform and deliver records to various destinations such as:
Databases (Postgres), Warehouses (Snowflake, Bigquery)
New event streams
Files, Open Table Format (Iceberg, Hudi, Delta)
Record Transformation and State management
State management is the source of complexity in streaming databases.
Transformations can be categorized into two types: stateless and stateful.

Stateful transformation requires recalling information from past events to modify a record while stateless can process each record independently.
Examples of stateful SQL transformations: DISTINCT, TOP, JOIN
Examples of stateless transformations: WHERE, CASE WHEN.
Streaming databases manage stateful transformations by generating checkpoints, which preserve the system's state at set intervals.

Merging this state with the current record in the system, users can perform distributed joins and aggregations to combine data from various streams.
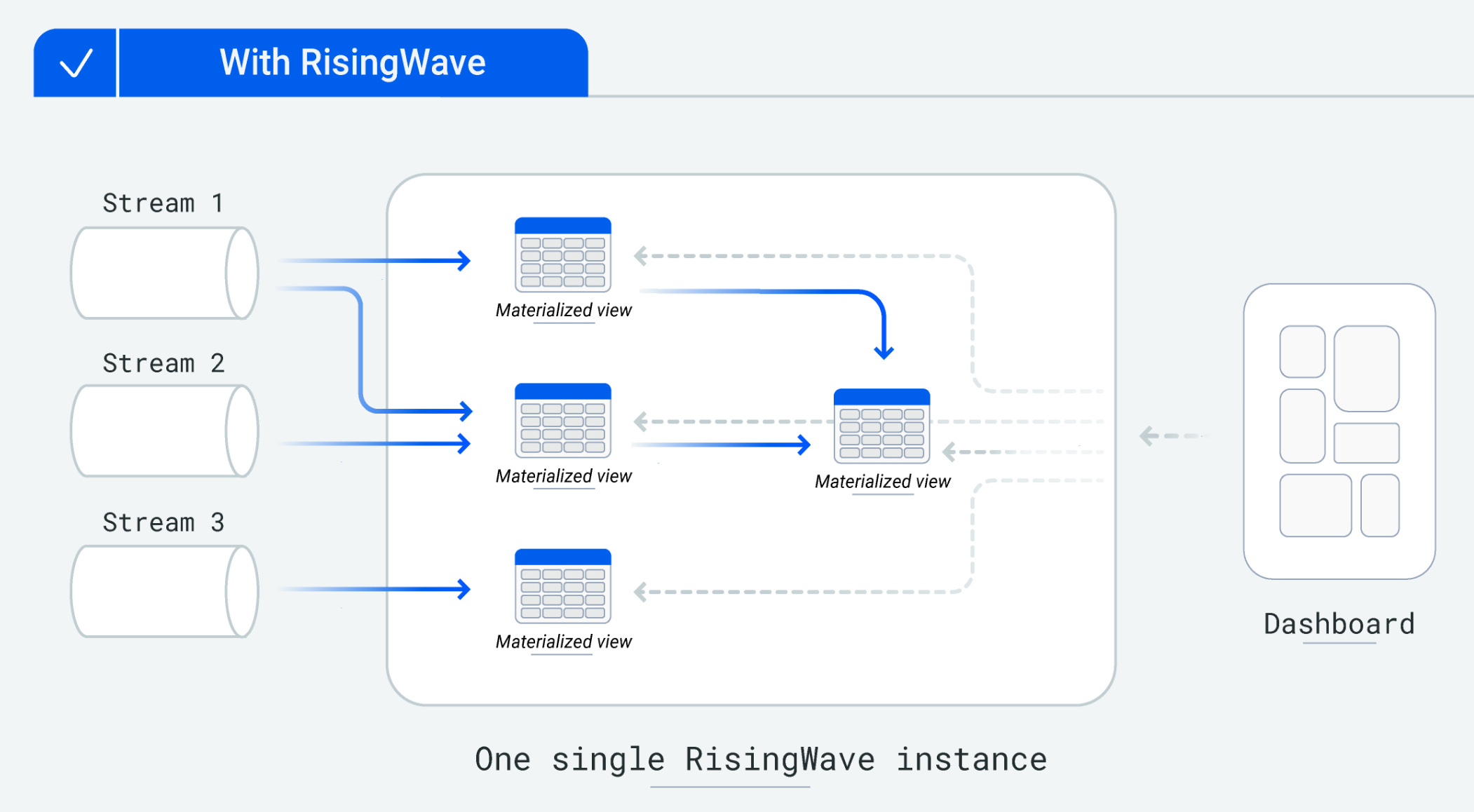
Streaming Use Cases
Streaming processing excels in scalability for stateless transformations: simply add more workers to process additional records.
However, streaming may not suit scenarios requiring stateful consistency across numerous records.
