
Virtual Data Environments
Ju Data Engineering Weekly - Ep 62

PROD-CTLQ-DEV is a legacy from software engineering.
In data engineering, the data shapes the code, not the other way around.
This is why development environments with sampled or synthesized data are nearly useless in this context.
However, fully replicating data across environments is not the solution either.
Fortunately, the separation of computation and storage offered by many modern data infrastructure tools enables us to design smarter development processes based on virtual data environments.
Let's explore this.
1- Virtual Environment & Data Warehouses
One significant disruption offered by cloud warehouses is the separation of storage and compute.
This separation creates opportunities, such as duplicating tables, schemas, or databases without replicating data.
This feature, called zero-copy cloning, produces shallow clones by duplicating only the metadata pointing to the physical files:
-- BigQuery
CREATE TABLE
myproject.myDataset_backup.myTableClone
CLONE myproject.myDataset.myTable;
-- Databricks
CREATE TABLE [IF NOT EXISTS] table_name
[SHALLOW | DEEP] CLONE source_table_name [TBLPROPERTIES clause] [LOCATION path]
-- Snowflake
CREATE [ OR REPLACE ] { DATABASE | SCHEMA } [ IF NOT EXISTS ] <object_name>
CLONE <source_object_name>
[ { AT | BEFORE } ( { TIMESTAMP => <timestamp> | OFFSET => <time_difference> | STATEMENT => <id> } ) ]
[ IGNORE TABLES WITH INSUFFICIENT DATA RETENTION ]
They are replicas of a source table at a specific point in time and behave as separate tables, each with its own history. Changes made to clones affect only the clones, not the source. Additionally, changes to the source during or after the cloning do not affect the clone.
Creating a clone transforms the development process. Instead of maintaining separate instances of a warehouse and copying data across prod/ctlq/dev environments, there is just one account with one production database.
When a developer begins a new branch, a zero-copy clone of the database is created, allowing them to experiment freely with actual production data.
Once the branch is merged, the changes are applied to the production database, and the clone is deleted.
This makes the developments super efficient and the deployment safer because the code has been already tested on prod data.

2- Virtual Environment & Data Lakes
Similar to how we have only one account with 1 DB + clones for the data warehouses, the same new process is coming to the data lake.
Traditionally, a data lake is simply a collection of hive-partitioned files. The only metadata produced is then self-contained within the file path.
Iceberg and other open table formats now offer an additional metadata layer previously missing, enabling the creation of a virtual copy of a table.
When used with Nessie, Iceberg allows for the isolation of changes made to several tables into a so-called branch:
--Create new branch from the main
nessie branch dev_branchThis gives us a workflow similar to that of the warehouse, where development is done on a virtual copy of the data within the same environment.

3- Virtual Environment & Data Transformation Frameworks
We've discussed how virtual environments can be created in both data warehouses and data lakes.
Another angle to consider is viewing the issue through the lens of data transformation frameworks, rather than data infrastructure alone.
Frameworks like dbt or SQLMesh incorporate the concept of a virtual data environment.
dbt
dbt features a clone command that allows for the duplication of all objects from one schema to another. It uses a zero-copy clone of the object, or, if not supported by the platform, creates simple views using 'SELECT *'.
# clone all of my models from specified state to my target schema(s)
dbt clone --state path/to/artifacts
This approach requires users to recompute many models across different environments, which can be cumbersome.
To address these challenges, dbt allows running only the models affected by a change (defer). This method is effective on a small scale but can reach some limits with larger projects.
SQLMesh
SQLMesh appears to have thought about this concept of a virtual environment from the ground up.
They create systematically SELECT * "pointer" views on top of each model for each environment.
All interactions with the data are then done via these views and each environment has its own set of views pointing to the same physical tables.

If a developer needs to modify the model A, a new snapshot of this model will be created.

Initially, only the model A view in the development environment will be altered to point to this new snapshot.
When deploying to prod, the view corresponding to model A will shift to pointing directly at the most recent snapshot.
The elegance of this model is that it requires no additional computations upon deployment, as these have already been carried out in the dev environment.
We are now in a situation where we can safely create virtual environments for a data lake and a data warehouse in a prod account directly.

