


Bonjour!
I'm Julien, freelance data engineer based in Geneva 🇨🇭.
Every week, I research and share ideas about the data engineering craft.
Not subscribed yet?

The tech ecosystem has always been a succession of waves:
AWS is the new mainframe
Snowflake is the new Oracle (founded by ex-Oracle)
DuckDB is the new pandas (founded by ex-BigQuery)
As a result, companies’ roadmaps have often turned into an endless series of migrations.
While migrations aren’t inherently wrong—tools evolve, and businesses need to adapt to stay competitive—the real issue lies in their complexity and cost.
The goal isn’t to avoid lock-in at all costs, as being entirely free from it is somewhat unrealistic. Instead, the focus is on understanding the risks of choosing a provider and finding ways to minimize them.
In the data space, we’re seeing the rise of new approaches to address these risks, which we’ll explore in this cross-post with
.Storage Escape Strategy
S3 is becoming the cornerstone of the data industry.
Data warehouses, streaming services, event stores, transactional databases—many new data infra systems now leverage S3 as their storage layer.
For that price, getting automatic replication and such availability/durability makes it almost a no-brainer today.

What’s even more interesting is that its API is becoming the new standard for interacting with blob storage.
Many alternative clouds propose storage with an S3 API.


Even open-source alternatives like MinIO, which allows you to run your blob storage, have an S3-compatible API.

Choosing a blob storage solution with an S3-compatible API, whether from AWS, another cloud provider, or your setup, is a smart move for the future.
Code rewrites would be minimal during migration, and costs would likely be limited to data transfer fees.
Storage Format Escape Strategy
Once your data is stored with an S3 API, the next challenge is to query and transform it efficiently.
Traditionally, compute engines need to copy the data into their system before they can query it.
This additional duplication is a source of risk: once data is inside, there's almost no alternative to using the provider's engine.
This is where Open Table Formats (Delta, Hudi, Iceberg) come into play. They allow you to control the storage part of the analytic engine yourself.
Instead of duplicating the data, you store it yourself and offer access to engine(s).

This is a huge step forward in risk mitigation: you can switch providers without having to (re-) duplicate the data.
The last proprietary blocker is the catalog.
If a provider manages your catalog, they can block write access to your data via external engines.
The recent release of Polaris has given hope for a catalog with full read/write access for any engine.
While the project is still young, and not all locks are open, it's only a matter of time. Within a few months, we'll likely reach a point where catalogs are fully open and supported everywhere.

Query Language Escape Strategy
How do you operate in the data warehouse?
Through SQL, right? Actually, it’s not SQL. It’s your vendor’s SQL.
For fun, we gave Claude AI the Snowflake and Databrick SQL references and asked the following:
“Help me analyze and visualize the difference in SQL syntax between Snowflake and Databricks.”
Here is what came out (take with caution):

Recent progress has been made in providing new “meta” APIs supporting various backends (execution engines). There are many new players in that field, but let’s focus on two of them: Ibis and Malloy!
Ibis
Ibis provides a standard API for data manipulation in Python or SQL:

You can connect to any supported backend without modifying your code.
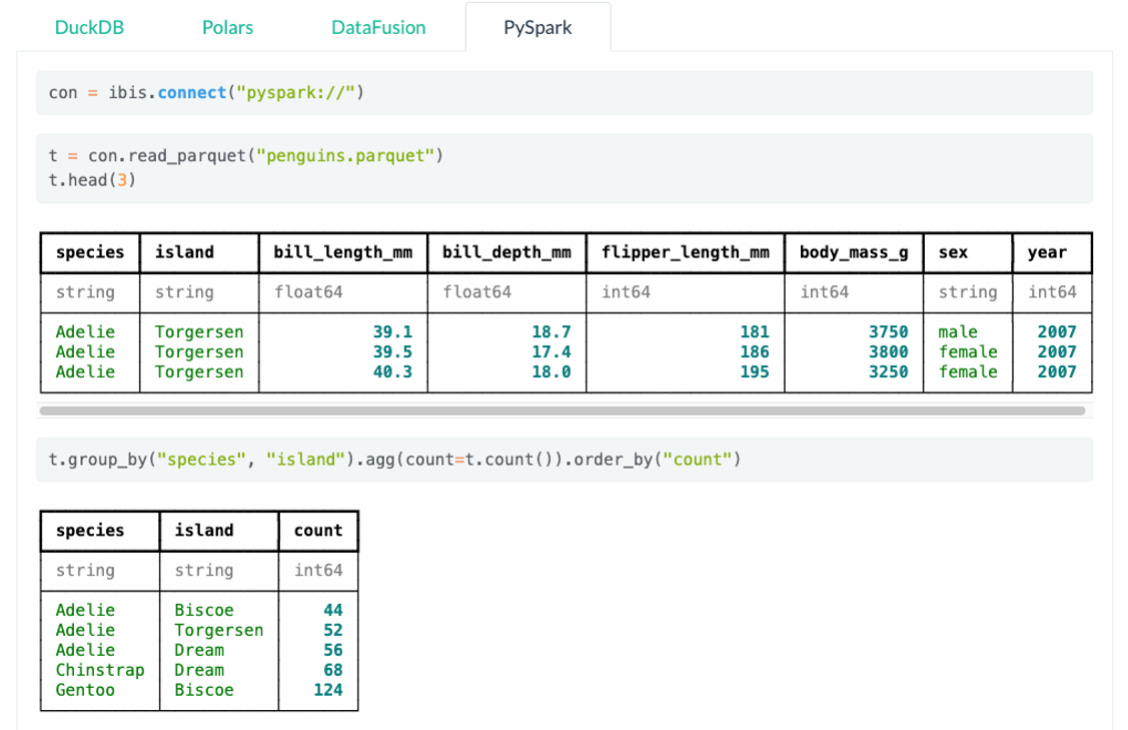

Ibis’ main target is data engineering tasks, where SQL is sometimes limiting or not made for the job.
Malloy
Analytics often implies using lots of convoluted queries that are hard to debug and maintain.
This is where Malloy can help.
It's a new language designed by ex-Looker team members that simplifies data querying:
Nesting
In Malloy, you can use a dedicated operation to nest results for a query.
Check out the example below to get a feel:

Semantic Layer
You can declare your dimensions and measures for proper modeling. This way, your computation elements are explicit and can be reused easily between models and analyses.

source: airports is duckdb.table('../data/airports.parquet') extend {
dimension: elevation_in_meters is elevation * 0.3048
dimension: state_and_county is concat(state,' - ', county)
measure: airport_count is count()
measure: avg_elevation_in_meters is elevation_in_meters.avg()
}
run: airports -> {
limit: 10
where: fac_type = 'HELIPORT'
group_by: state
aggregate:
airport_count // <-- declared in source
avg_elevation_in_meters // <-- declared in source
}Malloy is still new, but it’s promising as it continues to add features and support for more systems, including BigQuery, Snowflake, PostgreSQL, DuckDB, Trino, and Presto.
The “meta” APIs mentioned above promise an exciting vision: write your workflow once and run it anywhere.
This is interesting regarding lock-in, especially if you’ve ever faced the hassle of database migration and had to rewrite all your queries.
However, it’s not without its challenges: compatibility isn’t perfect (Ibis compatibility matrix), and there may be statements you need that the library doesn’t yet support.
In the end, users must weigh their options: stick with a vendor’s syntax, which can be costly to switch away from, or use an open-source library that may have some gaps.
Cloud espace strategy?
S3 API, open table formats, meta SQL APIs: in the picture we've painted, data interfaces are becoming standardized and interoperable, thus limiting lock-in risk.
But can we go one step further and build cloud escape strategies?
A new movement is rising toward self-hosting:


Cloud excels at scaling but is too expensive for provisioned resources.
On-premise is great for provisioned resources but bad at scaling.
An ideal approach would be to self-host predictable workflows while leveraging serverless infrastructure to absorb compute peaks.
Ultimately, data and infra have the same problem: one tool will never serve all use cases.
Escaping lock-in isn’t about avoiding the orangutan; it’s probably more about figuring out how to frame it properly and make it work within your existing zoo.

Thanks for reading,
Ben & Ju

I would be grateful if you could help me to improve this newsletter. Don’t hesitate to share with me what you liked/disliked and the topic you would like to be tackled.
P.S. You can reply to this email; it will get to me.
 | A guest post by
|
This is amazing 👍🙌
This is an excellent article. Thanks, Ju & Ben, for this contribution to the data community.