BI is a good example where the need for real-time data may be compromised in favor of a stronger analytics layer that guarantees global data consistency through batch operations.
In scenarios where real-time data freshness is not the primary concern, batch processing is likely to be more cost-effective and simpler to develop and maintain.
Based on my experience, I have seen streaming databases to be particularly effective in three scenarios:
User Facing Apps
Perfect for products requiring immediate reactions to particular sequences of events within a defined time frame: session-based ad predictions, real-time product recommendations, and consumption dashboard.
In all these use cases, the outputs are derived from metrics that need to be computed in real-time and it’s where streaming databases bring added value.
Alerting (real-time analytics)
In scenarios where immediate notification of system issues is critical, the freshness of data is essential. Streaming databases are useful here to compute complex alerting metrics. If you've had experience with AWS Cloudwatch alarms, you might have noticed how cumbersome this can be..
Data ingestion layer of a data platform
I am very excited about this last use case.
In last week's post, I detailed how streaming technology can be integrated into a data platform by drawing parallels with car manufacturing systems.

From my perspective, a very good trade-off between scalability and latency can be found by mixing a push pattern for data integration (event-based) and a pull pattern for data read (batch-based).
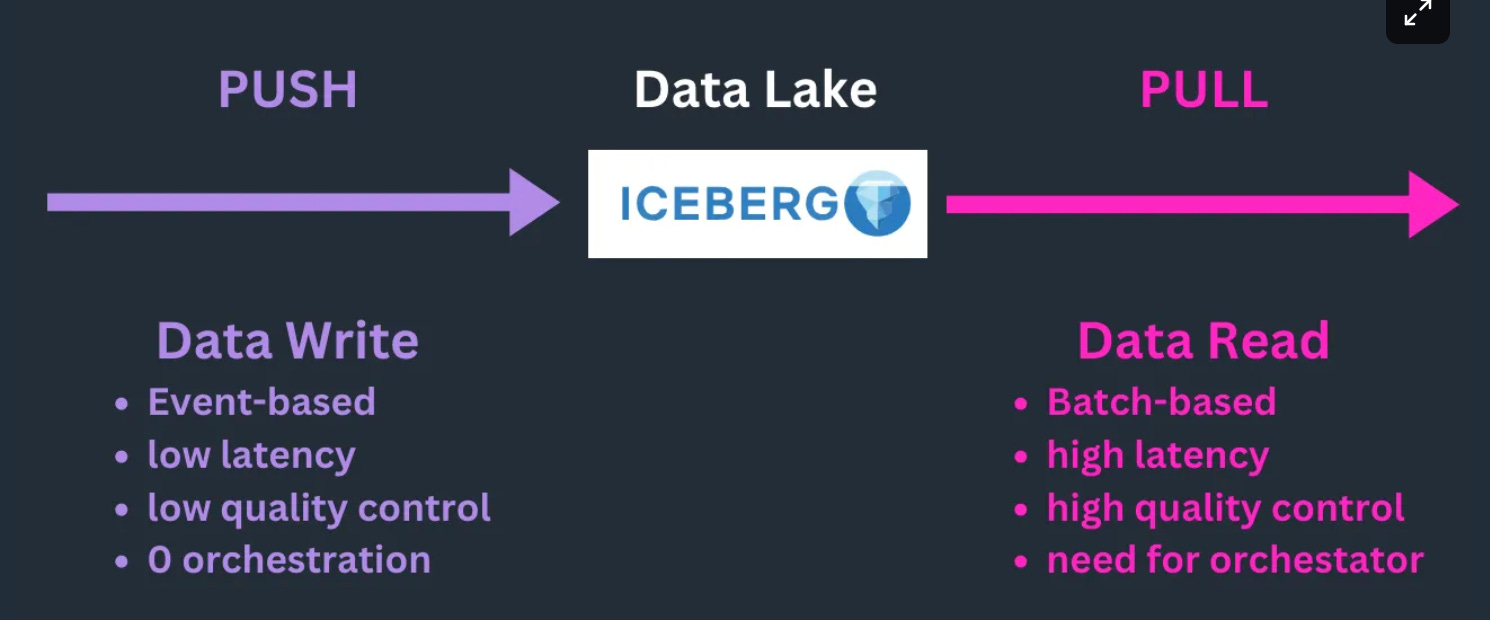
Traditionally, I've built event-driven data integrations using serverless technologies like Lambda, Fargate, SQS, and DynamoDB for state management.
However, it has recently occurred to me that streaming databases effectively offer all these components in a single box.
Additionally, their stateful processing features can be very useful in tackling tricky challenges:
Handling "late arrivals": Ensuring that sequences of records are processed in the correct order (article of Netflix on this topic).