4- Virtual Environment & Cloud Services
Consider, for instance, a Lambda function that ingests data from an API into a data lake.
How would the development process for this look when working with virtual data environments?
If we want to take this route, the only viable method would be to separate the application and infrastructure deployments.
If the Lambda function operates using Docker, the application side of the deployment would be responsible for building the code and pushing the image to the registry.
In contrast, the infrastructure side handles all other aspects, including triggers, IAM permissions, concurrency, timeouts, and memory limits.
Usually, both infrastructure and applications are deployed simultaneously and follow the same lifecycle.
However here, they need to have separate development processes.
While the infrastructure side adheres to a traditional development process dev→ctlq→prod, the application side simply duplicates cloud resources within the prod account.
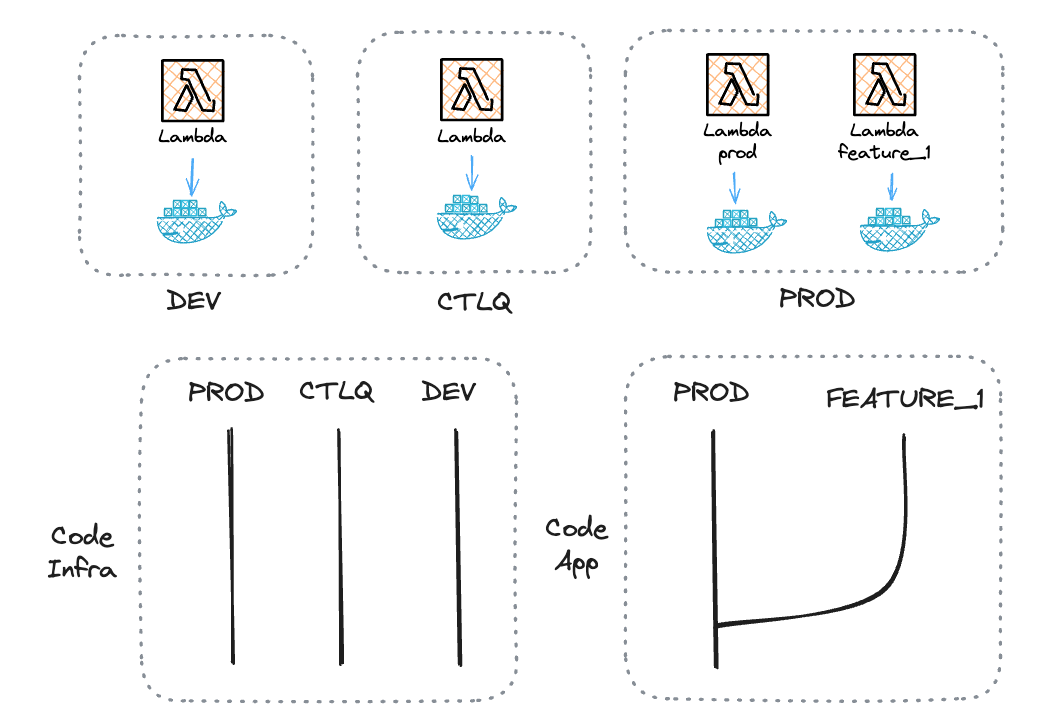
For instance, the 'feature_1' branch would create a copy of the Lambda function prefixed with 'feature_1'. This copy would then interact directly with the virtual data environment of the data lake or warehouse, ensuring complete isolation.
This concept, known as 'stage,' is already implemented in many Infrastructure as Code (IaC) frameworks.
For instance, with the Serverless framework, you can specify a stage, and all resources will automatically be prefixed with the environment's name:
serverless deploy --stage devBy leveraging these stages, we can create a fully virtual environment within the production account and easily test the lambda function on prod data.
Thanks for reading,
-Ju

I would be grateful if you could help me to improve this newsletter. Don’t hesitate to share with me what you liked/disliked and the topic you would like to be tackled.
P.S. You can reply to this email; it will get to me.
This would bring so much ease to devops with tranditional databases like pg. I looked, there doesn't seem to be an equivilant. Maybe it's possible to use sqlmesh but I don't think it would be ideal.
The concept of branching a database like you branch your code is great. I really enjoyed working with this tool for that - https://planetscale.com/