Efficient S3 file batching: Organizing data in a manner that aligns with your query patterns to make data retrieval more efficient.
Deep Dive: Real-time Data Products
In a previous post, David Krevitt and I set out to build the simplest possible data backend: sinking the output of a data pipeline (hybrid streaming/batch) to a Postgres application database, to feed a React dashboard.

To be as meta as possible, we chose to build a consumption monitoring dashboard for a cloud data product. On it, a user could view live usage, in terms of queries executed, compute runtime, and more.
Metrics are linked to Postgres via RisingWave, with changes in Postgres subscribed to by the frontend app for “streaming” updates.
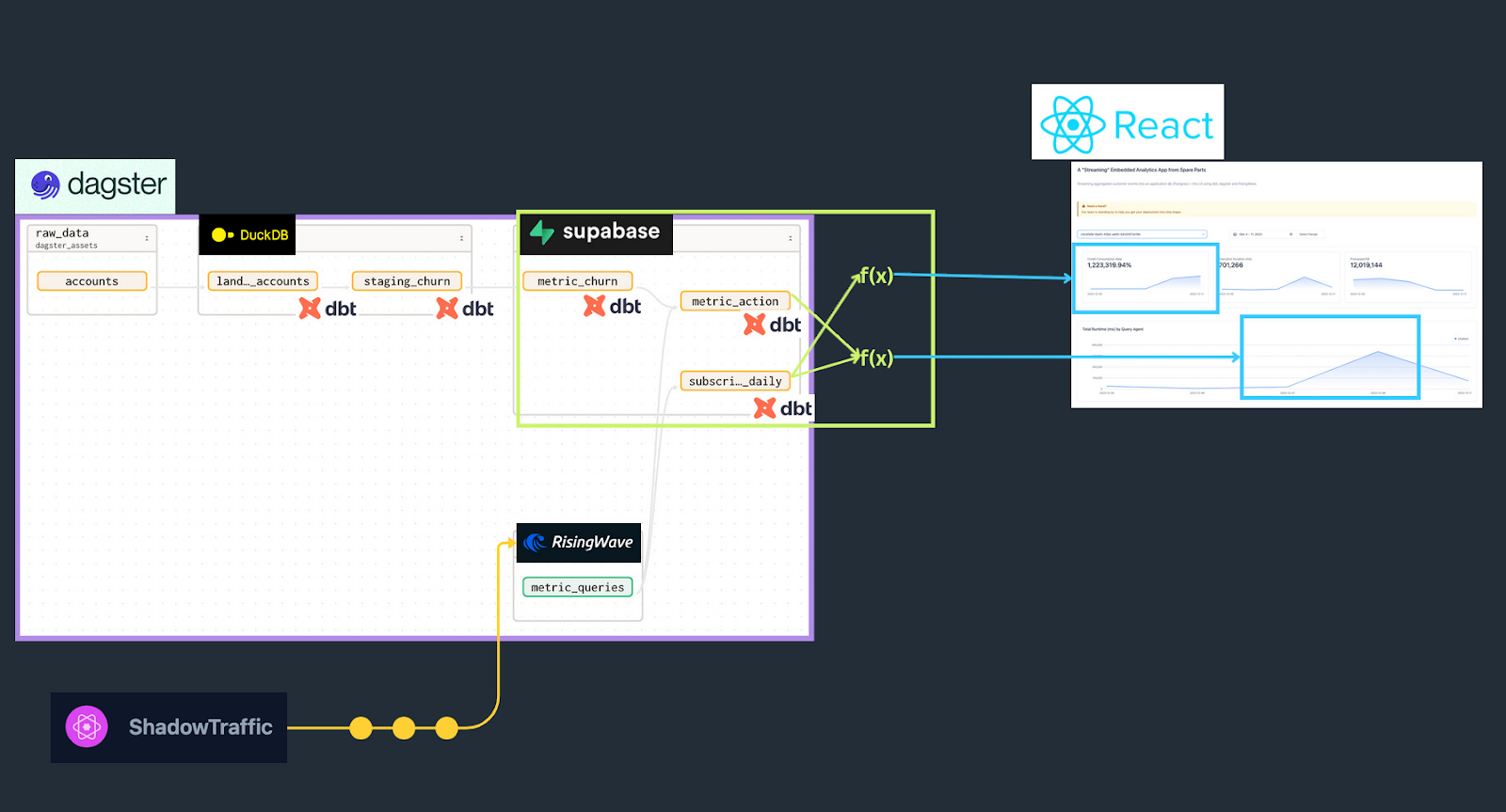
It was interesting to see how easily the streaming system could be integrated with other tools in our setup.
Indeed, RisingWave provides integration with dbt, allowing the materialized views model to be integrated directly into the global lineage DAG:
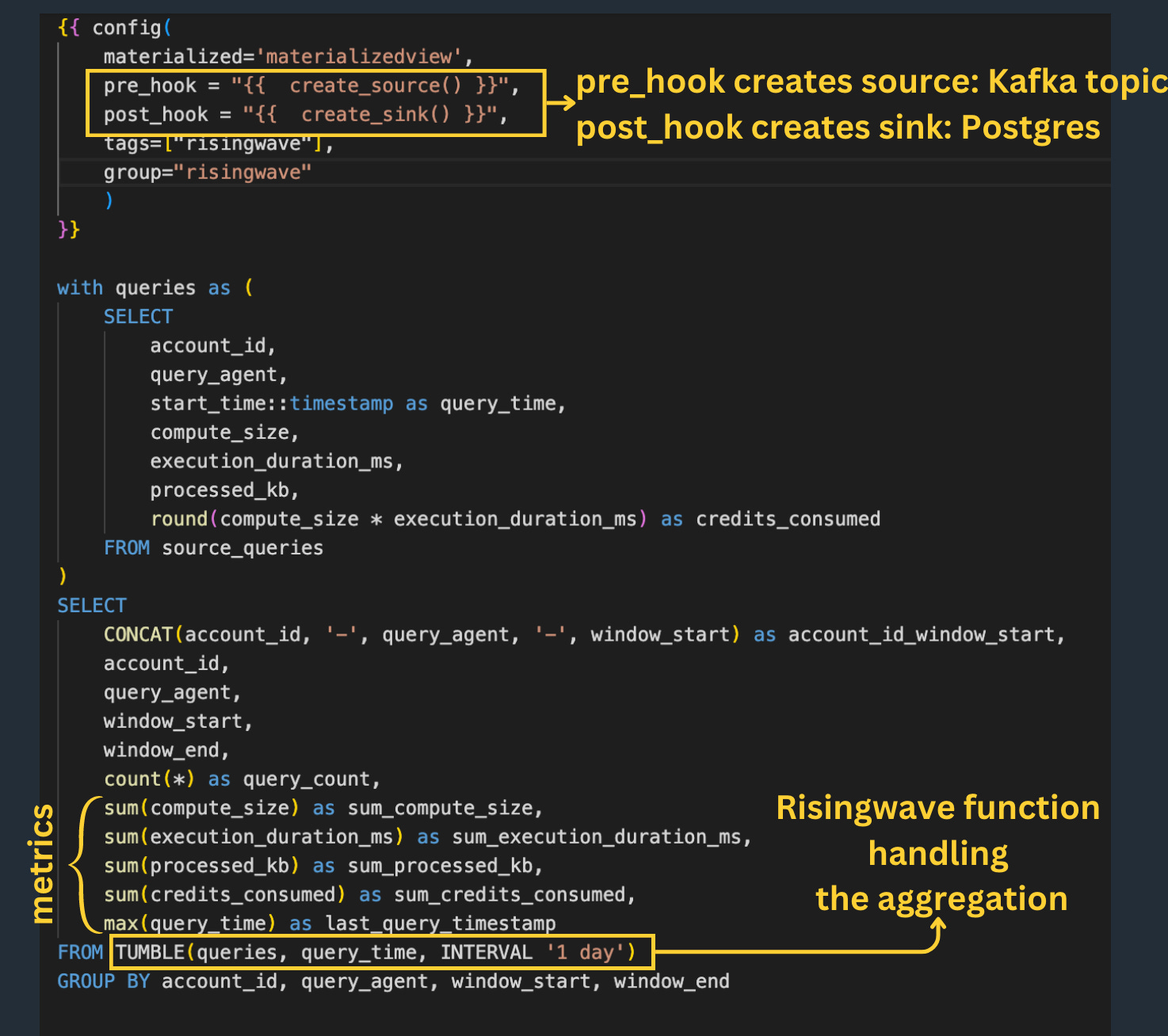
The model is executed only once at the initiation of the view and not again afterward.
This highlights another advantage of streaming-based systems: no need for orchestration, records naturally "flow" through the processing steps.
I liked as well the SQL functions like TUMBLE() or HOP() that make the manipulation of time windows straightforward (contiguous/scheduled time intervals).
This example illustrates how modern streaming databases facilitate the integration of streaming capabilities into a data platform.
They are significantly reducing the entry barrier to streaming technology by offering an easy cloud-native setup and an intuitive SQL-based experience.
I see them initially gaining market share in peripheral systems (such as alerting and monitoring) and gradually taking on more core workflows like embedded analytics or data ingestion.
Thanks for reading and thanks RisingWave for supporting this newsletter edition.
-Ju

I would be grateful if you could help me to improve this newsletter. Don’t hesitate to share with me what you liked/disliked and the topic you would like to be tackled.
P.S. you can reply to this email; it will get to me.